 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenuReasoning: A Reasoning-Centric Dataset and Benchmark for Long-Tail Autonomous Driving
May 29, 2026Reasoning is essential for autonomous driving (AD) in long-tail scenarios, where vehicles must apply commonsense knowledge, understand spatial relations, infer agent interactions, and make safe decisions. However, existing AD datasets and benchmarks mainly target perception, prediction, or planning, and provide limited supervision for reasoning over realistic long-tail driving scenes. We introduce nuReasoning, a large-scale real-world dataset and benchmark for reasoning-centric AD. Following the lineage of nuScenes and nuPlan, nuReasoning advances real-world AD datasets and benchmarks toward reasoning in long-tail driving scenarios. The dataset contains 20,000 clips, each 20 seconds long, collected across multiple cities, with synchronized multi-camera images, LiDAR data, HD maps, object annotations, and human-verified reasoning annotations spanning Spatial Reasoning, Decision Reasoning, and Counterfactual Reasoning. Unlike prior datasets that focus primarily on visual question answering, nuReasoning supports both reasoning evaluation and planning evaluation, enabling a direct study of how reasoning supervision affects driving performance. Experiments show that fine-tuning VLMs on nuReasoning substantially improves driving-specific question answering, while incorporating reasoning supervision into VLA training improves planning performance even when textual reasoning outputs are disabled at inference time. These results establish nuReasoning as a foundation for evaluating and improving robust, interpretable, reasoning-driven AD systems in realistic long-tail settings.
ConFixGS: Learning to Fix Feedforward 3D Gaussian Splatting with Confidence-Aware Diffusion Priors in Driving Scenes
May 10, 2026Feedforward 3D Gaussian Splatting (3DGS) often struggles in trajectory-based sparse-view driving scenes. Existing Gaussian repair methods mainly target optimization-based 3DGS, while diffusion-based repair is typically restricted to iterative refinement near observed viewpoints, leaving feedforward 3DGS repair underexplored. We propose ConFixGS, a plug-and-play method that learns to fix feedforward 3DGS with confidence-aware diffusion priors. Starting from a pretrained feedforward model, ConFixGS generates diffusion-enhanced local pseudo-targets and validates them through reprojection-based cross-checking against support views. The resulting dense confidence maps guide refinement, enhancing reliable details while suppressing hallucinated or inconsistent evidence. On Waymo, nuScenes, and KITTI, ConFixGS improves challenging novel view synthesis, with PSNR gains of up to 3.68 dB and FID reduced by nearly half. Our results highlight confidence-aware fusion of generative priors and support-view consistency as a key principle for robust feedforward 3D driving scene reconstruction.
TurboTrain: Towards Efficient and Balanced Multi-Task Learning for Multi-Agent Perception and Prediction
Aug 06, 2025End-to-end training of multi-agent systems offers significant advantages in improving multi-task performance. However, training such models remains challenging and requires extensive manual design and monitoring. In this work, we introduce TurboTrain, a novel and efficient training framework for multi-agent perception and prediction. TurboTrain comprises two key components: a multi-agent spatiotemporal pretraining scheme based on masked reconstruction learning and a balanced multi-task learning strategy based on gradient conflict suppression. By streamlining the training process, our framework eliminates the need for manually designing and tuning complex multi-stage training pipelines, substantially reducing training time and improving performance. We evaluate TurboTrain on a real-world cooperative driving dataset, V2XPnP-Seq, and demonstrate that it further improves the performance of state-of-the-art multi-agent perception and prediction models. Our results highlight that pretraining effectively captures spatiotemporal multi-agent features and significantly benefits downstream tasks. Moreover, the proposed balanced multi-task learning strategy enhances detection and prediction.
AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
Jun 16, 2025Recent advancements in Vision-Language-Action (VLA) models have shown promise for end-to-end autonomous driving by leveraging world knowledge and reasoning capabilities. However, current VLA models often struggle with physically infeasible action outputs, complex model structures, or unnecessarily long reasoning. In this paper, we propose AutoVLA, a novel VLA model that unifies reasoning and action generation within a single autoregressive generation model for end-to-end autonomous driving. AutoVLA performs semantic reasoning and trajectory planning directly from raw visual inputs and language instructions. We tokenize continuous trajectories into discrete, feasible actions, enabling direct integration into the language model. For training, we employ supervised fine-tuning to equip the model with dual thinking modes: fast thinking (trajectory-only) and slow thinking (enhanced with chain-of-thought reasoning). To further enhance planning performance and efficiency, we introduce a reinforcement fine-tuning method based on Group Relative Policy Optimization (GRPO), reducing unnecessary reasoning in straightforward scenarios. Extensive experiments across real-world and simulated datasets and benchmarks, including nuPlan, nuScenes, Waymo, and CARLA, demonstrate the competitive performance of AutoVLA in both open-loop and closed-loop settings. Qualitative results showcase the adaptive reasoning and accurate planning capabilities of AutoVLA in diverse scenarios.
V2X-ReaLO: An Open Online Framework and Dataset for Cooperative Perception in Reality
Mar 13, 2025Cooperative perception enabled by Vehicle-to-Everything (V2X) communication holds significant promise for enhancing the perception capabilities of autonomous vehicles, allowing them to overcome occlusions and extend their field of view. However, existing research predominantly relies on simulated environments or static datasets, leaving the feasibility and effectiveness of V2X cooperative perception especially for intermediate fusion in real-world scenarios largely unexplored. In this work, we introduce V2X-ReaLO, an open online cooperative perception framework deployed on real vehicles and smart infrastructure that integrates early, late, and intermediate fusion methods within a unified pipeline and provides the first practical demonstration of online intermediate fusion's feasibility and performance under genuine real-world conditions. Additionally, we present an open benchmark dataset specifically designed to assess the performance of online cooperative perception systems. This new dataset extends V2X-Real dataset to dynamic, synchronized ROS bags and provides 25,028 test frames with 6,850 annotated key frames in challenging urban scenarios. By enabling real-time assessments of perception accuracy and communication lantency under dynamic conditions, V2X-ReaLO sets a new benchmark for advancing and optimizing cooperative perception systems in real-world applications. The codes and datasets will be released to further advance the field.
V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction
Dec 02, 2024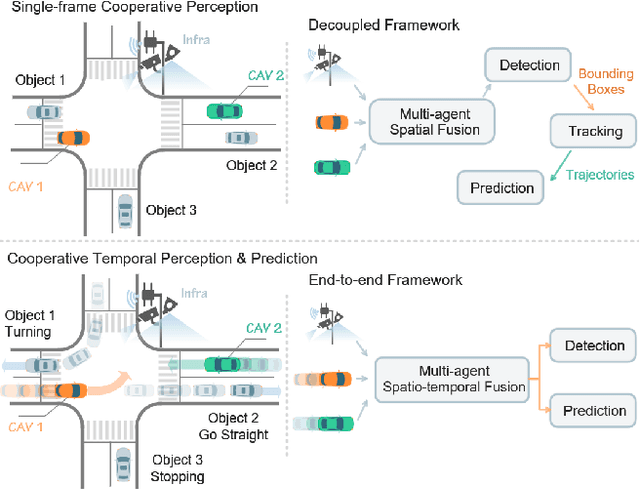
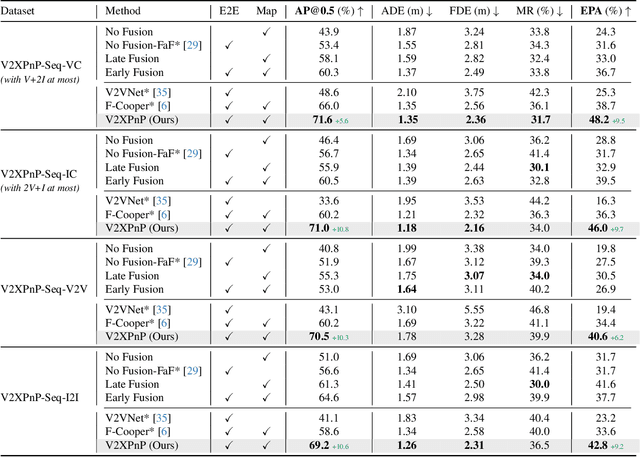
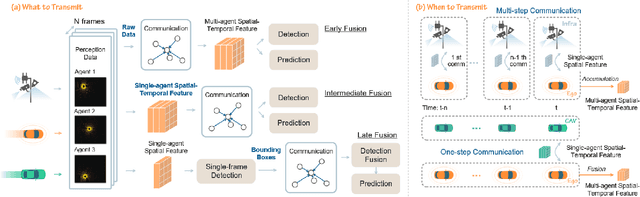
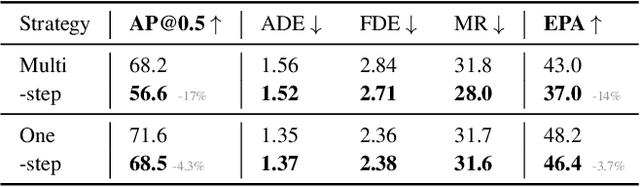
Vehicle-to-everything (V2X) technologies offer a promising paradigm to mitigate the limitations of constrained observability in single-vehicle systems. Prior work primarily focuses on single-frame cooperative perception, which fuses agents' information across different spatial locations but ignores temporal cues and temporal tasks (e.g., temporal perception and prediction). In this paper, we focus on temporal perception and prediction tasks in V2X scenarios and design one-step and multi-step communication strategies (when to transmit) as well as examine their integration with three fusion strategies - early, late, and intermediate (what to transmit), providing comprehensive benchmarks with various fusion models (how to fuse). Furthermore, we propose V2XPnP, a novel intermediate fusion framework within one-step communication for end-to-end perception and prediction. Our framework employs a unified Transformer-based architecture to effectively model complex spatiotemporal relationships across temporal per-frame, spatial per-agent, and high-definition map. Moreover, we introduce the V2XPnP Sequential Dataset that supports all V2X cooperation modes and addresses the limitations of existing real-world datasets, which are restricted to single-frame or single-mode cooperation. Extensive experiments demonstrate our framework outperforms state-of-the-art methods in both perception and prediction tasks.
Driving with Regulation: Interpretable Decision-Making for Autonomous Vehicles with Retrieval-Augmented Reasoning via LLM
Oct 07, 2024



This work presents an interpretable decision-making framework for autonomous vehicles that integrates traffic regulations, norms, and safety guidelines comprehensively and enables seamless adaptation to different regions. While traditional rule-based methods struggle to incorporate the full scope of traffic rules, we develop a Traffic Regulation Retrieval (TRR) Agent based on Retrieval-Augmented Generation (RAG) to automatically retrieve relevant traffic rules and guidelines from extensive regulation documents and relevant records based on the ego vehicle's situation. Given the semantic complexity of the retrieved rules, we also design a reasoning module powered by a Large Language Model (LLM) to interpret these rules, differentiate between mandatory rules and safety guidelines, and assess actions on legal compliance and safety. Additionally, the reasoning is designed to be interpretable, enhancing both transparency and reliability. The framework demonstrates robust performance on both hypothesized and real-world cases across diverse scenarios, along with the ability to adapt to different regions with ease.