 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Squeeze-and-Excitation Network for Fast Image Deraining
Jun 01, 2020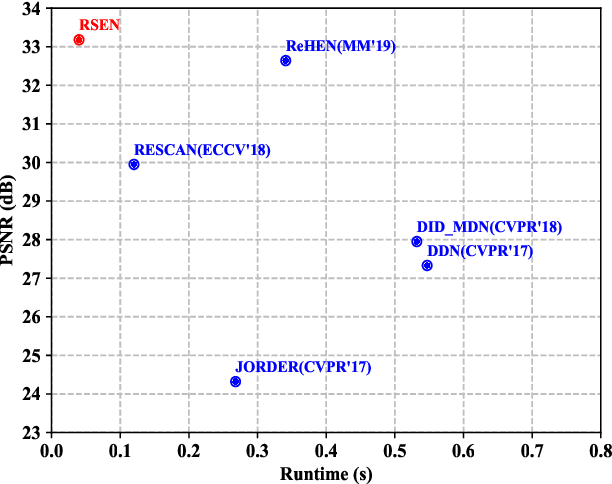
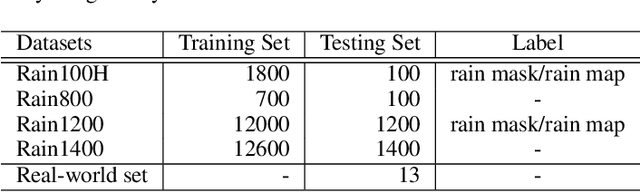
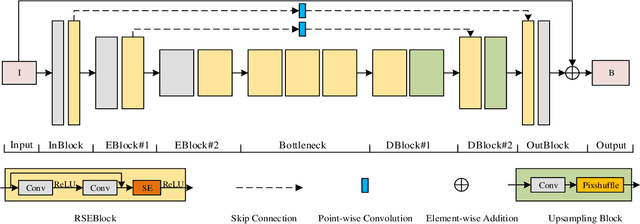
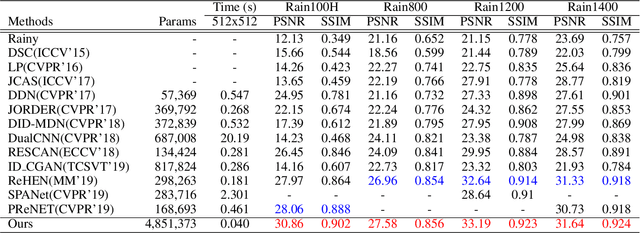
Image deraining is an important image processing task as rain streaks not only severely degrade the visual quality of images but also significantly affect the performance of high-level vision tasks. Traditional methods progressively remove rain streaks via different recurrent neural networks. However, these methods fail to yield plausible rain-free images in an efficient manner. In this paper, we propose a residual squeeze-and-excitation network called RSEN for fast image deraining as well as superior deraining performance compared with state-of-the-art approaches. Specifically, RSEN adopts a lightweight encoder-decoder architecture to conduct rain removal in one stage. Besides, both encoder and decoder adopt a novel residual squeeze-and-excitation block as the core of feature extraction, which contains a residual block for producing hierarchical features, followed by a squeeze-and-excitation block for channel-wisely enhancing the resulted hierarchical features. Experimental results demonstrate that our method can not only considerably reduce the computational complexity but also significantly improve the deraining performance compared with state-of-the-art methods.
Prior-enlightened and Motion-robust Video Deblurring
Mar 26, 2020


Various blur distortions in video will cause negative impact on both human viewing and video-based applications, which makes motion-robust deblurring methods urgently needed. Most existing works have strong dataset dependency and limited generalization ability in handling challenging scenarios, like blur in low contrast or severe motion areas, and non-uniform blur. Therefore, we propose a PRiOr-enlightened and MOTION-robust video deblurring model (PROMOTION) suitable for challenging blurs. On the one hand, we use 3D group convolution to efficiently encode heterogeneous prior information, explicitly enhancing the scenes' perception while mitigating the output's artifacts. On the other hand, we design the priors representing blur distribution, to better handle non-uniform blur in spatio-temporal domain. Besides the classical camera shake caused global blurry, we also prove the generalization for the downstream task suffering from local blur. Extensive experiments demonstrate we can achieve the state-of-the-art performance on well-known REDS and GoPro datasets, and bring machine task gain.
SASL: Saliency-Adaptive Sparsity Learning for Neural Network Acceleration
Mar 12, 2020
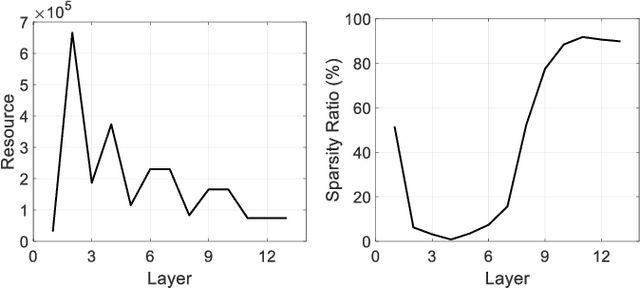

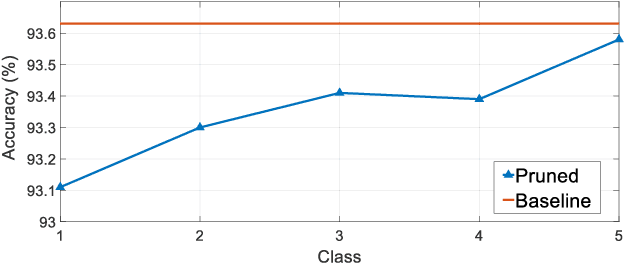
Accelerating the inference speed of CNNs is critical to their deployment in real-world applications. Among all the pruning approaches, those implementing a sparsity learning framework have shown to be effective as they learn and prune the models in an end-to-end data-driven manner. However, these works impose the same sparsity regularization on all filters indiscriminately, which can hardly result in an optimal structure-sparse network. In this paper, we propose a Saliency-Adaptive Sparsity Learning (SASL) approach for further optimization. A novel and effective estimation of each filter, i.e., saliency, is designed, which is measured from two aspects: the importance for the prediction performance and the consumed computational resources. During sparsity learning, the regularization strength is adjusted according to the saliency, so our optimized format can better preserve the prediction performance while zeroing out more computation-heavy filters. The calculation for saliency introduces minimum overhead to the training process, which means our SASL is very efficient. During the pruning phase, in order to optimize the proposed data-dependent criterion, a hard sample mining strategy is utilized, which shows higher effectiveness and efficiency. Extensive experiments demonstrate the superior performance of our method. Notably, on ILSVRC-2012 dataset, our approach can reduce 49.7% FLOPs of ResNet-50 with very negligible 0.39% top-1 and 0.05% top-5 accuracy degradation.
Multiple Human Tracking using Multi-Cues including Primitive Action Features
Sep 18, 2019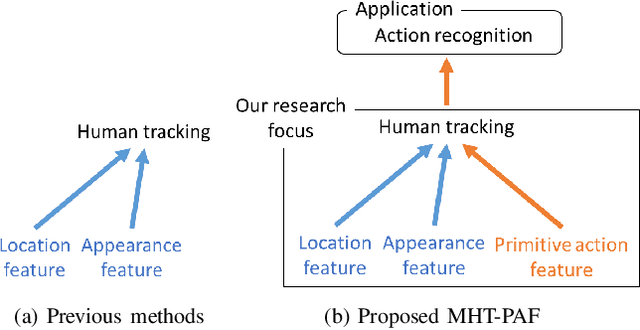
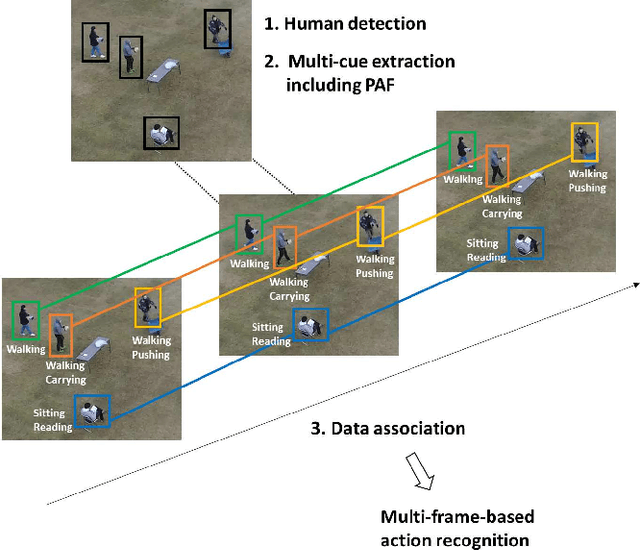
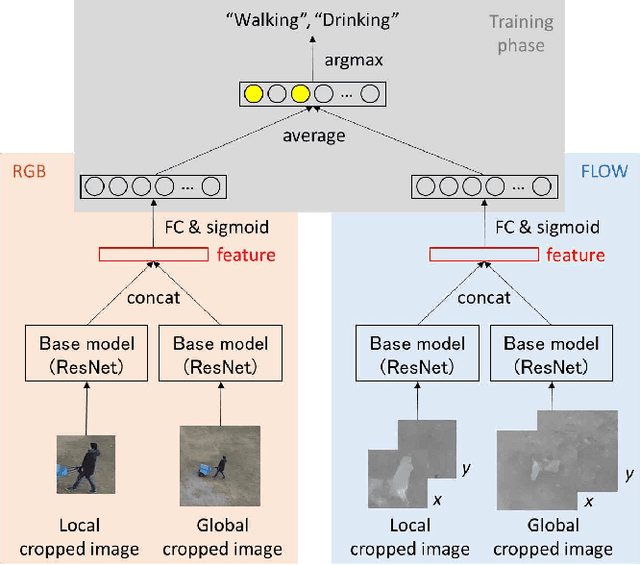
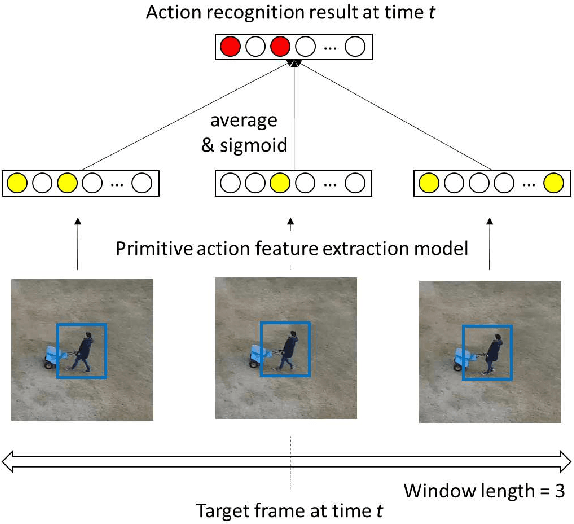
In this paper, we propose a Multiple Human Tracking method using multi-cues including Primitive Action Features (MHT-PAF). MHT-PAF can perform the accurate human tracking in dynamic aerial videos captured by a drone. PAF employs a global context, rich information by multi-label actions, and a middle level feature. The accurate human tracking result using PAF helps multi-frame-based action recognition. In the experiments, we verified the effectiveness of the proposed method using the Okutama-Action dataset. Our code is available online.