 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Post-Training Quantization for Vision Transformer
Mar 25, 2023



Vision transformer emerges as a potential architecture for vision tasks. However, the intense computation and non-negligible delay hinder its application in the real world. As a widespread model compression technique, existing post-training quantization methods still cause severe performance drops. We find the main reasons lie in (1) the existing calibration metric is inaccurate in measuring the quantization influence for extremely low-bit representation, and (2) the existing quantization paradigm is unfriendly to the power-law distribution of Softmax. Based on these observations, we propose a novel Accurate Post-training Quantization framework for Vision Transformer, namely APQ-ViT. We first present a unified Bottom-elimination Blockwise Calibration scheme to optimize the calibration metric to perceive the overall quantization disturbance in a blockwise manner and prioritize the crucial quantization errors that influence more on the final output. Then, we design a Matthew-effect Preserving Quantization for Softmax to maintain the power-law character and keep the function of the attention mechanism. Comprehensive experiments on large-scale classification and detection datasets demonstrate that our APQ-ViT surpasses the existing post-training quantization methods by convincing margins, especially in lower bit-width settings (e.g., averagely up to 5.17% improvement for classification and 24.43% for detection on W4A4). We also highlight that APQ-ViT enjoys versatility and works well on diverse transformer variants.
BiBERT: Accurate Fully Binarized BERT
Mar 12, 2022


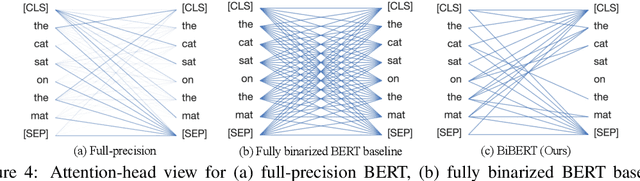
The large pre-trained BERT has achieved remarkable performance on Natural Language Processing (NLP) tasks but is also computation and memory expensive. As one of the powerful compression approaches, binarization extremely reduces the computation and memory consumption by utilizing 1-bit parameters and bitwise operations. Unfortunately, the full binarization of BERT (i.e., 1-bit weight, embedding, and activation) usually suffer a significant performance drop, and there is rare study addressing this problem. In this paper, with the theoretical justification and empirical analysis, we identify that the severe performance drop can be mainly attributed to the information degradation and optimization direction mismatch respectively in the forward and backward propagation, and propose BiBERT, an accurate fully binarized BERT, to eliminate the performance bottlenecks. Specifically, BiBERT introduces an efficient Bi-Attention structure for maximizing representation information statistically and a Direction-Matching Distillation (DMD) scheme to optimize the full binarized BERT accurately. Extensive experiments show that BiBERT outperforms both the straightforward baseline and existing state-of-the-art quantized BERTs with ultra-low bit activations by convincing margins on the NLP benchmark. As the first fully binarized BERT, our method yields impressive 56.3 times and 31.2 times saving on FLOPs and model size, demonstrating the vast advantages and potential of the fully binarized BERT model in real-world resource-constrained scenarios.
Diversifying Sample Generation for Accurate Data-Free Quantization
Mar 04, 2021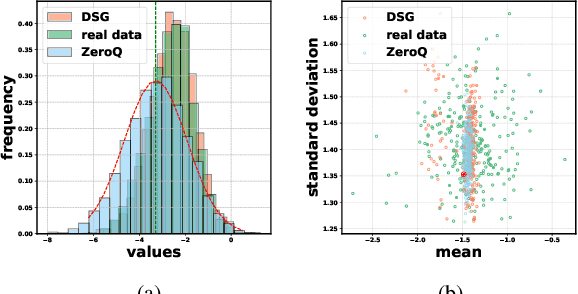

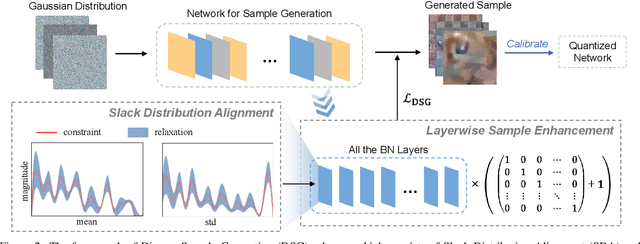
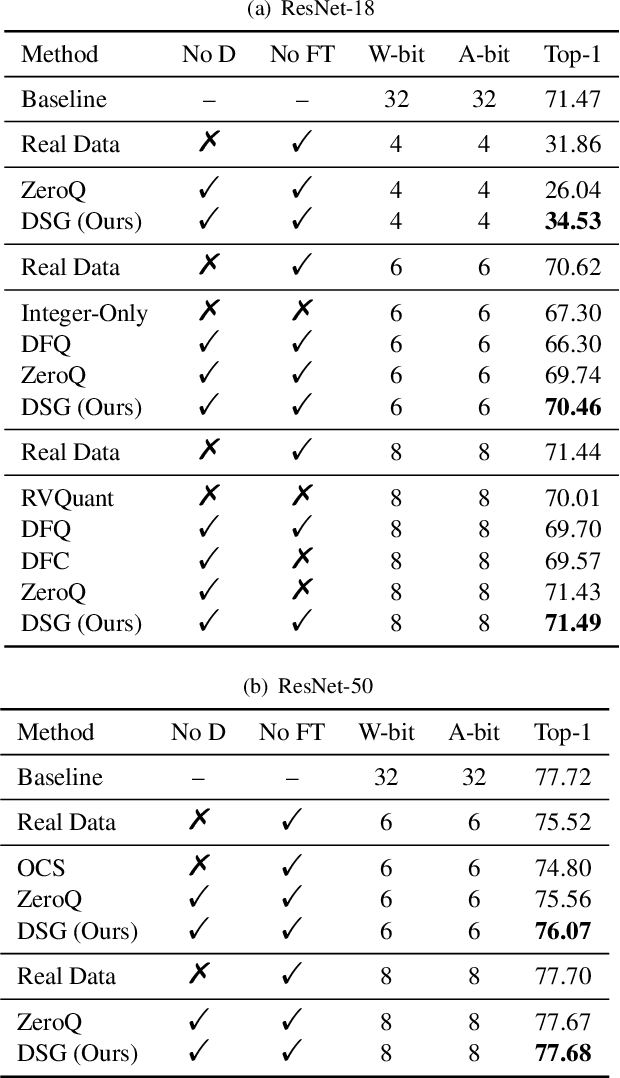
Quantization has emerged as one of the most prevalent approaches to compress and accelerate neural networks. Recently, data-free quantization has been widely studied as a practical and promising solution. It synthesizes data for calibrating the quantized model according to the batch normalization (BN) statistics of FP32 ones and significantly relieves the heavy dependency on real training data in traditional quantization methods. Unfortunately, we find that in practice, the synthetic data identically constrained by BN statistics suffers serious homogenization at both distribution level and sample level and further causes a significant performance drop of the quantized model. We propose Diverse Sample Generation (DSG) scheme to mitigate the adverse effects caused by homogenization. Specifically, we slack the alignment of feature statistics in the BN layer to relax the constraint at the distribution level and design a layerwise enhancement to reinforce specific layers for different data samples. Our DSG scheme is versatile and even able to be applied to the state-of-the-art post-training quantization method like AdaRound. We evaluate the DSG scheme on the large-scale image classification task and consistently obtain significant improvements over various network architectures and quantization methods, especially when quantized to lower bits (e.g., up to 22% improvement on W4A4). Moreover, benefiting from the enhanced diversity, models calibrated by synthetic data perform close to those calibrated by real data and even outperform them on W4A4.