 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention
Paper and Code
Feb 24, 2023
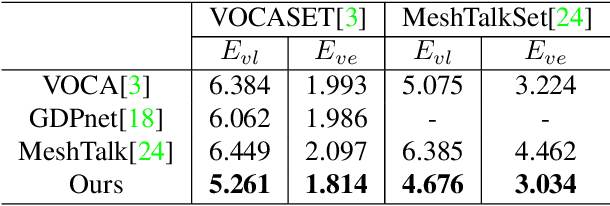

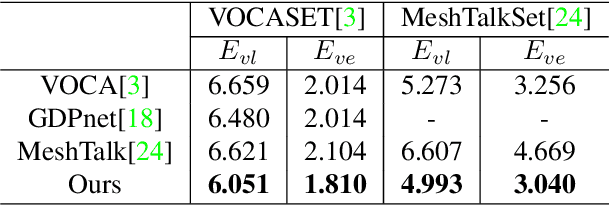
Most of the existing audio-driven 3D facial animation methods suffered from the lack of detailed facial expression and head pose, resulting in unsatisfactory experience of human-robot interaction. In this paper, a novel pose-controllable 3D facial animation synthesis method is proposed by utilizing hierarchical audio-vertex attention. To synthesize real and detailed expression, a hierarchical decomposition strategy is proposed to encode the audio signal into both a global latent feature and a local vertex-wise control feature. Then the local and global audio features combined with vertex spatial features are used to predict the final consistent facial animation via a graph convolutional neural network by fusing the intrinsic spatial topology structure of the face model and the corresponding semantic feature of the audio. To accomplish pose-controllable animation, we introduce a novel pose attribute augmentation method by utilizing the 2D talking face technique. Experimental results indicate that the proposed method can produce more realistic facial expressions and head posture movements. Qualitative and quantitative experiments show that the proposed method achieves competitive performance against state-of-the-art methods.