 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding
Paper and Code
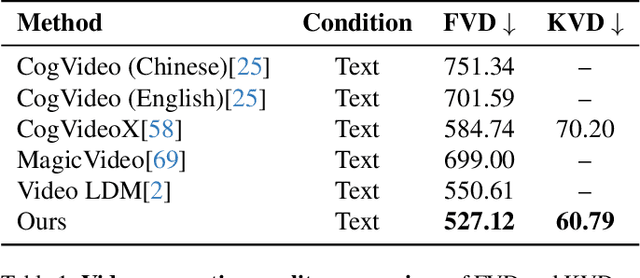
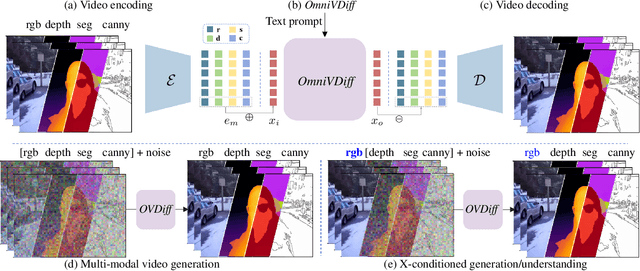
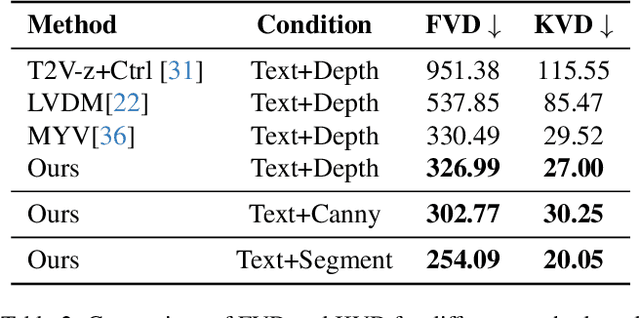

In this paper, we propose a novel framework for controllable video diffusion, OmniVDiff, aiming to synthesize and comprehend multiple video visual content in a single diffusion model. To achieve this, OmniVDiff treats all video visual modalities in the color space to learn a joint distribution, while employing an adaptive control strategy that dynamically adjusts the role of each visual modality during the diffusion process, either as a generation modality or a conditioning modality. This allows flexible manipulation of each modality's role, enabling support for a wide range of tasks. Consequently, our model supports three key functionalities: (1) Text-conditioned video generation: multi-modal visual video sequences (i.e., rgb, depth, canny, segmentaion) are generated based on the text conditions in one diffusion process; (2) Video understanding: OmniVDiff can estimate the depth, canny map, and semantic segmentation across the input rgb frames while ensuring coherence with the rgb input; and (3) X-conditioned video generation: OmniVDiff generates videos conditioned on fine-grained attributes (e.g., depth maps or segmentation maps). By integrating these diverse tasks into a unified video diffusion framework, OmniVDiff enhances the flexibility and scalability for controllable video diffusion, making it an effective tool for a variety of downstream applications, such as video-to-video translation. Extensive experiments demonstrate the effectiveness of our approach, highlighting its potential for various video-related applications.