 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Visual Relationships for High-level Image Understanding
Paper and Code
Feb 01, 2019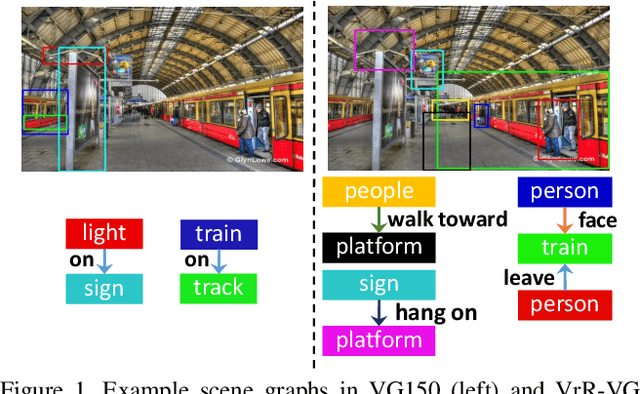
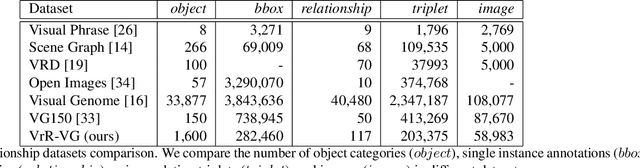
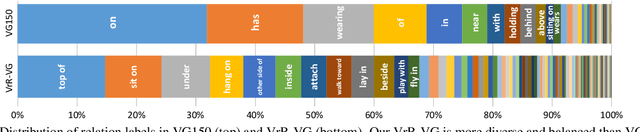
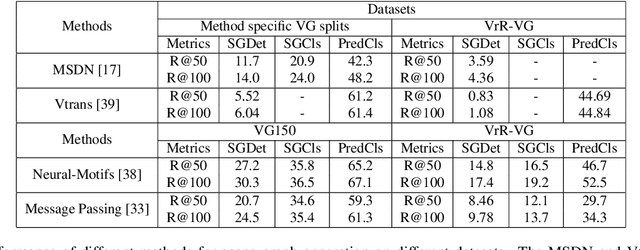
Relationships, as the bond of isolated entities in images, reflect the interaction between objects and lead to a semantic understanding of scenes. Suffering from visually-irrelevant relationships in current scene graph datasets, the utilization of relationships for semantic tasks is difficult. The datasets widely used in scene graph generation tasks are splitted from Visual Genome by label frequency, which even can be well solved by statistical counting. To encourage further development in relationships, we propose a novel method to mine more valuable relationships by automatically filtering out visually-irrelevant relationships. Then, we construct a new scene graph dataset named Visually-Relevant Relationships Dataset (VrR-VG) from Visual Genome. We evaluate several existing methods in scene graph generation in our dataset. The results show the performances degrade significantly compared to the previous dataset and the frequency analysis do not work on our dataset anymore. Moreover, we propose a method to learn feature representations of instances, attributes, and visual relationships jointly from images, then we apply the learned features to image captioning and visual question answering respectively. The improvements on the both tasks demonstrate the efficiency of the features with relation information and the richer semantic information provided in our dataset.