 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Hand 3D Object Reconstruction from a Monocular RGB Video
Dec 27, 2023

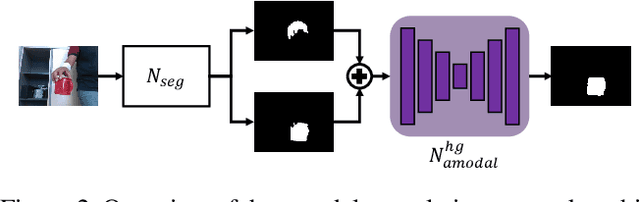

Our work aims to reconstruct a 3D object that is held and rotated by a hand in front of a static RGB camera. Previous methods that use implicit neural representations to recover the geometry of a generic hand-held object from multi-view images achieved compelling results in the visible part of the object. However, these methods falter in accurately capturing the shape within the hand-object contact region due to occlusion. In this paper, we propose a novel method that deals with surface reconstruction under occlusion by incorporating priors of 2D occlusion elucidation and physical contact constraints. For the former, we introduce an object amodal completion network to infer the 2D complete mask of objects under occlusion. To ensure the accuracy and view consistency of the predicted 2D amodal masks, we devise a joint optimization method for both amodal mask refinement and 3D reconstruction. For the latter, we impose penetration and attraction constraints on the local geometry in contact regions. We evaluate our approach on HO3D and HOD datasets and demonstrate that it outperforms the state-of-the-art methods in terms of reconstruction surface quality, with an improvement of $52\%$ on HO3D and $20\%$ on HOD. Project webpage: https://east-j.github.io/ihor.
Pixel-Aligned Non-parametric Hand Mesh Reconstruction
Oct 17, 2022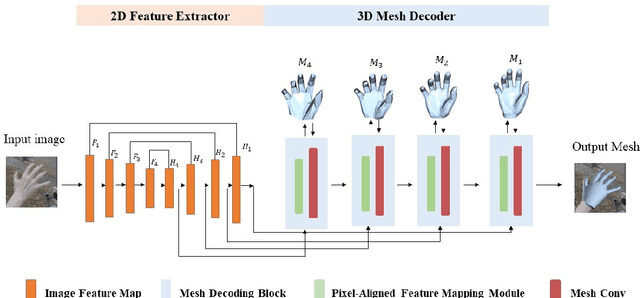
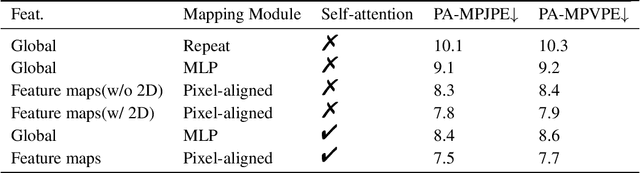
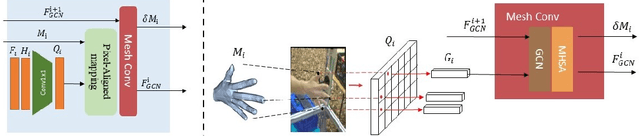

Non-parametric mesh reconstruction has recently shown significant progress in 3D hand and body applications. In these methods, mesh vertices and edges are visible to neural networks, enabling the possibility to establish a direct mapping between 2D image pixels and 3D mesh vertices. In this paper, we seek to establish and exploit this mapping with a simple and compact architecture. The network is designed with these considerations: 1) aggregating both local 2D image features from the encoder and 3D geometric features captured in the mesh decoder; 2) decoding coarse-to-fine meshes along the decoding layers to make the best use of the hierarchical multi-scale information. Specifically, we propose an end-to-end pipeline for hand mesh recovery tasks which consists of three phases: a 2D feature extractor constructing multi-scale feature maps, a feature mapping module transforming local 2D image features to 3D vertex features via 3D-to-2D projection, and a mesh decoder combining the graph convolution and self-attention to reconstruct mesh. The decoder aggregate both local image features in pixels and geometric features in vertices. It also regresses the mesh vertices in a coarse-to-fine manner, which can leverage multi-scale information. By exploiting the local connection and designing the mesh decoder, Our approach achieves state-of-the-art for hand mesh reconstruction on the public FreiHAND dataset.