 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHTDM: Walsh-Hadamard Transform Division Multiplexing for Doubly-Selective Channels
May 14, 2026We propose Walsh-Hadamard Transform Division Multiplexing (WHTDM), a multicarrier waveform that replaces the conventional IFFT/FFT pair in OFDM with a real-valued, unitary Walsh-Hadamard transform (WHT). WHTDM inherits the CP-OFDM transceiver structure while eliminating all complex multiplications from the transform stage, yielding a transmitter with zero real multipliers in the core modulation block. For detection under doubly-selective channels, we adopt a cross-domain memory approximate message passing (CD-MAMP) equalizer that operates on the banded structure of the equivalent WHT-domain channel matrix. Simulation results under the 3GPP TDL-C channel model at 28 GHz demonstrate that WHTDM with CD-MAMP significantly outperforms conventional OFDM 1-tap MMSE at high mobility, achieving over an order of magnitude lower BER at 120 km/h. Among the compared CD-MAMP-equalized new waveforms, WHTDM achieves the best BER performance while maintaining a transmitter complexity 2.5 $\times$ lower than OFDM and completely eliminating complex multipliers from the transform stage, making it well-suited for low-power IoT terminals.
Rmd: Robust Modal Decomposition with Constrained Bandwidth
Oct 27, 2025Modal decomposition techniques, such as Empirical Mode Decomposition (EMD), Variational Mode Decomposition (VMD), and Singular Spectrum Analysis (SSA), have advanced time-frequency signal analysis since the early 21st century. These methods are generally classified into two categories: numerical optimization-based methods (EMD, VMD) and spectral decomposition methods (SSA) that consider the physical meaning of signals. The former can produce spurious modes due to the lack of physical constraints, while the latter is more sensitive to noise and struggles with nonlinear signals. Despite continuous improvements in these methods, a modal decomposition approach that effectively combines the strengths of both categories remains elusive. This paper thus proposes a Robust Modal Decomposition (RMD) method with constrained bandwidth, which preserves the intrinsic structure of the signal by mapping the time series into its trajectory-GRAM matrix in phase space. Moreover, the method incorporates bandwidth constraints during the decomposition process, enhancing noise resistance. Extensive experiments on synthetic and real-world datasets, including millimeter-wave radar echoes, electrocardiogram (ECG), phonocardiogram (PCG), and bearing fault detection data, demonstrate the method's effectiveness and versatility. All code and dataset samples are available on GitHub: https://github.com/Einstein-sworder/RMD.
Intermittent Semi-working Mask: A New Masking Paradigm for LLMs
Aug 01, 2024



Multi-turn dialogues are a key interaction method between humans and Large Language Models (LLMs), as conversations extend over multiple rounds, keeping LLMs' high generation quality and low latency is a challenge. Mainstream LLMs can be grouped into two categories based on masking strategy: causal LLM and prefix LLM. Several works have demonstrated that prefix LLMs tend to outperform causal ones in scenarios that heavily depend on historical context such as multi-turn dialogues or in-context learning, thanks to their bidirectional attention on prefix sequences. However, prefix LLMs have an inherent inefficient training problem in multi-turn dialogue datasets. In addition, the attention mechanism of prefix LLM makes it unable to reuse Key-Value Cache (KV Cache) across dialogue rounds to reduce generation latency. In this paper, we propose a novel masking scheme called Intermittent Semi-working Mask (ISM) to address these problems. Specifically, we apply alternate bidirectional and unidirectional attention on queries and answers in the dialogue history. In this way, ISM is able to maintain the high quality of prefix LLM and low generation latency of causal LLM, simultaneously. Extensive experiments illustrate that our ISM achieves significant performance.
TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Sep 17, 2023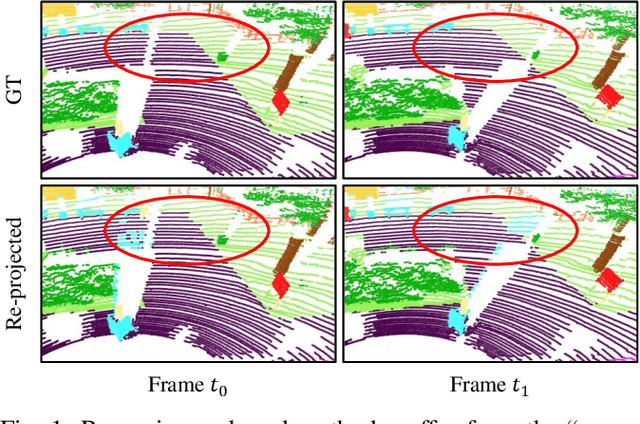



LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. There are different types of methods, such as point-based, range-image-based, polar-based, and hybrid methods. Among these, range-image-based methods are widely used due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20\% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrate that the post-processing technique is generic and can be applied to various networks. We will release our code and models.
Learning Spatial and Temporal Variations for 4D Point Cloud Segmentation
Jul 11, 2022



LiDAR-based 3D scene perception is a fundamental and important task for autonomous driving. Most state-of-the-art methods on LiDAR-based 3D recognition tasks focus on single frame 3D point cloud data, and the temporal information is ignored in those methods. We argue that the temporal information across the frames provides crucial knowledge for 3D scene perceptions, especially in the driving scenario. In this paper, we focus on spatial and temporal variations to better explore the temporal information across the 3D frames. We design a temporal variation-aware interpolation module and a temporal voxel-point refiner to capture the temporal variation in the 4D point cloud. The temporal variation-aware interpolation generates local features from the previous and current frames by capturing spatial coherence and temporal variation information. The temporal voxel-point refiner builds a temporal graph on the 3D point cloud sequences and captures the temporal variation with a graph convolution module. The temporal voxel-point refiner also transforms the coarse voxel-level predictions into fine point-level predictions. With our proposed modules, the new network TVSN achieves state-of-the-art performance on SemanticKITTI and SemantiPOSS. Specifically, our method achieves 52.5\% in mIoU (+5.5% against previous best approaches) on the multiple scan segmentation task on SemanticKITTI, and 63.0% on SemanticPOSS (+2.8% against previous best approaches).
Unsupervised Mismatch Localization in Cross-Modal Sequential Data
May 05, 2022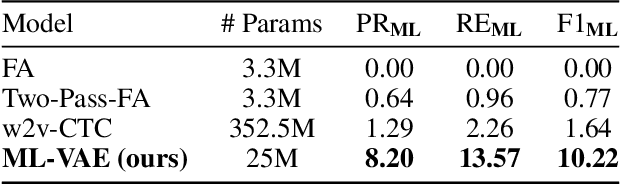


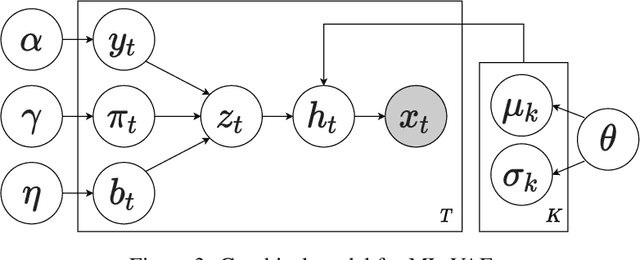
Content mismatch usually occurs when data from one modality is translated to another, e.g. language learners producing mispronunciations (errors in speech) when reading a sentence (target text) aloud. However, most existing alignment algorithms assume the content involved in the two modalities is perfectly matched and thus leading to difficulty in locating such mismatch between speech and text. In this work, we develop an unsupervised learning algorithm that can infer the relationship between content-mismatched cross-modal sequential data, especially for speech-text sequences. More specifically, we propose a hierarchical Bayesian deep learning model, named mismatch localization variational autoencoder (ML-VAE), that decomposes the generative process of the speech into hierarchically structured latent variables, indicating the relationship between the two modalities. Training such a model is very challenging due to the discrete latent variables with complex dependencies involved. We propose a novel and effective training procedure which estimates the hard assignments of the discrete latent variables over a specifically designed lattice and updates the parameters of neural networks alternatively. Our experimental results show that ML-VAE successfully locates the mismatch between text and speech, without the need for human annotations for model training.
FoodAI: Food Image Recognition via Deep Learning for Smart Food Logging
Sep 26, 2019



An important aspect of health monitoring is effective logging of food consumption. This can help management of diet-related diseases like obesity, diabetes, and even cardiovascular diseases. Moreover, food logging can help fitness enthusiasts, and people who wanting to achieve a target weight. However, food-logging is cumbersome, and requires not only taking additional effort to note down the food item consumed regularly, but also sufficient knowledge of the food item consumed (which is difficult due to the availability of a wide variety of cuisines). With increasing reliance on smart devices, we exploit the convenience offered through the use of smart phones and propose a smart-food logging system: FoodAI, which offers state-of-the-art deep-learning based image recognition capabilities. FoodAI has been developed in Singapore and is particularly focused on food items commonly consumed in Singapore. FoodAI models were trained on a corpus of 400,000 food images from 756 different classes. In this paper we present extensive analysis and insights into the development of this system. FoodAI has been deployed as an API service and is one of the components powering Healthy 365, a mobile app developed by Singapore's Heath Promotion Board. We have over 100 registered organizations (universities, companies, start-ups) subscribing to this service and actively receive several API requests a day. FoodAI has made food logging convenient, aiding smart consumption and a healthy lifestyle.