 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-Drive: Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting
Mar 10, 2025
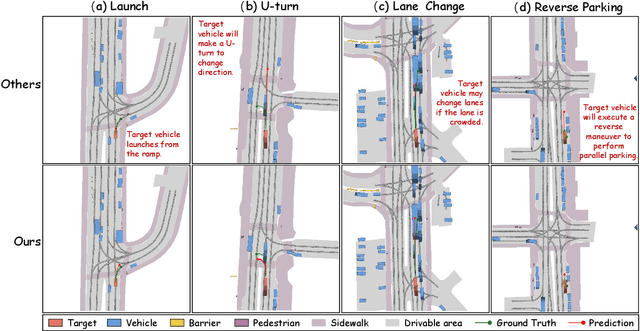
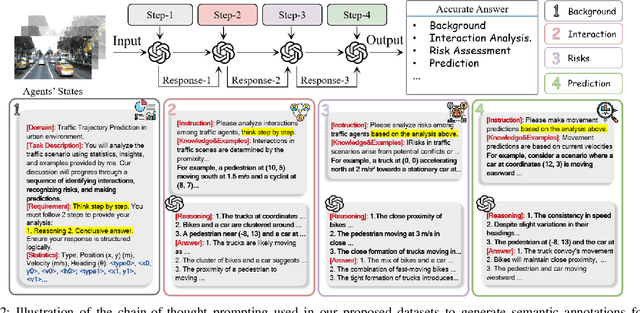

Accurate motion forecasting is crucial for safe autonomous driving (AD). This study proposes CoT-Drive, a novel approach that enhances motion forecasting by leveraging large language models (LLMs) and a chain-of-thought (CoT) prompting method. We introduce a teacher-student knowledge distillation strategy to effectively transfer LLMs' advanced scene understanding capabilities to lightweight language models (LMs), ensuring that CoT-Drive operates in real-time on edge devices while maintaining comprehensive scene understanding and generalization capabilities. By leveraging CoT prompting techniques for LLMs without additional training, CoT-Drive generates semantic annotations that significantly improve the understanding of complex traffic environments, thereby boosting the accuracy and robustness of predictions. Additionally, we present two new scene description datasets, Highway-Text and Urban-Text, designed for fine-tuning lightweight LMs to generate context-specific semantic annotations. Comprehensive evaluations of five real-world datasets demonstrate that CoT-Drive outperforms existing models, highlighting its effectiveness and efficiency in handling complex traffic scenarios. Overall, this study is the first to consider the practical application of LLMs in this field. It pioneers the training and use of a lightweight LLM surrogate for motion forecasting, setting a new benchmark and showcasing the potential of integrating LLMs into AD systems.
Unsupervised Mismatch Localization in Cross-Modal Sequential Data
May 05, 2022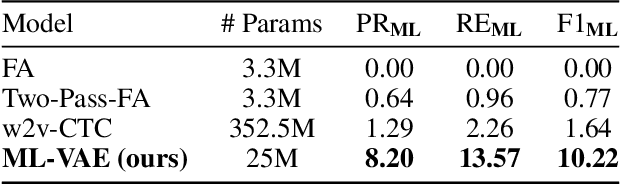


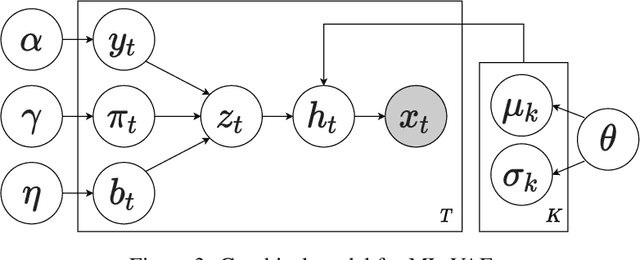
Content mismatch usually occurs when data from one modality is translated to another, e.g. language learners producing mispronunciations (errors in speech) when reading a sentence (target text) aloud. However, most existing alignment algorithms assume the content involved in the two modalities is perfectly matched and thus leading to difficulty in locating such mismatch between speech and text. In this work, we develop an unsupervised learning algorithm that can infer the relationship between content-mismatched cross-modal sequential data, especially for speech-text sequences. More specifically, we propose a hierarchical Bayesian deep learning model, named mismatch localization variational autoencoder (ML-VAE), that decomposes the generative process of the speech into hierarchically structured latent variables, indicating the relationship between the two modalities. Training such a model is very challenging due to the discrete latent variables with complex dependencies involved. We propose a novel and effective training procedure which estimates the hard assignments of the discrete latent variables over a specifically designed lattice and updates the parameters of neural networks alternatively. Our experimental results show that ML-VAE successfully locates the mismatch between text and speech, without the need for human annotations for model training.
A Comparative Review of Recent Few-Shot Object Detection Algorithms
Oct 30, 2021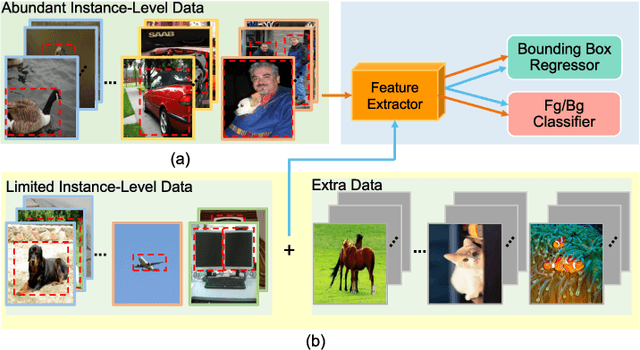
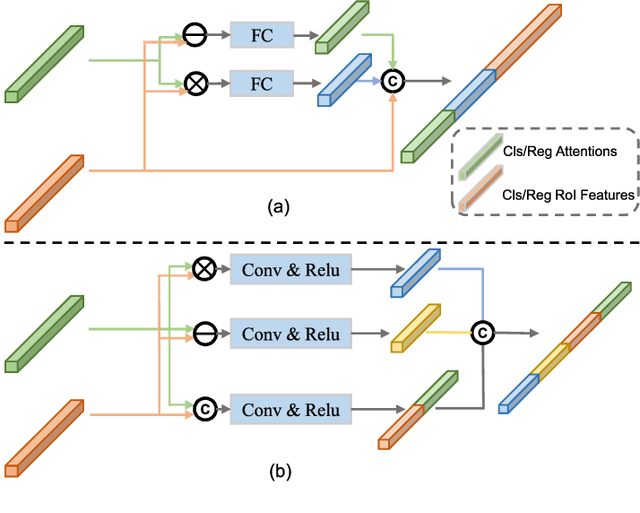
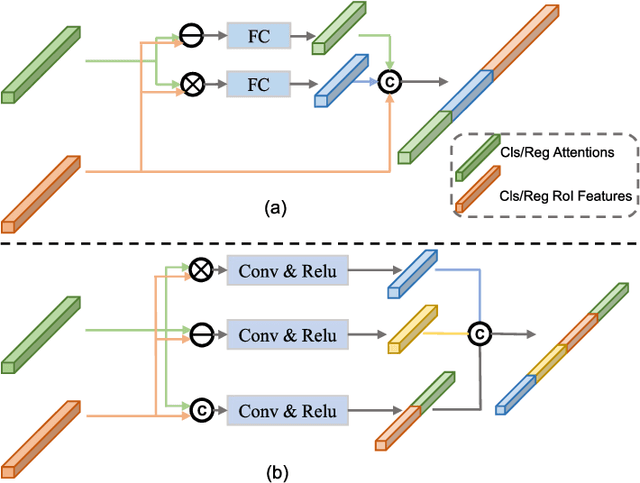
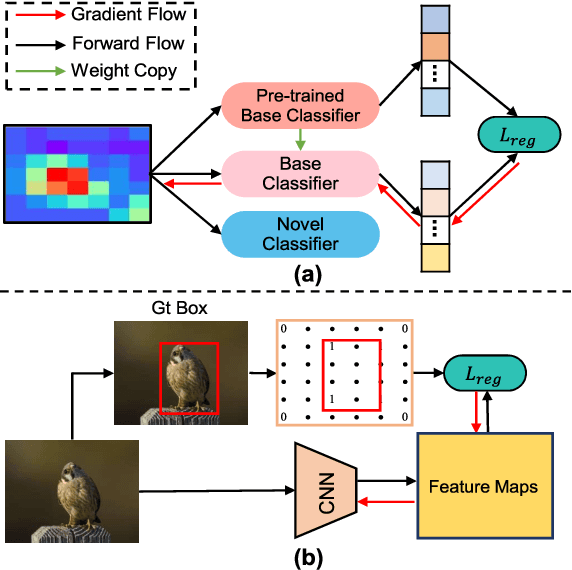
Few-shot object detection, learning to adapt to the novel classes with a few labeled data, is an imperative and long-lasting problem due to the inherent long-tail distribution of real-world data and the urgent demands to cut costs of data collection and annotation. Recently, some studies have explored how to use implicit cues in extra datasets without target-domain supervision to help few-shot detectors refine robust task notions. This survey provides a comprehensive overview from current classic and latest achievements for few-shot object detection to future research expectations from manifold perspectives. In particular, we first propose a data-based taxonomy of the training data and the form of corresponding supervision which are accessed during the training stage. Following this taxonomy, we present a significant review of the formal definition, main challenges, benchmark datasets, evaluation metrics, and learning strategies. In addition, we present a detailed investigation of how to interplay the object detection methods to develop this issue systematically. Finally, we conclude with the current status of few-shot object detection, along with potential research directions for this field.