 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Sep 17, 2023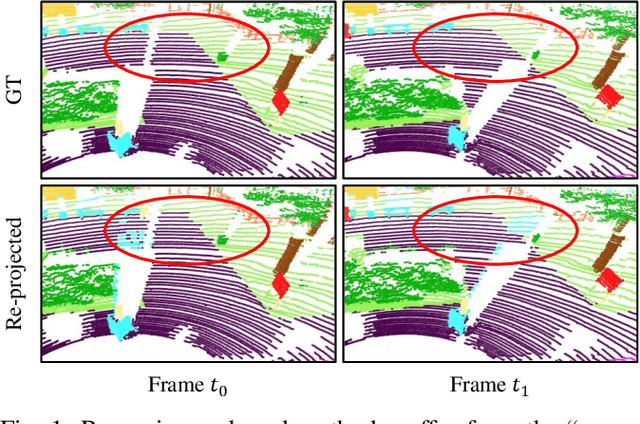



LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. There are different types of methods, such as point-based, range-image-based, polar-based, and hybrid methods. Among these, range-image-based methods are widely used due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20\% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrate that the post-processing technique is generic and can be applied to various networks. We will release our code and models.