 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Aware Monocular Semantic Scene Completion with State Space Models
Mar 09, 2025


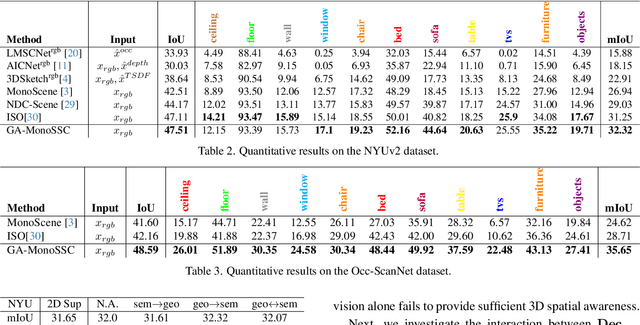
Monocular Semantic Scene Completion (MonoSSC) reconstructs and interprets 3D environments from a single image, enabling diverse real-world applications. However, existing methods are often constrained by the local receptive field of Convolutional Neural Networks (CNNs), making it challenging to handle the non-uniform distribution of projected points (Fig. \ref{fig:perspective}) and effectively reconstruct missing information caused by the 3D-to-2D projection. In this work, we introduce GA-MonoSSC, a hybrid architecture for MonoSSC that effectively captures global context in both the 2D image domain and 3D space. Specifically, we propose a Dual-Head Multi-Modality Encoder, which leverages a Transformer architecture to capture spatial relationships across all features in the 2D image domain, enabling more comprehensive 2D feature extraction. Additionally, we introduce the Frustum Mamba Decoder, built on the State Space Model (SSM), to efficiently capture long-range dependencies in 3D space. Furthermore, we propose a frustum reordering strategy within the Frustum Mamba Decoder to mitigate feature discontinuities in the reordered voxel sequence, ensuring better alignment with the scan mechanism of the State Space Model (SSM) for improved 3D representation learning. We conduct extensive experiments on the widely used Occ-ScanNet and NYUv2 datasets, demonstrating that our proposed method achieves state-of-the-art performance, validating its effectiveness. The code will be released upon acceptance.
On-the-fly Point Feature Representation for Point Clouds Analysis
Jul 31, 2024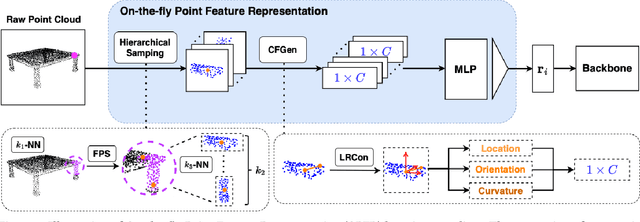



Point cloud analysis is challenging due to its unique characteristics of unorderness, sparsity and irregularity. Prior works attempt to capture local relationships by convolution operations or attention mechanisms, exploiting geometric information from coordinates implicitly. These methods, however, are insufficient to describe the explicit local geometry, e.g., curvature and orientation. In this paper, we propose On-the-fly Point Feature Representation (OPFR), which captures abundant geometric information explicitly through Curve Feature Generator module. This is inspired by Point Feature Histogram (PFH) from computer vision community. However, the utilization of vanilla PFH encounters great difficulties when applied to large datasets and dense point clouds, as it demands considerable time for feature generation. In contrast, we introduce the Local Reference Constructor module, which approximates the local coordinate systems based on triangle sets. Owing to this, our OPFR only requires extra 1.56ms for inference (65x faster than vanilla PFH) and 0.012M more parameters, and it can serve as a versatile plug-and-play module for various backbones, particularly MLP-based and Transformer-based backbones examined in this study. Additionally, we introduce the novel Hierarchical Sampling module aimed at enhancing the quality of triangle sets, thereby ensuring robustness of the obtained geometric features. Our proposed method improves overall accuracy (OA) on ModelNet40 from 90.7% to 94.5% (+3.8%) for classification, and OA on S3DIS Area-5 from 86.4% to 90.0% (+3.6%) for semantic segmentation, respectively, building upon PointNet++ backbone. When integrated with Point Transformer backbone, we achieve state-of-the-art results on both tasks: 94.8% OA on ModelNet40 and 91.7% OA on S3DIS Area-5.
A Timely Survey on Vision Transformer for Deepfake Detection
May 14, 2024



In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
A Deep Framework for Bone Age Assessment based on Finger Joint Localization
May 07, 2019
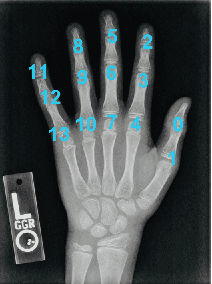
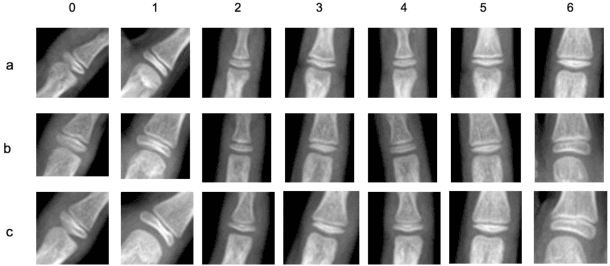

Bone age assessment is an important clinical trial to measure skeletal child maturity and diagnose of growth disorders. Conventional approaches such as the Tanner-Whitehouse (TW) and Greulich and Pyle (GP) may not perform well due to their large inter-observer and intra-observer variations. In this paper, we propose a finger joint localization strategy to filter out most non-informative parts of images. When combining with the conventional full image-based deep network, we observe a much-improved performance. % Our approach utilizes full hand and specific joints images for skeletal maturity prediction. In this study, we applied powerful deep neural network and explored a process in the forecast of skeletal bone age with the specifically combine joints images to increase the performance accuracy compared with the whole hand images.