 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Definition Map Mapping and Update: A General Overview and Future Directions
Sep 15, 2024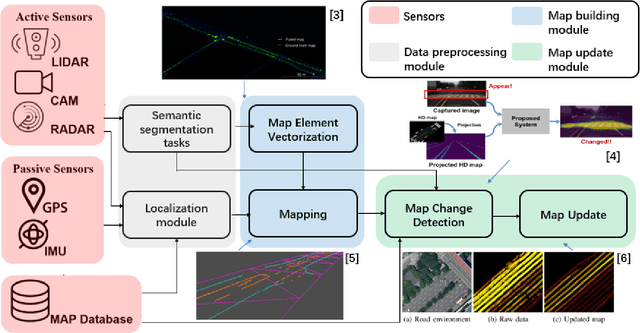
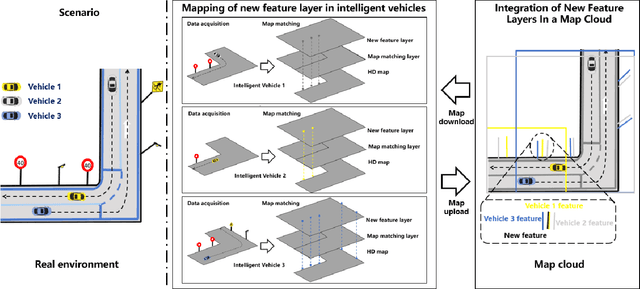
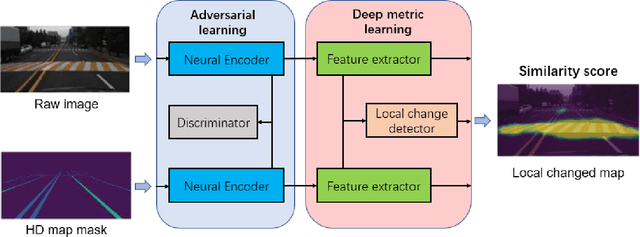
Along with the rapid growth of autonomous vehicles (AVs), more and more demands are required for environment perception technology. Among others, HD mapping has become one of the more prominent roles in helping the vehicle realize essential tasks such as localization and path planning. While increasing research efforts have been directed toward HD Map development. However, a comprehensive overview of the overall HD map mapping and update framework is still lacking. This article introduces the development and current state of the algorithm involved in creating HD map mapping and its maintenance. As part of this study, the primary data preprocessing approach of processing raw data to information ready to feed for mapping and update purposes, semantic segmentation, and localization are also briefly reviewed. Moreover, the map taxonomy, ontology, and quality assessment are extensively discussed, the map data's general representation method is presented, and the mapping algorithm ranging from SLAM to transformers learning-based approaches are also discussed. The development of the HD map update algorithm, from change detection to the update methods, is also presented. Finally, the authors discuss possible future developments and the remaining challenges in HD map mapping and update technology. This paper simultaneously serves as a position paper and tutorial to those new to HD map mapping and update domains.
Bridging the View Disparity of Radar and Camera Features for Multi-modal Fusion 3D Object Detection
Aug 25, 2022
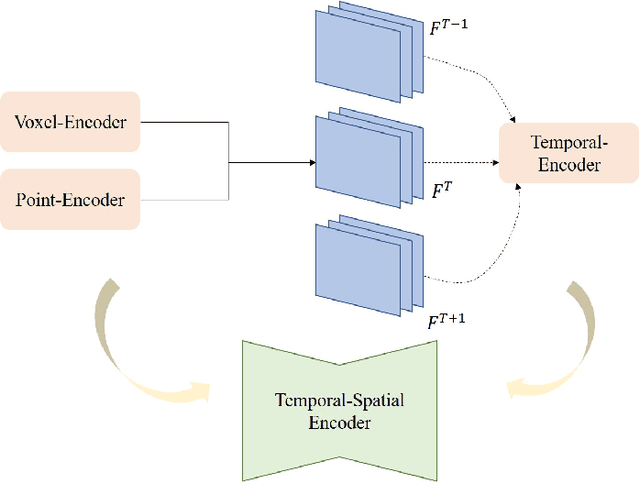

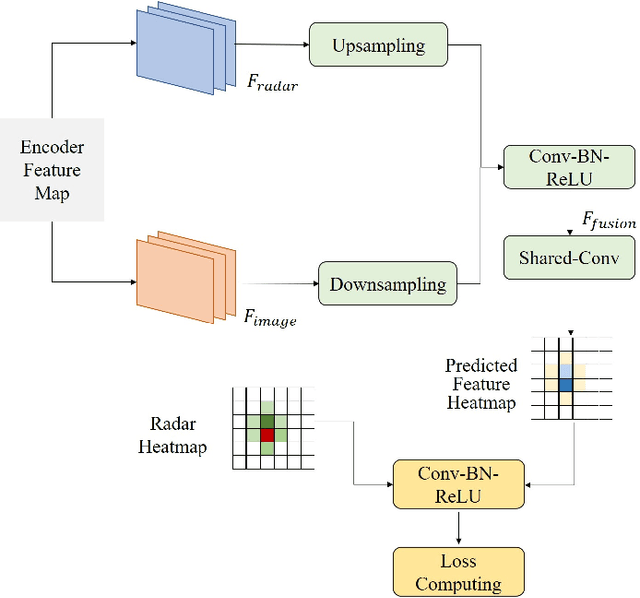
Environmental perception with multi-modal fusion of radar and camera is crucial in autonomous driving to increase the accuracy, completeness, and robustness. This paper focuses on how to utilize millimeter-wave (MMW) radar and camera sensor fusion for 3D object detection. A novel method which realizes the feature-level fusion under bird-eye view (BEV) for a better feature representation is proposed. Firstly, radar features are augmented with temporal accumulation and sent to a temporal-spatial encoder for radar feature extraction. Meanwhile, multi-scale image 2D features which adapt to various spatial scales are obtained by image backbone and neck model. Then, image features are transformed to BEV with the designed view transformer. In addition, this work fuses the multi-modal features with a two-stage fusion model called point fusion and ROI fusion, respectively. Finally, a detection head regresses objects category and 3D locations. Experimental results demonstrate that the proposed method realizes the state-of-the-art performance under the most important detection metrics, mean average precision (mAP) and nuScenes detection score (NDS) on the challenging nuScenes dataset.