 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSComCP: Task-Oriented Semantic Communication for Collaborative Perception
Jul 01, 2025Reliable detection of surrounding objects is critical for the safe operation of connected automated vehicles (CAVs). However, inherent limitations such as the restricted perception range and occlusion effects compromise the reliability of single-vehicle perception systems in complex traffic environments. Collaborative perception has emerged as a promising approach by fusing sensor data from surrounding CAVs with diverse viewpoints, thereby improving environmental awareness. Although collaborative perception holds great promise, its performance is bottlenecked by wireless communication constraints, as unreliable and bandwidth-limited channels hinder the transmission of sensor data necessary for real-time perception. To address these challenges, this paper proposes SComCP, a novel task-oriented semantic communication framework for collaborative perception. Specifically, SComCP integrates an importance-aware feature selection network that selects and transmits semantic features most relevant to the perception task, significantly reducing communication overhead without sacrificing accuracy. Furthermore, we design a semantic codec network based on a joint source and channel coding (JSCC) architecture, which enables bidirectional transformation between semantic features and noise-tolerant channel symbols, thereby ensuring stable perception under adverse wireless conditions. Extensive experiments demonstrate the effectiveness of the proposed framework. In particular, compared to existing approaches, SComCP can maintain superior perception performance across various channel conditions, especially in low signal-to-noise ratio (SNR) scenarios. In addition, SComCP exhibits strong generalization capability, enabling the framework to maintain high performance across diverse channel conditions, even when trained with a specific channel model.
Beam Prediction based on Large Language Models
Aug 16, 2024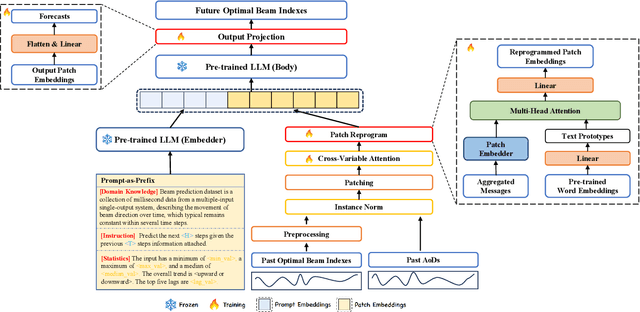
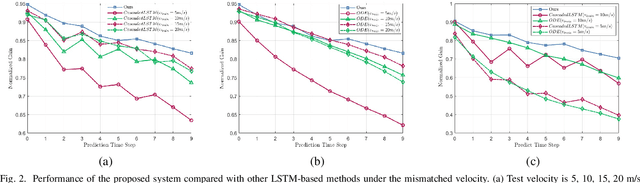

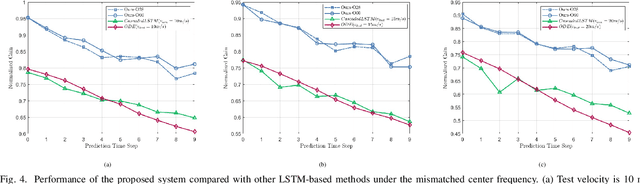
Millimeter-wave (mmWave) communication is promising for next-generation wireless networks but suffers from significant path loss, requiring extensive antenna arrays and frequent beam training. Traditional deep learning models, such as long short-term memory (LSTM), enhance beam tracking accuracy however are limited by poor robustness and generalization. In this letter, we use large language models (LLMs) to improve the robustness of beam prediction. By converting time series data into text-based representations and employing the Prompt-as-Prefix (PaP) technique for contextual enrichment, our approach unleashes the strength of LLMs for time series forecasting. Simulation results demonstrate that our LLM-based method offers superior robustness and generalization compared to LSTM-based models, showcasing the potential of LLMs in wireless communications.
Semantic Communication for Cooperative Perception based on Importance Map
Nov 11, 2023Cooperative perception, which has a broader perception field than single-vehicle perception, has played an increasingly important role in autonomous driving to conduct 3D object detection. Through vehicle-to-vehicle (V2V) communication technology, various connected automated vehicles (CAVs) can share their sensory information (LiDAR point clouds) for cooperative perception. We employ an importance map to extract significant semantic information and propose a novel cooperative perception semantic communication scheme with intermediate fusion. Meanwhile, our proposed architecture can be extended to the challenging time-varying multipath fading channel. To alleviate the distortion caused by the time-varying multipath fading, we adopt explicit orthogonal frequency-division multiplexing (OFDM) blocks combined with channel estimation and channel equalization. Simulation results demonstrate that our proposed model outperforms the traditional separate source-channel coding over various channel models. Moreover, a robustness study indicates that only part of semantic information is key to cooperative perception. Although our proposed model has only been trained over one specific channel, it has the ability to learn robust coded representations of semantic information that remain resilient to various channel models, demonstrating its generality and robustness.