 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images
Feb 23, 2022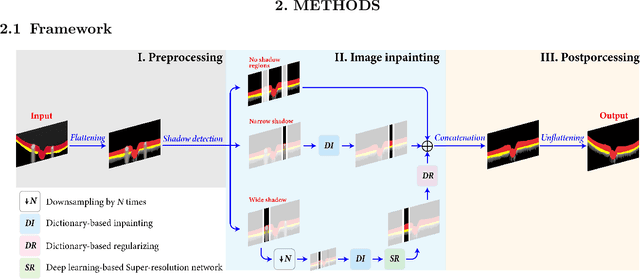


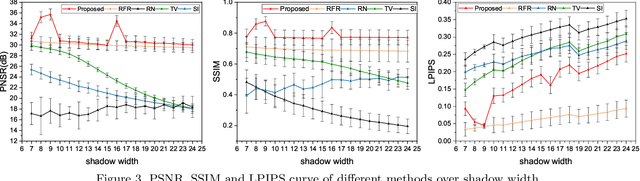
Inpainting shadowed regions cast by superficial blood vessels in retinal optical coherence tomography (OCT) images is critical for accurate and robust machine analysis and clinical diagnosis. Traditional sequence-based approaches such as propagating neighboring information to gradually fill in the missing regions are cost-effective. But they generate less satisfactory outcomes when dealing with larger missing regions and texture-rich structures. Emerging deep learning-based methods such as encoder-decoder networks have shown promising results in natural image inpainting tasks. However, they typically need a long computational time for network training in addition to the high demand on the size of datasets, which makes it difficult to be applied on often small medical datasets. To address these challenges, we propose a novel multi-scale shadow inpainting framework for OCT images by synergically applying sparse representation and deep learning: sparse representation is used to extract features from a small amount of training images for further inpainting and to regularize the image after the multi-scale image fusion, while convolutional neural network (CNN) is employed to enhance the image quality. During the image inpainting, we divide preprocessed input images into different branches based on the shadow width to harvest complementary information from different scales. Finally, a sparse representation-based regularizing module is designed to refine the generated contents after multi-scale feature aggregation. Experiments are conducted to compare our proposal versus both traditional and deep learning-based techniques on synthetic and real-world shadows. Results demonstrate that our proposed method achieves favorable image inpainting in terms of visual quality and quantitative metrics, especially when wide shadows are presented.
Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images
Feb 09, 2021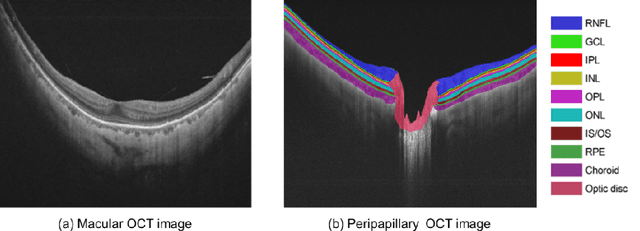
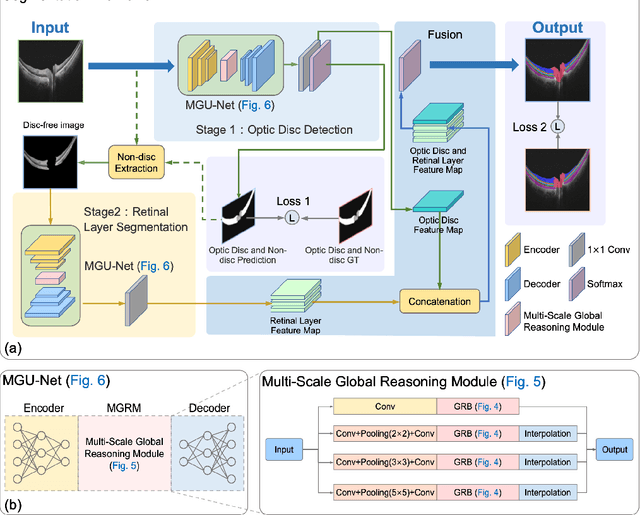
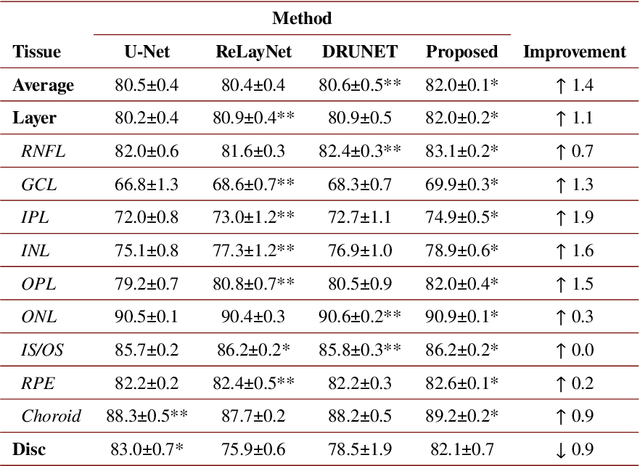
An accurate and automated tissue segmentation algorithm for retinal optical coherence tomography (OCT) images is crucial for the diagnosis of glaucoma. However, due to the presence of the optic disc, the anatomical structure of the peripapillary region of the retina is complicated and is challenging for segmentation. To address this issue, we developed a novel graph convolutional network (GCN)-assisted two-stage framework to simultaneously label the nine retinal layers and the optic disc. Specifically, a multi-scale global reasoning module is inserted between the encoder and decoder of a U-shape neural network to exploit anatomical prior knowledge and perform spatial reasoning. We conducted experiments on human peripapillary retinal OCT images. The Dice score of the proposed segmentation network is 0.820$\pm$0.001 and the pixel accuracy is 0.830$\pm$0.002, both of which outperform those from other state-of-the-art techniques.