Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJPS-daprinfo: A Dataset for Japanese Dialog Act Analysis and People-related Information Detection
Paper and Code
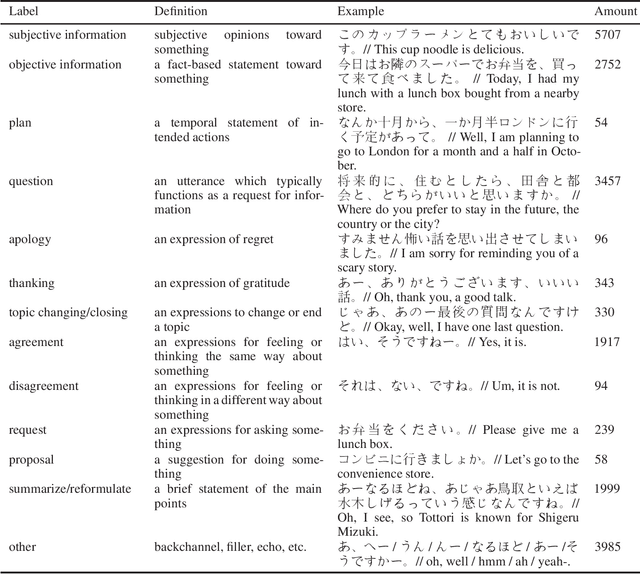
We conducted a labeling work on a spoken Japanese dataset (I-JAS) for the text classification, which contains 50 interview dialogues of two-way Japanese conversation that discuss the participants' past present and future. Each dialogue is 30 minutes long. From this dataset, we selected the interview dialogues of native Japanese speakers as the samples. Given the dataset, we annotated sentences with 13 labels. The labeling work was conducted by native Japanese speakers who have experiences with data annotation. The total amount of the annotated samples is 20130.
View paper on