 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Alignment of LLMs via Sampling-Based Optimal Control in pre-logit space
Oct 30, 2025Test-time alignment of large language models (LLMs) attracts attention because fine-tuning LLMs requires high computational costs. In this paper, we propose a new test-time alignment method called adaptive importance sampling on pre-logits (AISP) on the basis of the sampling-based model predictive control with the stochastic control input. AISP applies the Gaussian perturbation into pre-logits, which are outputs of the penultimate layer, so as to maximize expected rewards with respect to the mean of the perturbation. We demonstrate that the optimal mean is obtained by importance sampling with sampled rewards. AISP outperforms best-of-n sampling in terms of rewards over the number of used samples and achieves higher rewards than other reward-based test-time alignment methods.
Long-term Safe Reinforcement Learning with Binary Feedback
Jan 11, 2024Safety is an indispensable requirement for applying reinforcement learning (RL) to real problems. Although there has been a surge of safe RL algorithms proposed in recent years, most existing work typically 1) relies on receiving numeric safety feedback; 2) does not guarantee safety during the learning process; 3) limits the problem to a priori known, deterministic transition dynamics; and/or 4) assume the existence of a known safe policy for any states. Addressing the issues mentioned above, we thus propose Long-term Binaryfeedback Safe RL (LoBiSaRL), a safe RL algorithm for constrained Markov decision processes (CMDPs) with binary safety feedback and an unknown, stochastic state transition function. LoBiSaRL optimizes a policy to maximize rewards while guaranteeing a long-term safety that an agent executes only safe state-action pairs throughout each episode with high probability. Specifically, LoBiSaRL models the binary safety function via a generalized linear model (GLM) and conservatively takes only a safe action at every time step while inferring its effect on future safety under proper assumptions. Our theoretical results show that LoBiSaRL guarantees the long-term safety constraint, with high probability. Finally, our empirical results demonstrate that our algorithm is safer than existing methods without significantly compromising performance in terms of reward.
Safe Exploration in Reinforcement Learning: A Generalized Formulation and Algorithms
Oct 05, 2023



Safe exploration is essential for the practical use of reinforcement learning (RL) in many real-world scenarios. In this paper, we present a generalized safe exploration (GSE) problem as a unified formulation of common safe exploration problems. We then propose a solution of the GSE problem in the form of a meta-algorithm for safe exploration, MASE, which combines an unconstrained RL algorithm with an uncertainty quantifier to guarantee safety in the current episode while properly penalizing unsafe explorations before actual safety violation to discourage them in future episodes. The advantage of MASE is that we can optimize a policy while guaranteeing with a high probability that no safety constraint will be violated under proper assumptions. Specifically, we present two variants of MASE with different constructions of the uncertainty quantifier: one based on generalized linear models with theoretical guarantees of safety and near-optimality, and another that combines a Gaussian process to ensure safety with a deep RL algorithm to maximize the reward. Finally, we demonstrate that our proposed algorithm achieves better performance than state-of-the-art algorithms on grid-world and Safety Gym benchmarks without violating any safety constraints, even during training.
STLCCP: An Efficient Convex Optimization-based Framework for Signal Temporal Logic Specifications
May 16, 2023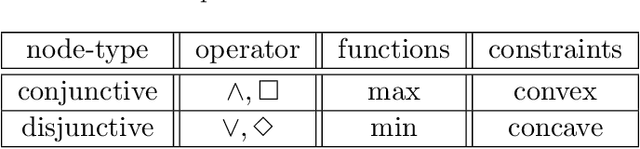


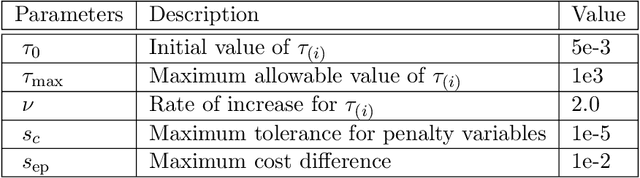
Signal Temporal Logic (STL) is capable of expressing a broad range of temporal properties that controlled dynamical systems must satisfy. In the literature, both mixed-integer programming (MIP) and nonlinear programming (NLP) methods have been applied to solve optimal control problems with STL specifications. However, neither approach has succeeded in solving problems with complex long-horizon STL specifications within a realistic timeframe. This study proposes a new optimization framework, called \textit{STLCCP}, which explicitly incorporates several structures of STL to mitigate this issue. The core of our framework is a structure-aware decomposition of STL formulas, which converts the original program into a difference of convex (DC) programs. This program is then solved as a convex quadratic program sequentially, based on the convex-concave procedure (CCP). Our numerical experiments on several commonly used benchmarks demonstrate that this framework can effectively handle complex scenarios over long horizons, which have been challenging to address even using state-of-the-art optimization methods.
Signal Temporal Logic Meets Convex-Concave Programming: A Structure-Exploiting SQP Algorithm for STL Specifications
Apr 04, 2023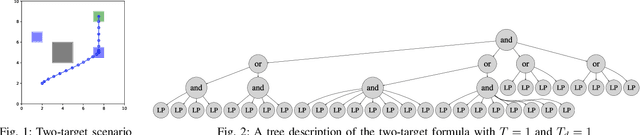
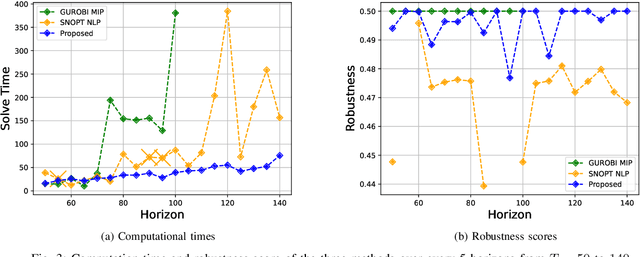
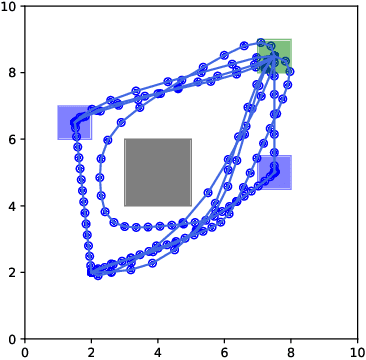
This study considers the control problem with signal temporal logic (STL) specifications. Prior works have adopted smoothing techniques to address this problem within a feasible time frame and solve the problem by applying sequential quadratic programming (SQP) methods naively. However, one of the drawbacks of this approach is that solutions can easily become trapped in local minima that do not satisfy the specification. In this study, we propose a new optimization method, termed CCP-based SQP, based on the convex-concave procedure (CCP). Our framework includes a new robustness decomposition method that decomposes the robustness function into a set of constraints, resulting in a form of difference of convex (DC) program that can be solved efficiently. We solve this DC program sequentially as a quadratic program by only approximating the disjunctive parts of the specifications. Our experimental results demonstrate that our method has a superior performance compared to the state-of-the-art SQP methods in terms of both robustness and computational time.
Neural Controller Synthesis for Signal Temporal Logic Specifications Using Encoder-Decoder Structured Networks
Dec 10, 2022In this paper, we propose a control synthesis method for signal temporal logic (STL) specifications with neural networks (NNs). Most of the previous works consider training a controller for only a given STL specification. These approaches, however, require retraining the NN controller if a new specification arises and needs to be satisfied, which results in large consumption of memory and inefficient training. To tackle this problem, we propose to construct NN controllers by introducing encoder-decoder structured NNs with an attention mechanism. The encoder takes an STL formula as input and encodes it into an appropriate vector, and the decoder outputs control signals that will meet the given specification. As the encoder, we consider three NN structures: sequential, tree-structured, and graph-structured NNs. All the model parameters are trained in an end-to-end manner to maximize the expected robustness that is known to be a quantitative semantics of STL formulae. We compare the control performances attained by the above NN structures through a numerical experiment of the path planning problem, showing the efficacy of the proposed approach.