 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQUIRL: Robust and Efficient Learning from Video Demonstration of Long-Horizon Robotic Manipulation Tasks
Paper and Code
Mar 10, 2020
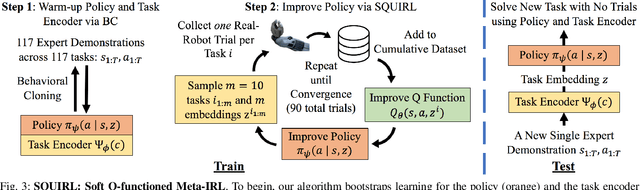


Recent advances in deep reinforcement learning (RL) have demonstrated its potential to learn complex robotic manipulation tasks. However, RL still requires the robot to collect a large amount of real-world experience. To address this problem, recent works have proposed learning from expert demonstrations (LfD), particularly via inverse reinforcement learning (IRL), given its ability to achieve robust performance with only a small number of expert demonstrations. Nevertheless, deploying IRL on real robots is still challenging due to the large number of robot experiences it requires. This paper aims to address this scalability challenge with a robust, sample-efficient, and general meta-IRL algorithm, SQUIRL, that performs a new but related long-horizon task robustly given only a single video demonstration. First, this algorithm bootstraps the learning of a task encoder and a task-conditioned policy using behavioral cloning (BC). It then collects real-robot experiences and bypasses reward learning by directly recovering a Q-function from the combined robot and expert trajectories. Next, this algorithm uses the Q-function to re-evaluate all cumulative experiences collected by the robot to improve the policy quickly. In the end, the policy performs more robustly (90%+ success) than BC on new tasks while requiring no trial-and-errors at test time. Finally, our real-robot and simulated experiments demonstrate our algorithm's generality across different state spaces, action spaces, and vision-based manipulation tasks, e.g., pick-pour-place and pick-carry-drop.