 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Grasping with Reachability and Motion Awareness
Mar 18, 2021
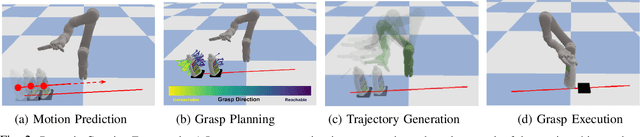
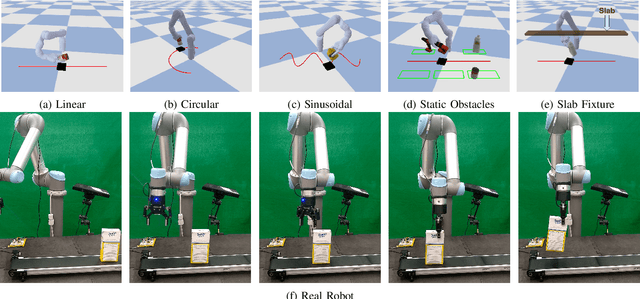
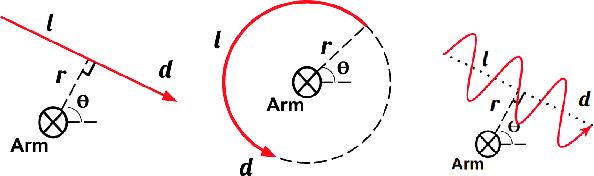
Grasping in dynamic environments presents a unique set of challenges. A stable and reachable grasp can become unreachable and unstable as the target object moves, motion planning needs to be adaptive and in real time, the delay in computation makes prediction necessary. In this paper, we present a dynamic grasping framework that is reachability-aware and motion-aware. Specifically, we model the reachability space of the robot using a signed distance field which enables us to quickly screen unreachable grasps. Also, we train a neural network to predict the grasp quality conditioned on the current motion of the target. Using these as ranking functions, we quickly filter a large grasp database to a few grasps in real time. In addition, we present a seeding approach for arm motion generation that utilizes solution from previous time step. This quickly generates a new arm trajectory that is close to the previous plan and prevents fluctuation. We implement a recurrent neural network (RNN) for modelling and predicting the object motion. Our extensive experiments demonstrate the importance of each of these components and we validate our pipeline on a real robot.
SQUIRL: Robust and Efficient Learning from Video Demonstration of Long-Horizon Robotic Manipulation Tasks
Mar 10, 2020
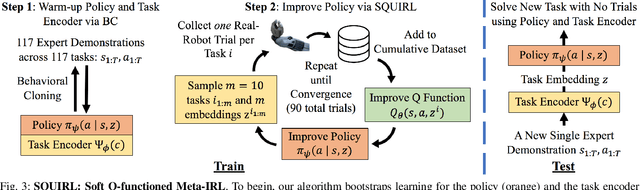


Recent advances in deep reinforcement learning (RL) have demonstrated its potential to learn complex robotic manipulation tasks. However, RL still requires the robot to collect a large amount of real-world experience. To address this problem, recent works have proposed learning from expert demonstrations (LfD), particularly via inverse reinforcement learning (IRL), given its ability to achieve robust performance with only a small number of expert demonstrations. Nevertheless, deploying IRL on real robots is still challenging due to the large number of robot experiences it requires. This paper aims to address this scalability challenge with a robust, sample-efficient, and general meta-IRL algorithm, SQUIRL, that performs a new but related long-horizon task robustly given only a single video demonstration. First, this algorithm bootstraps the learning of a task encoder and a task-conditioned policy using behavioral cloning (BC). It then collects real-robot experiences and bypasses reward learning by directly recovering a Q-function from the combined robot and expert trajectories. Next, this algorithm uses the Q-function to re-evaluate all cumulative experiences collected by the robot to improve the policy quickly. In the end, the policy performs more robustly (90%+ success) than BC on new tasks while requiring no trial-and-errors at test time. Finally, our real-robot and simulated experiments demonstrate our algorithm's generality across different state spaces, action spaces, and vision-based manipulation tasks, e.g., pick-pour-place and pick-carry-drop.
Pixel-Attentive Policy Gradient for Multi-Fingered Grasping in Cluttered Scenes
Mar 25, 2019

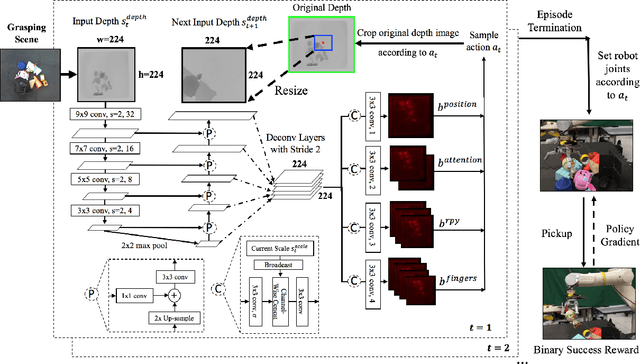

Recent advances in on-policy reinforcement learning (RL) methods enabled learning agents in virtual environments to master complex tasks with high-dimensional and continuous observation and action spaces. However, leveraging this family of algorithms in multi-fingered robotic grasping remains a challenge due to large sim-to-real fidelity gaps and the high sample complexity of on-policy RL algorithms. This work aims to bridge these gaps by first reinforcement-learning a multi-fingered robotic grasping policy in simulation that operates in the pixel space of the input: a single depth image. Using a mapping from pixel space to Cartesian space according to the depth map, this method transfers to the real world with high fidelity and introduces a novel attention mechanism that substantially improves grasp success rate in cluttered environments. Finally, the direct-generative nature of this method allows learning of multi-fingered grasps that have flexible end-effector positions, orientations and rotations, as well as all degrees of freedom of the hand.
Workspace Aware Online Grasp Planning
Jun 29, 2018
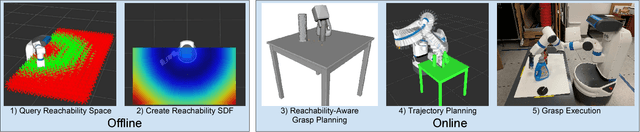
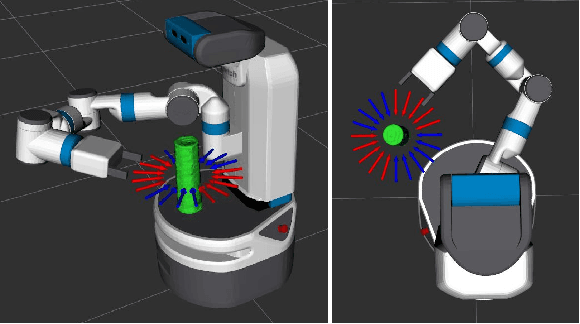
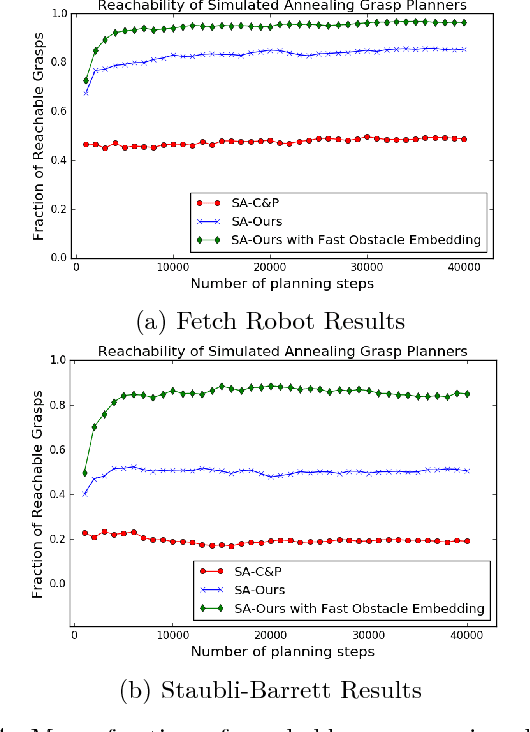
This work provides a framework for a workspace aware online grasp planner. This framework greatly improves the performance of standard online grasp planning algorithms by incorporating a notion of reachability into the online grasp planning process. Offline, a database of hundreds of thousands of unique end-effector poses were queried for feasability. At runtime, our grasp planner uses this database to bias the hand towards reachable end-effector configurations. The bias keeps the grasp planner in accessible regions of the planning scene so that the resulting grasps are tailored to the situation at hand. This results in a higher percentage of reachable grasps, a higher percentage of successful grasp executions, and a reduced planning time. We also present experimental results using simulated and real environments.