 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic DOmain-Targeted Augmentation (S-DOTA) Improves Model Generalization in Digital Pathology
May 03, 2023Machine learning algorithms have the potential to improve patient outcomes in digital pathology. However, generalization of these tools is currently limited by sensitivity to variations in tissue preparation, staining procedures and scanning equipment that lead to domain shift in digitized slides. To overcome this limitation and improve model generalization, we studied the effectiveness of two Synthetic DOmain-Targeted Augmentation (S-DOTA) methods, namely CycleGAN-enabled Scanner Transform (ST) and targeted Stain Vector Augmentation (SVA), and compared them against the International Color Consortium (ICC) profile-based color calibration (ICC Cal) method and a baseline method using traditional brightness, color and noise augmentations. We evaluated the ability of these techniques to improve model generalization to various tasks and settings: four models, two model types (tissue segmentation and cell classification), two loss functions, six labs, six scanners, and three indications (hepatocellular carcinoma (HCC), nonalcoholic steatohepatitis (NASH), prostate adenocarcinoma). We compared these methods based on the macro-averaged F1 scores on in-distribution (ID) and out-of-distribution (OOD) test sets across multiple domains, and found that S-DOTA methods (i.e., ST and SVA) led to significant improvements over ICC Cal and baseline on OOD data while maintaining comparable performance on ID data. Thus, we demonstrate that S-DOTA may help address generalization due to domain shift in real world applications.
S4T: Source-free domain adaptation for semantic segmentation via self-supervised selective self-training
Jul 21, 2021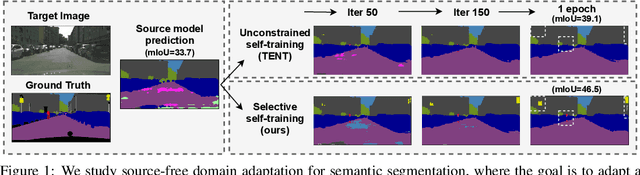
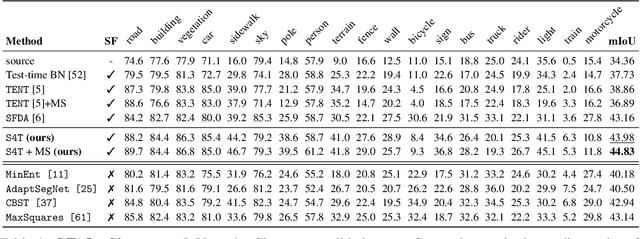
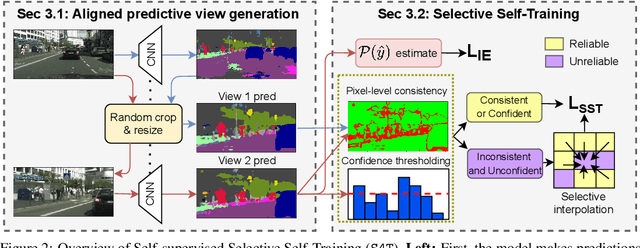

Most modern approaches for domain adaptive semantic segmentation rely on continued access to source data during adaptation, which may be infeasible due to computational or privacy constraints. We focus on source-free domain adaptation for semantic segmentation, wherein a source model must adapt itself to a new target domain given only unlabeled target data. We propose Self-Supervised Selective Self-Training (S4T), a source-free adaptation algorithm that first uses the model's pixel-level predictive consistency across diverse views of each target image along with model confidence to classify pixel predictions as either reliable or unreliable. Next, the model is self-trained, using predicted pseudolabels for reliable predictions and pseudolabels inferred via a selective interpolation strategy for unreliable ones. S4T matches or improves upon the state-of-the-art in source-free adaptation on 3 standard benchmarks for semantic segmentation within a single epoch of adaptation.
SENTRY: Selective Entropy Optimization via Committee Consistency for Unsupervised Domain Adaptation
Dec 21, 2020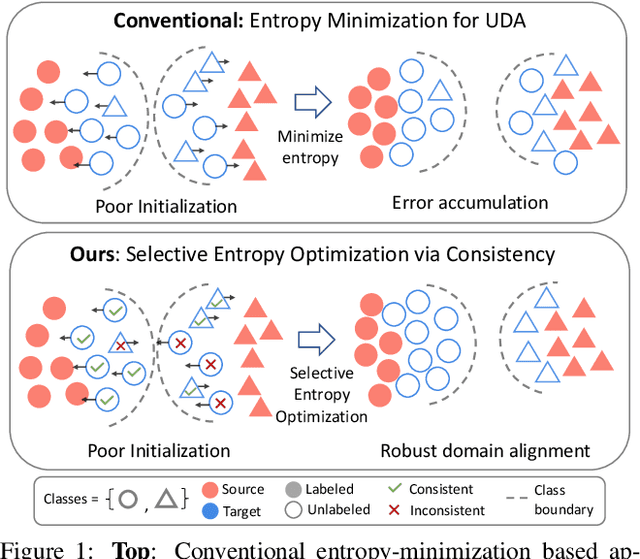
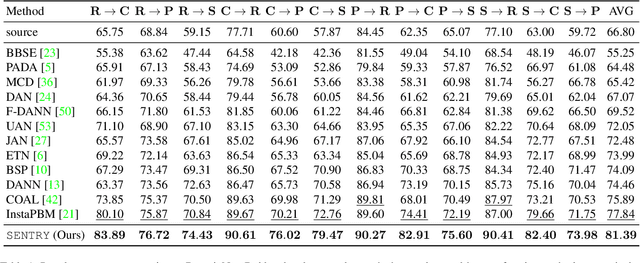

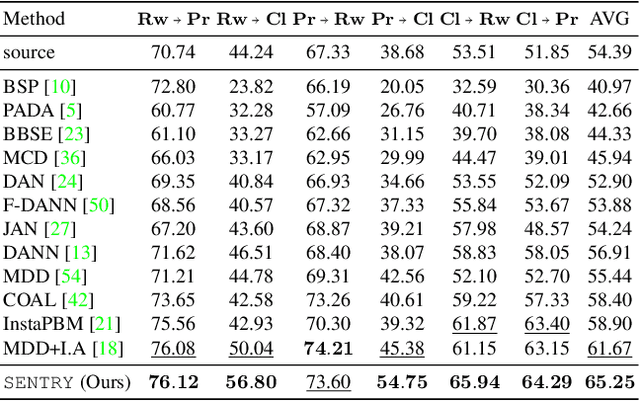
Many existing approaches for unsupervised domain adaptation (UDA) focus on adapting under only data distribution shift and offer limited success under additional cross-domain label distribution shift. Recent work based on self-training using target pseudo-labels has shown promise, but on challenging shifts pseudo-labels may be highly unreliable, and using them for self-training may cause error accumulation and domain misalignment. We propose Selective Entropy Optimization via Committee Consistency (SENTRY), a UDA algorithm that judges the reliability of a target instance based on its predictive consistency under a committee of random image transformations. Our algorithm then selectively minimizes predictive entropy to increase confidence on highly consistent target instances, while maximizing predictive entropy to reduce confidence on highly inconsistent ones. In combination with pseudo-label based approximate target class balancing, our approach leads to significant improvements over the state-of-the-art on 27/31 domain shifts from standard UDA benchmarks as well as benchmarks designed to stress-test adaptation under label distribution shift.