 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS4T: Source-free domain adaptation for semantic segmentation via self-supervised selective self-training
Jul 21, 2021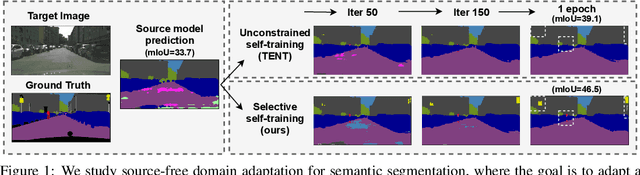
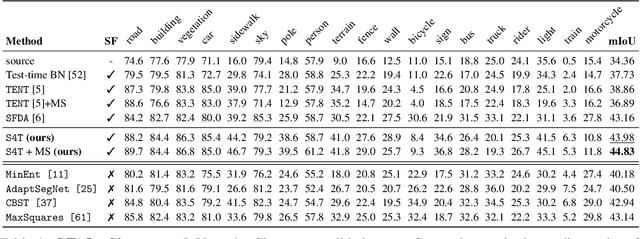
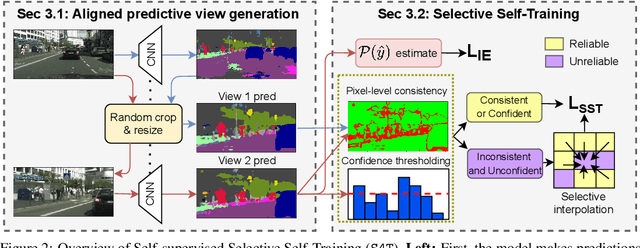

Most modern approaches for domain adaptive semantic segmentation rely on continued access to source data during adaptation, which may be infeasible due to computational or privacy constraints. We focus on source-free domain adaptation for semantic segmentation, wherein a source model must adapt itself to a new target domain given only unlabeled target data. We propose Self-Supervised Selective Self-Training (S4T), a source-free adaptation algorithm that first uses the model's pixel-level predictive consistency across diverse views of each target image along with model confidence to classify pixel predictions as either reliable or unreliable. Next, the model is self-trained, using predicted pseudolabels for reliable predictions and pseudolabels inferred via a selective interpolation strategy for unreliable ones. S4T matches or improves upon the state-of-the-art in source-free adaptation on 3 standard benchmarks for semantic segmentation within a single epoch of adaptation.
Unsupervised Class-Incremental Learning Through Confusion
Apr 09, 2021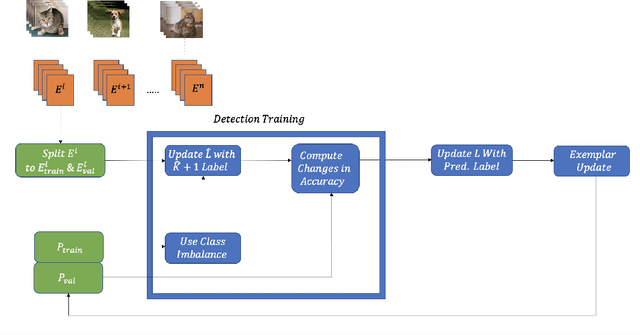

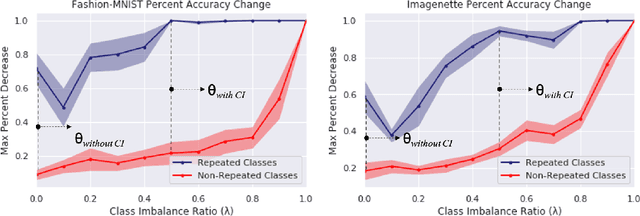
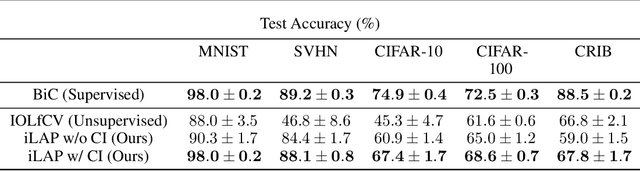
While many works on Continual Learning have shown promising results for mitigating catastrophic forgetting, they have relied on supervised training. To successfully learn in a label-agnostic incremental setting, a model must distinguish between learned and novel classes to properly include samples for training. We introduce a novelty detection method that leverages network confusion caused by training incoming data as a new class. We found that incorporating a class-imbalance during this detection method substantially enhances performance. The effectiveness of our approach is demonstrated across a set of image classification benchmarks: MNIST, SVHN, CIFAR-10, CIFAR-100, and CRIB.
SENTRY: Selective Entropy Optimization via Committee Consistency for Unsupervised Domain Adaptation
Dec 21, 2020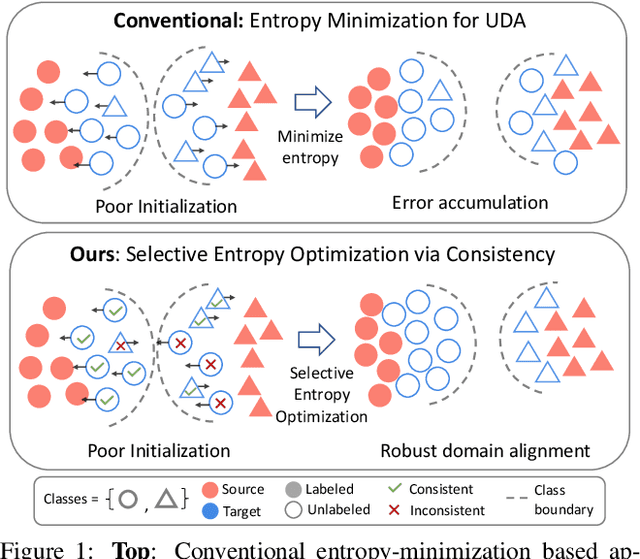
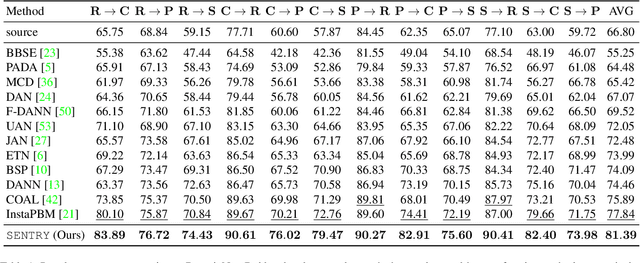

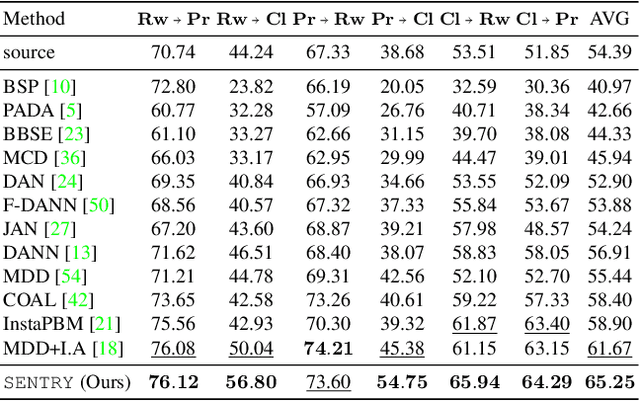
Many existing approaches for unsupervised domain adaptation (UDA) focus on adapting under only data distribution shift and offer limited success under additional cross-domain label distribution shift. Recent work based on self-training using target pseudo-labels has shown promise, but on challenging shifts pseudo-labels may be highly unreliable, and using them for self-training may cause error accumulation and domain misalignment. We propose Selective Entropy Optimization via Committee Consistency (SENTRY), a UDA algorithm that judges the reliability of a target instance based on its predictive consistency under a committee of random image transformations. Our algorithm then selectively minimizes predictive entropy to increase confidence on highly consistent target instances, while maximizing predictive entropy to reduce confidence on highly inconsistent ones. In combination with pseudo-label based approximate target class balancing, our approach leads to significant improvements over the state-of-the-art on 27/31 domain shifts from standard UDA benchmarks as well as benchmarks designed to stress-test adaptation under label distribution shift.