 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Class-Incremental Learning Through Confusion
Apr 09, 2021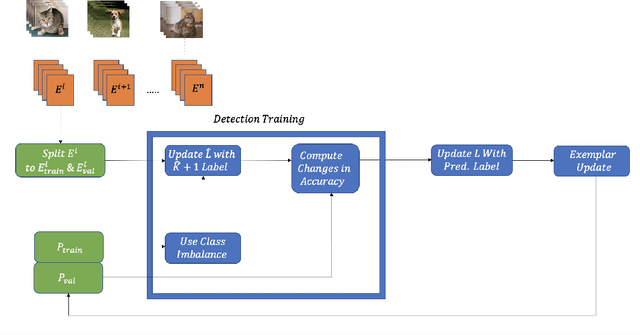

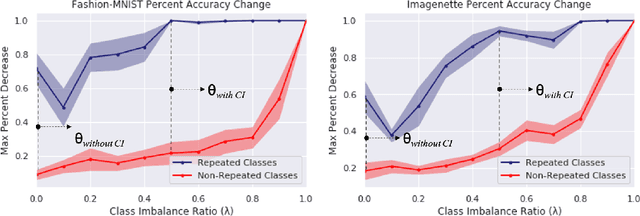
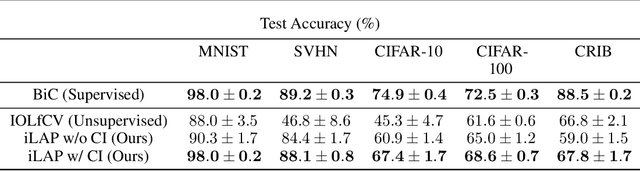
While many works on Continual Learning have shown promising results for mitigating catastrophic forgetting, they have relied on supervised training. To successfully learn in a label-agnostic incremental setting, a model must distinguish between learned and novel classes to properly include samples for training. We introduce a novelty detection method that leverages network confusion caused by training incoming data as a new class. We found that incorporating a class-imbalance during this detection method substantially enhances performance. The effectiveness of our approach is demonstrated across a set of image classification benchmarks: MNIST, SVHN, CIFAR-10, CIFAR-100, and CRIB.
Forecasting Human Object Interaction: Joint Prediction of Motor Attention and Egocentric Activity
Nov 25, 2019
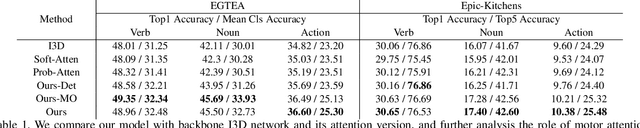
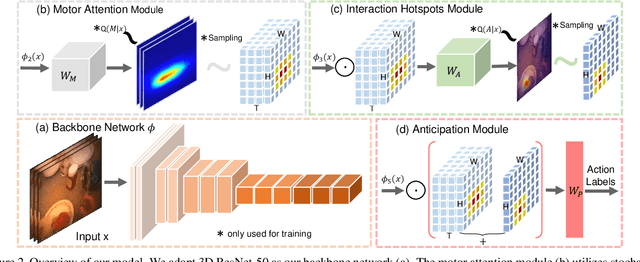

We address the challenging task of anticipating human-object interaction in first person videos. Most existing methods ignore how the camera wearer interacts with the objects, or simply consider body motion as a separate modality. In contrast, we observe that the international hand movement reveals critical information about the future activity. Motivated by this, we adopt intentional hand movement as a future representation and propose a novel deep network that jointly models and predicts the egocentric hand motion, interaction hotspots and future action. Specifically, we consider the future hand motion as the motor attention, and model this attention using latent variables in our deep model. The predicted motor attention is further used to characterise the discriminative spatial-temporal visual features for predicting actions and interaction hotspots. We present extensive experiments demonstrating the benefit of the proposed joint model. Importantly, our model produces new state-of-the-art results for action anticipation on both EGTEA Gaze+ and the EPIC-Kitchens datasets. At the time of submission, our method is ranked first on unseen test set during EPIC-Kitchens Action Anticipation Challenge Phase 2.
Connecting Gaze, Scene, and Attention: Generalized Attention Estimation via Joint Modeling of Gaze and Scene Saliency
Jul 27, 2018

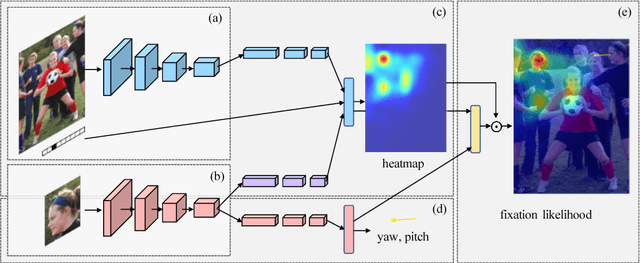
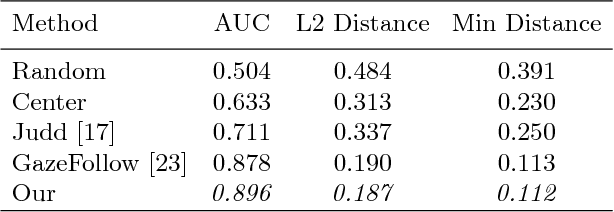
This paper addresses the challenging problem of estimating the general visual attention of people in images. Our proposed method is designed to work across multiple naturalistic social scenarios and provides a full picture of the subject's attention and gaze. In contrast, earlier works on gaze and attention estimation have focused on constrained problems in more specific contexts. In particular, our model explicitly represents the gaze direction and handles out-of-frame gaze targets. We leverage three different datasets using a multi-task learning approach. We evaluate our method on widely used benchmarks for single-tasks such as gaze angle estimation and attention-within-an-image, as well as on the new challenging task of generalized visual attention prediction. In addition, we have created extended annotations for the MMDB and GazeFollow datasets which are used in our experiments, which we will publicly release.