 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSumEval: Scaling LLM Evaluation with Inter-Model Competition
Paper and Code
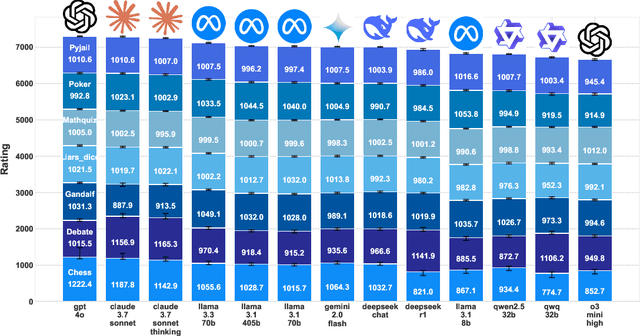



Evaluating the capabilities of Large Language Models (LLMs) has traditionally relied on static benchmark datasets, human assessments, or model-based evaluations - methods that often suffer from overfitting, high costs, and biases. ZeroSumEval is a novel competition-based evaluation protocol that leverages zero-sum games to assess LLMs with dynamic benchmarks that resist saturation. ZeroSumEval encompasses a diverse suite of games, including security challenges (PyJail), classic games (Chess, Liar's Dice, Poker), knowledge tests (MathQuiz), and persuasion challenges (Gandalf, Debate). These games are designed to evaluate a range of AI capabilities such as strategic reasoning, planning, knowledge application, and creativity. Building upon recent studies that highlight the effectiveness of game-based evaluations for LLMs, ZeroSumEval enhances these approaches by providing a standardized and extensible framework. To demonstrate this, we conduct extensive experiments with >7000 simulations across 7 games and 13 models. Our results show that while frontier models from the GPT and Claude families can play common games and answer questions, they struggle to play games that require creating novel and challenging questions. We also observe that models cannot reliably jailbreak each other and fail generally at tasks requiring creativity. We release our code at https://github.com/facebookresearch/ZeroSumEval.