 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multilingual Data Mixtures in Language Model Pretraining
Oct 29, 2025The impact of different multilingual data mixtures in pretraining large language models (LLMs) has been a topic of ongoing debate, often raising concerns about potential trade-offs between language coverage and model performance (i.e., the curse of multilinguality). In this work, we investigate these assumptions by training 1.1B and 3B parameter LLMs on diverse multilingual corpora, varying the number of languages from 25 to 400. Our study challenges common beliefs surrounding multilingual training. First, we find that combining English and multilingual data does not necessarily degrade the in-language performance of either group, provided that languages have a sufficient number of tokens included in the pretraining corpus. Second, we observe that using English as a pivot language (i.e., a high-resource language that serves as a catalyst for multilingual generalization) yields benefits across language families, and contrary to expectations, selecting a pivot language from within a specific family does not consistently improve performance for languages within that family. Lastly, we do not observe a significant "curse of multilinguality" as the number of training languages increases in models at this scale. Our findings suggest that multilingual data, when balanced appropriately, can enhance language model capabilities without compromising performance, even in low-resource settings
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
Apr 08, 2025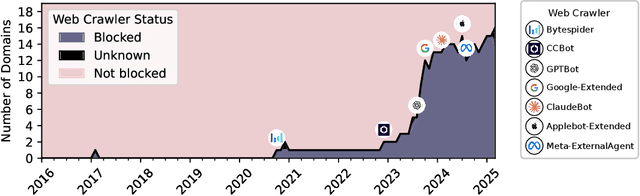



The increasing adoption of web crawling opt-outs by copyright holders of online content raises critical questions about the impact of data compliance on large language model (LLM) performance. However, little is known about how these restrictions (and the resultant filtering of pretraining datasets) affect the capabilities of models trained using these corpora. In this work, we conceptualize this effect as the $\textit{data compliance gap}$ (DCG), which quantifies the performance difference between models trained on datasets that comply with web crawling opt-outs, and those that do not. We measure the data compliance gap in two settings: pretraining models from scratch and continual pretraining from existing compliant models (simulating a setting where copyrighted data could be integrated later in pretraining). Our experiments with 1.5B models show that, as of January 2025, compliance with web data opt-outs does not degrade general knowledge acquisition (close to 0\% DCG). However, in specialized domains such as biomedical research, excluding major publishers leads to performance declines. These findings suggest that while general-purpose LLMs can be trained to perform equally well using fully open data, performance in specialized domains may benefit from access to high-quality copyrighted sources later in training. Our study provides empirical insights into the long-debated trade-off between data compliance and downstream model performance, informing future discussions on AI training practices and policy decisions.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.