 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Powered Recommendation for an Improved Diet Water Footprint
Mar 26, 2024
According to WWF, 1.1 billion people lack access to water, and 2.7 billion experience water scarcity at least one month a year. By 2025, two-thirds of the world's population may be facing water shortages. This highlights the urgency of managing water usage efficiently, especially in water-intensive sectors like food. This paper proposes a recommendation engine, powered by knowledge graphs, aiming to facilitate sustainable and healthy food consumption. The engine recommends ingredient substitutes in user recipes that improve nutritional value and reduce environmental impact, particularly water footprint. The system architecture includes source identification, information extraction, schema alignment, knowledge graph construction, and user interface development. The research offers a promising tool for promoting healthier eating habits and contributing to water conservation efforts.
Contextualizing Internet Memes Across Social Media Platforms
Nov 18, 2023



Internet memes have emerged as a novel format for communication and expressing ideas on the web. Their fluidity and creative nature are reflected in their widespread use, often across platforms and occasionally for unethical or harmful purposes. While computational work has already analyzed their high-level virality over time and developed specialized classifiers for hate speech detection, there have been no efforts to date that aim to holistically track, identify, and map internet memes posted on social media. To bridge this gap, we investigate whether internet memes across social media platforms can be contextualized by using a semantic repository of knowledge, namely, a knowledge graph. We collect thousands of potential internet meme posts from two social media platforms, namely Reddit and Discord, and perform an extract-transform-load procedure to create a data lake with candidate meme posts. By using vision transformer-based similarity, we match these candidates against the memes cataloged in a recently released knowledge graph of internet memes, IMKG. We provide evidence that memes published online can be identified by mapping them to IMKG. We leverage this grounding to study the prevalence of memes on different platforms, discover popular memes, and select common meme channels and subreddits. Finally, we illustrate how the grounding can enable users to get context about memes on social media thanks to their link to the knowledge graph.
Identifying and Consolidating Knowledge Engineering Requirements
Jun 27, 2023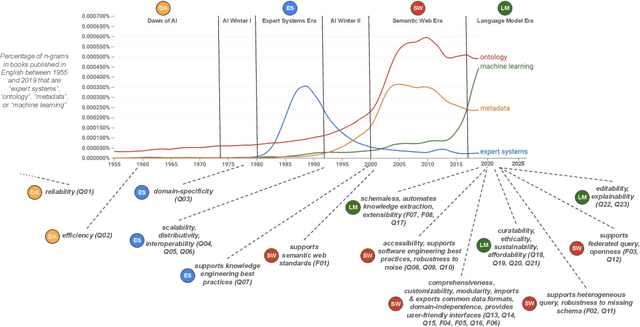
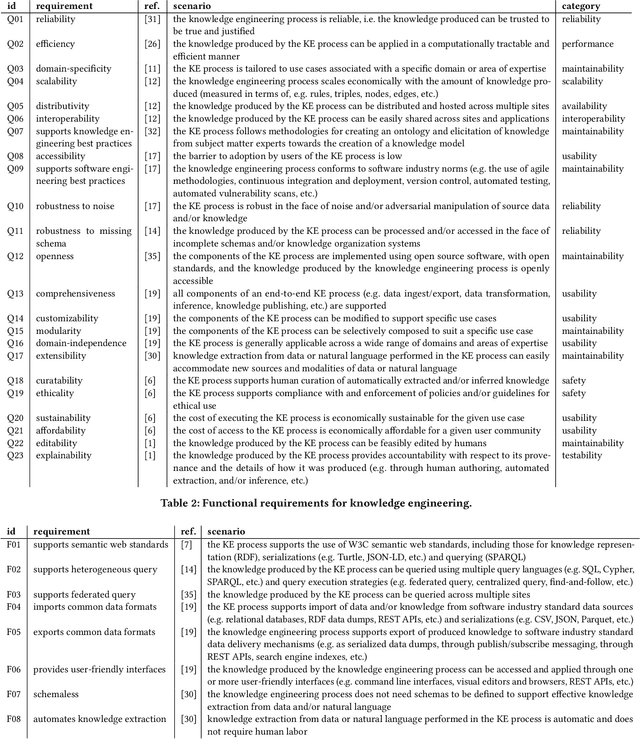
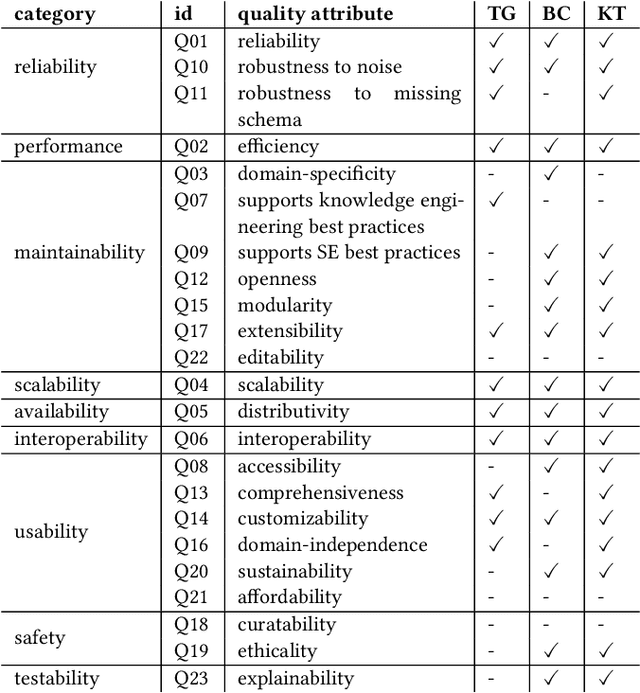
Knowledge engineering is the process of creating and maintaining knowledge-producing systems. Throughout the history of computer science and AI, knowledge engineering workflows have been widely used because high-quality knowledge is assumed to be crucial for reliable intelligent agents. However, the landscape of knowledge engineering has changed, presenting four challenges: unaddressed stakeholder requirements, mismatched technologies, adoption barriers for new organizations, and misalignment with software engineering practices. In this paper, we propose to address these challenges by developing a reference architecture using a mainstream software methodology. By studying the requirements of different stakeholders and eras, we identify 23 essential quality attributes for evaluating reference architectures. We assess three candidate architectures from recent literature based on these attributes. Finally, we discuss the next steps towards a comprehensive reference architecture, including prioritizing quality attributes, integrating components with complementary strengths, and supporting missing socio-technical requirements. As this endeavor requires a collaborative effort, we invite all knowledge engineering researchers and practitioners to join us.