 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Activation Steering to Broad Skills and Multiple Behaviours
Paper and Code

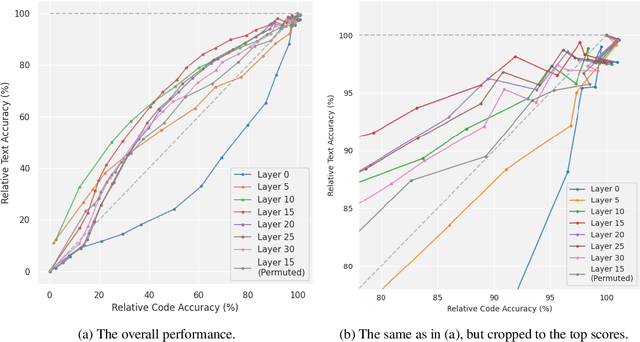
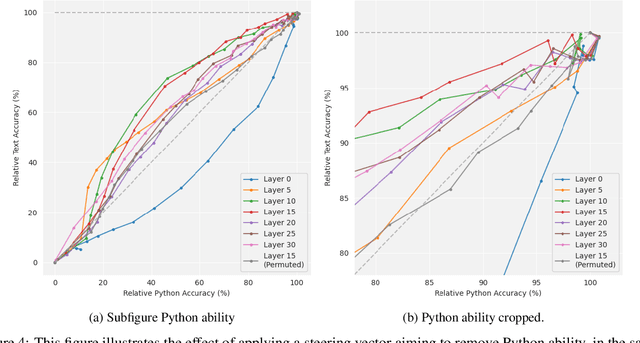
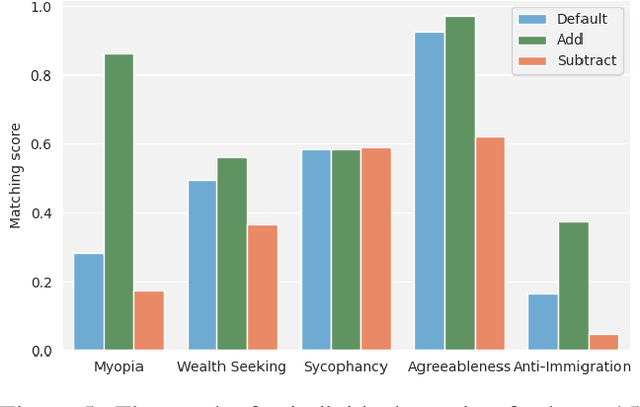
Current large language models have dangerous capabilities, which are likely to become more problematic in the future. Activation steering techniques can be used to reduce risks from these capabilities. In this paper, we investigate the efficacy of activation steering for broad skills and multiple behaviours. First, by comparing the effects of reducing performance on general coding ability and Python-specific ability, we find that steering broader skills is competitive to steering narrower skills. Second, we steer models to become more or less myopic and wealth-seeking, among other behaviours. In our experiments, combining steering vectors for multiple different behaviours into one steering vector is largely unsuccessful. On the other hand, injecting individual steering vectors at different places in a model simultaneously is promising.