 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Assessment of Human vs. Model Uncertainty in Soft-Label Learning and Calibration
May 18, 2026Central to human-aligned AI is understanding the benefits of human-elicited labels over synthetic alternatives. While human soft-labels improve calibration by capturing uncertainty, prior studies conflate these benefits with the implicit correction of mislabeled data (mode shifts), obscuring true effects of soft-labels. We present a controlled audit of soft-label learning across MNIST and a synthetic variant, re-annotating subsets to extract human uncertainty. By decoupling soft-label supervision from underlying label mode shifts, we show that while human soft-labels do provide accuracy gains, their larger value lies in acting as a regularizer that improves model calibration on difficult samples and promotes stable convergence across training runs. Dataset cartography reveals models trained on human soft-labels mirror human uncertainty, whereas those trained on synthetic labels fail to align with humans. Broadly, this work provides a diagnostic testbed for human-AI uncertainty alignment.
Understanding Model Calibration -- A gentle introduction and visual exploration of calibration and the expected calibration error (ECE)
Jan 31, 2025To be considered reliable, a model must be calibrated so that its confidence in each decision closely reflects its true outcome. In this blogpost we'll take a look at the most commonly used definition for calibration and then dive into a frequently used evaluation measure for model calibration. We'll then cover some of the drawbacks of this measure and how these surfaced the need for additional notions of calibration, which require their own new evaluation measures. This post is not intended to be an in-depth dissection of all works on calibration, nor does it focus on how to calibrate models. Instead, it is meant to provide a gentle introduction to the different notions and their evaluation measures as well as to re-highlight some issues with a measure that is still widely used to evaluate calibration.
Understanding The Effect Of Temperature On Alignment With Human Opinions
Nov 15, 2024



With the increasing capabilities of LLMs, recent studies focus on understanding whose opinions are represented by them and how to effectively extract aligned opinion distributions. We conducted an empirical analysis of three straightforward methods for obtaining distributions and evaluated the results across a variety of metrics. Our findings suggest that sampling and log-probability approaches with simple parameter adjustments can return better aligned outputs in subjective tasks compared to direct prompting. Yet, assuming models reflect human opinions may be limiting, highlighting the need for further research on how human subjectivity affects model uncertainty.
The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
May 02, 2024

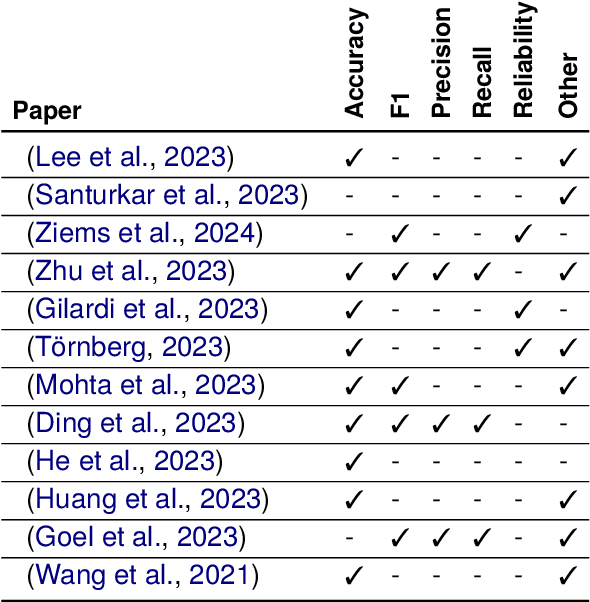

Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.