 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbuse is Contextual, What about NLP? The Role of Context in Abusive Language Annotation and Detection
Paper and Code
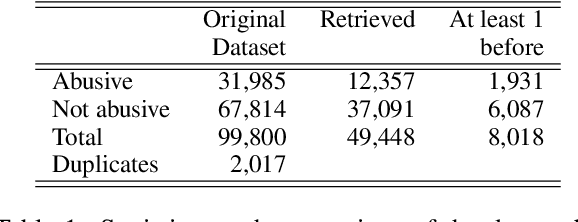


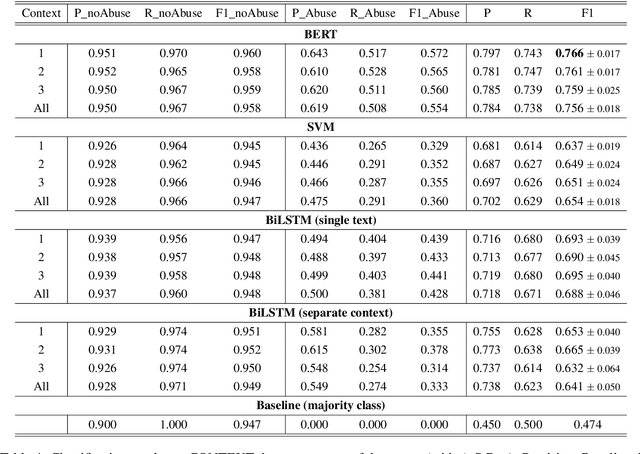
The datasets most widely used for abusive language detection contain lists of messages, usually tweets, that have been manually judged as abusive or not by one or more annotators, with the annotation performed at message level. In this paper, we investigate what happens when the hateful content of a message is judged also based on the context, given that messages are often ambiguous and need to be interpreted in the context of occurrence. We first re-annotate part of a widely used dataset for abusive language detection in English in two conditions, i.e. with and without context. Then, we compare the performance of three classification algorithms obtained on these two types of dataset, arguing that a context-aware classification is more challenging but also more similar to a real application scenario.