 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Multimodal Dataset of Images and Text to Study Abusive Language
Paper and Code
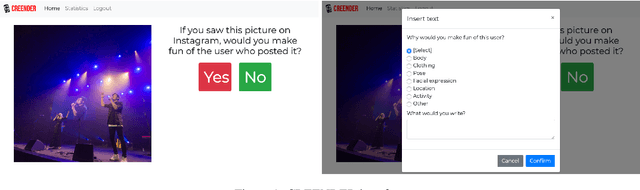

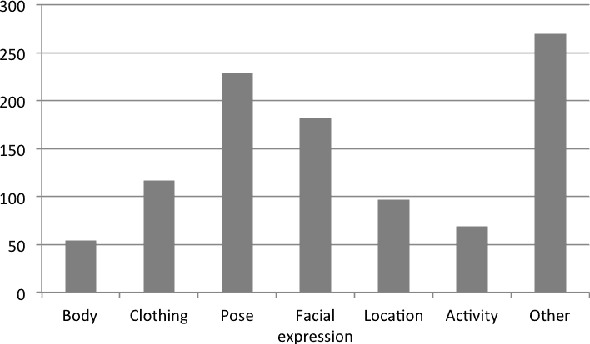
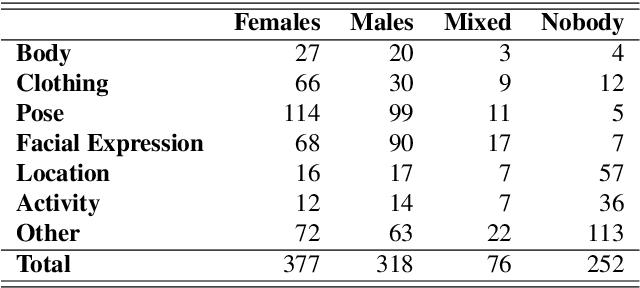
In order to study online hate speech, the availability of datasets containing the linguistic phenomena of interest are of crucial importance. However, when it comes to specific target groups, for example teenagers, collecting such data may be problematic due to issues with consent and privacy restrictions. Furthermore, while text-only datasets of this kind have been widely used, limitations set by image-based social media platforms like Instagram make it difficult for researchers to experiment with multimodal hate speech data. We therefore developed CREENDER, an annotation tool that has been used in school classes to create a multimodal dataset of images and abusive comments, which we make freely available under Apache 2.0 license. The corpus, with Italian comments, has been analysed from different perspectives, to investigate whether the subject of the images plays a role in triggering a comment. We find that users judge the same images in different ways, although the presence of a person in the picture increases the probability to get an offensive comment.