 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Oct 07, 2023



Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 14, 2023Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.
Enhancing the Unified Streaming and Non-streaming Model with Contrastive Learning
Jun 01, 2023



The unified streaming and non-streaming speech recognition model has achieved great success due to its comprehensive capabilities. In this paper, we propose to improve the accuracy of the unified model by bridging the inherent representation gap between the streaming and non-streaming modes with a contrastive objective. Specifically, the top-layer hidden representation at the same frame of the streaming and non-streaming modes are regarded as a positive pair, encouraging the representation of the streaming mode close to its non-streaming counterpart. The multiple negative samples are randomly selected from the rest frames of the same sample under the non-streaming mode. Experimental results demonstrate that the proposed method achieves consistent improvements toward the unified model in both streaming and non-streaming modes. Our method achieves CER of 4.66% in the streaming mode and CER of 4.31% in the non-streaming mode, which sets a new state-of-the-art on the AISHELL-1 benchmark.
The System Description of dun_oscar team for The ICPR MSR Challenge
Mar 13, 2023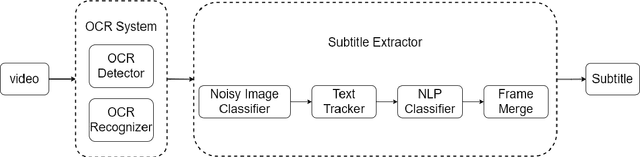


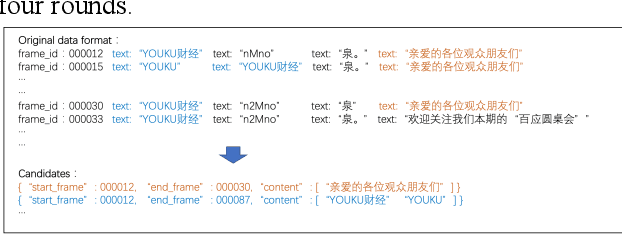
This paper introduces the system submitted by dun_oscar team for the ICPR MSR Challenge. Three subsystems for task1-task3 are descripted respectively. In task1, we develop a visual system which includes a OCR model, a text tracker, and a NLP classifier for distinguishing subtitles and non-subtitles. In task2, we employ an ASR system which includes an AM with 18 layers and a 4-gram LM. Semi-supervised learning on unlabeled data is also vital. In task3, we employ the ASR system to improve the visual system, some false subtitles can be corrected by a fusion module.
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022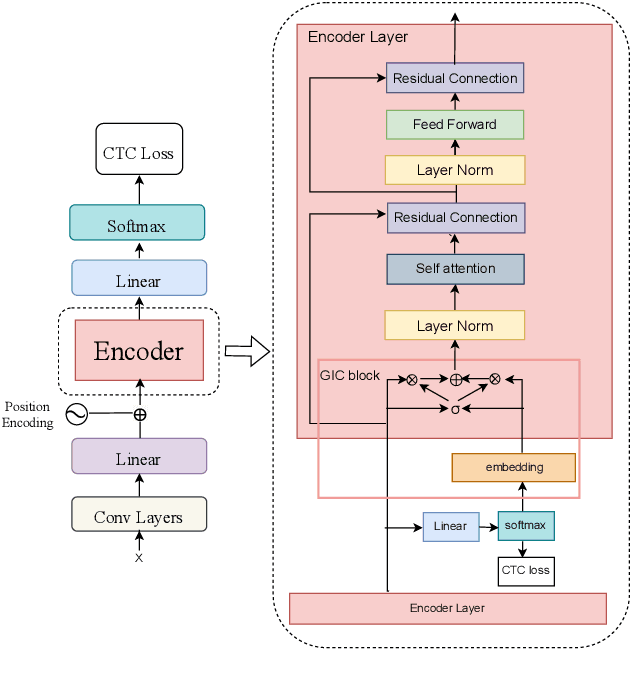
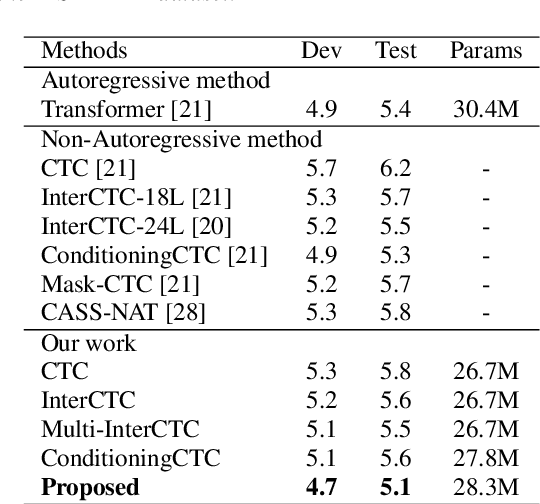
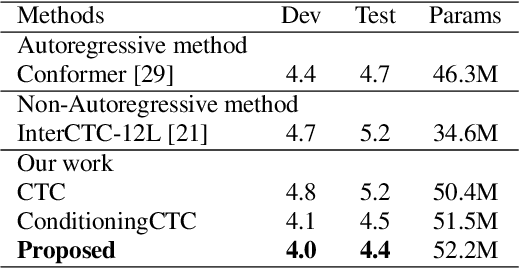
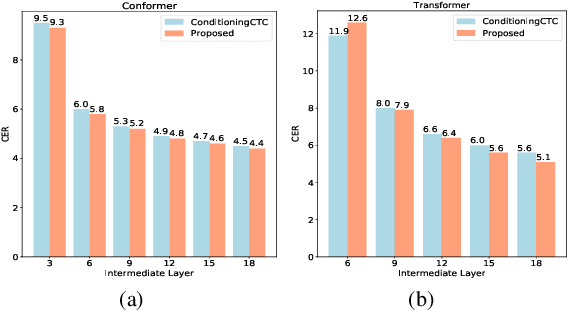
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.
Multi-Level Modeling Units for End-to-End Mandarin Speech Recognition
May 25, 2022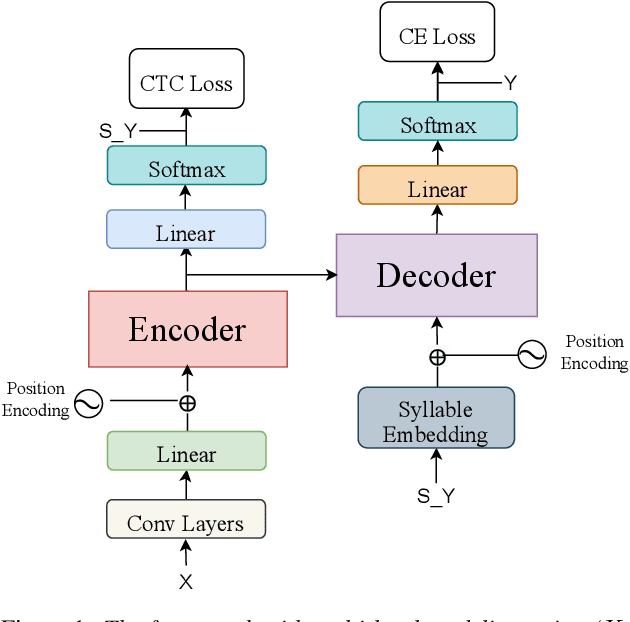

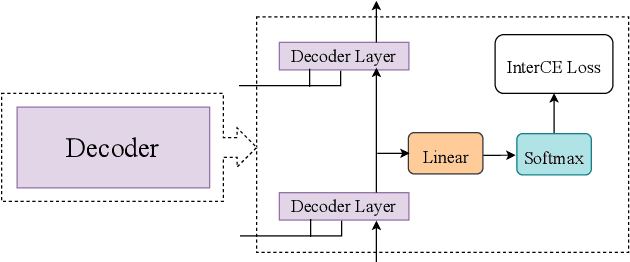
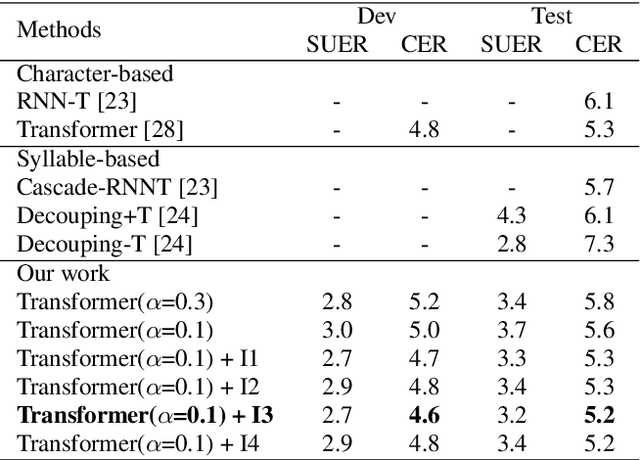
The choice of modeling units affects the performance of the acoustic modeling and plays an important role in automatic speech recognition (ASR). In mandarin scenarios, the Chinese characters represent meaning but are not directly related to the pronunciation. Thus only considering the writing of Chinese characters as modeling units is insufficient to capture speech features. In this paper, we present a novel method involves with multi-level modeling units, which integrates multi-level information for mandarin speech recognition. Specifically, the encoder block considers syllables as modeling units, and the decoder block deals with character modeling units. During inference, the input feature sequences are converted into syllable sequences by the encoder block and then converted into Chinese characters by the decoder block. This process is conducted by a unified end-to-end model without introducing additional conversion models. By introducing InterCE auxiliary task, our method achieves competitive results with CER of 4.1%/4.6% and 4.6%/5.2% on the widely used AISHELL-1 benchmark without a language model, using the Conformer and the Transformer backbones respectively.
BBS-KWS:The Mandarin Keyword Spotting System Won the Video Keyword Wakeup Challenge
Dec 03, 2021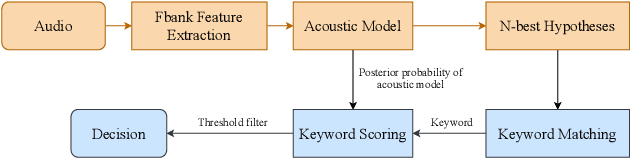

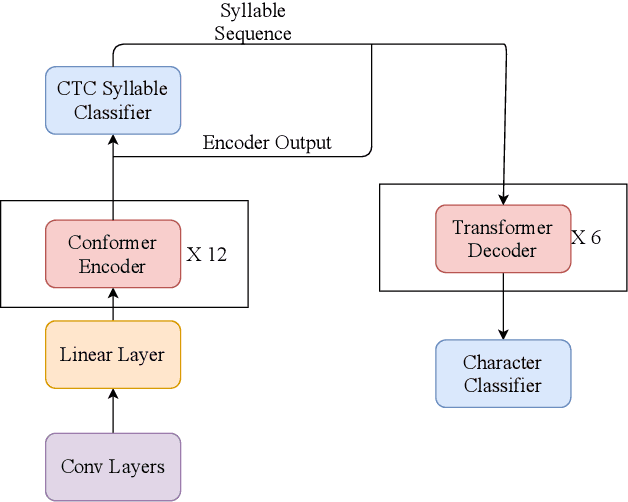
This paper introduces the system submitted by the Yidun NISP team to the video keyword wakeup challenge. We propose a mandarin keyword spotting system (KWS) with several novel and effective improvements, including a big backbone (B) model, a keyword biasing (B) mechanism and the introduction of syllable modeling units (S). By considering this, we term the total system BBS-KWS as an abbreviation. The BBS-KWS system consists of an end-to-end automatic speech recognition (ASR) module and a KWS module. The ASR module converts speech features to text representations, which applies a big backbone network to the acoustic model and takes syllable modeling units into consideration as well. In addition, the keyword biasing mechanism is used to improve the recall rate of keywords in the ASR inference stage. The KWS module applies multiple criteria to determine the absence or presence of the keywords, such as multi-stage matching, fuzzy matching, and connectionist temporal classification (CTC) prefix score. To further improve our system, we conduct semi-supervised learning on the CN-Celeb dataset for better generalization. In the VKW task, the BBS-KWS system achieves significant gains over the baseline and won the first place in two tracks.