 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving CTC-based ASR Models with Gated Interlayer Collaboration
Paper and Code
May 25, 2022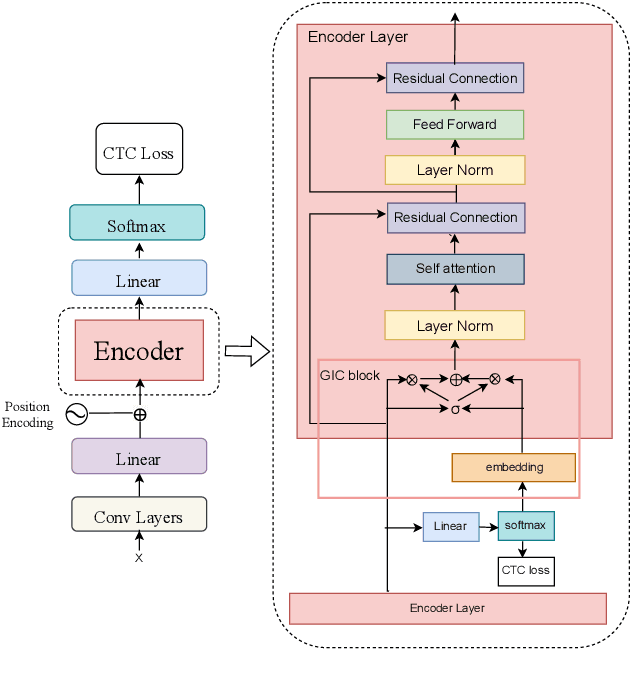
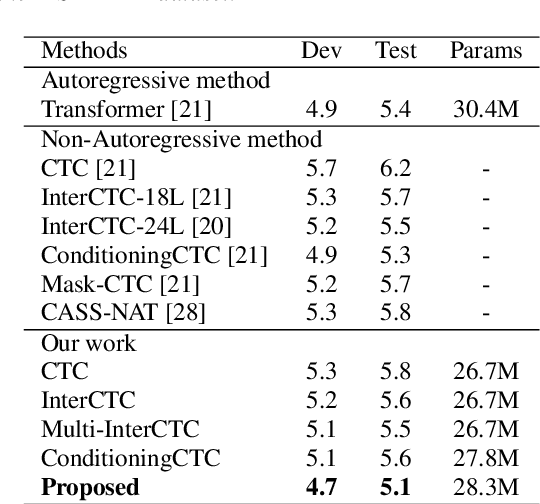
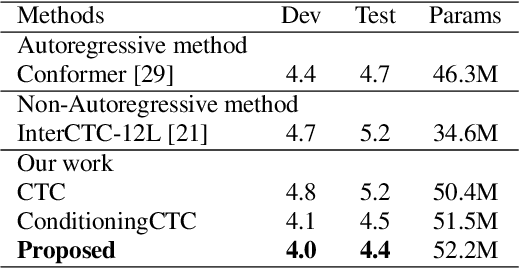
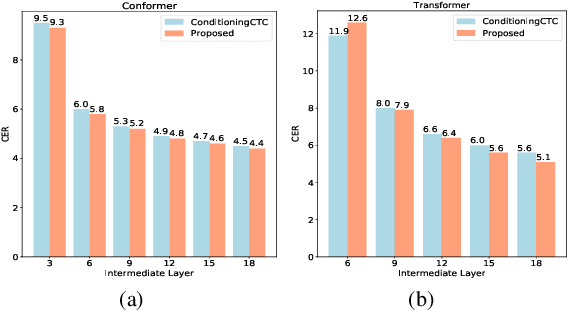
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.