 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Oct 07, 2023



Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 14, 2023Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.
A Policy-based Approach to the SpecAugment Method for Low Resource E2E ASR
Oct 16, 2022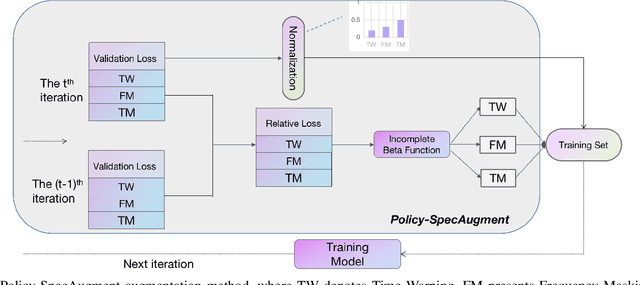
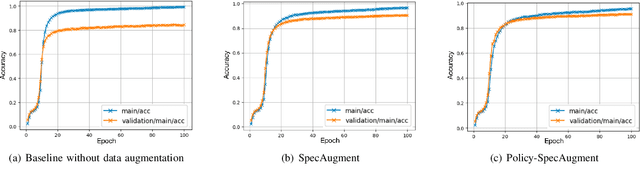
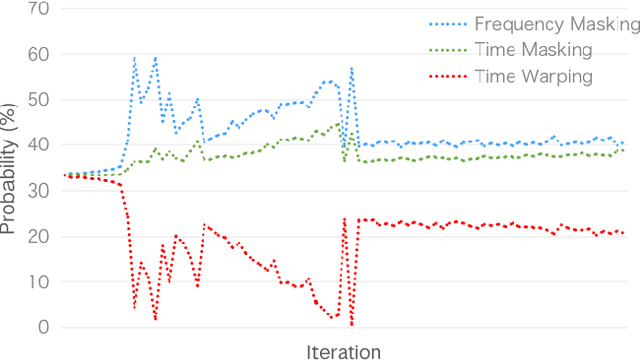
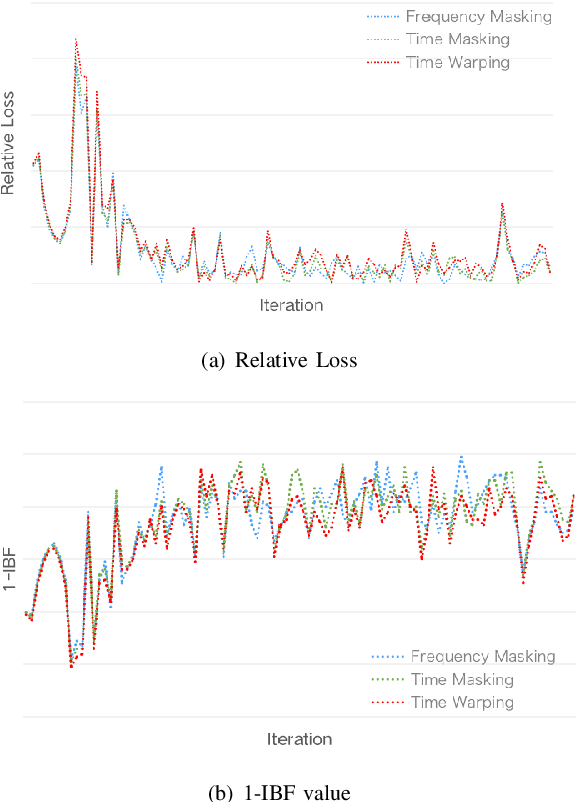
SpecAugment is a very effective data augmentation method for both HMM and E2E-based automatic speech recognition (ASR) systems. Especially, it also works in low-resource scenarios. However, SpecAugment masks the spectrum of time or the frequency domain in a fixed augmentation policy, which may bring relatively less data diversity to the low-resource ASR. In this paper, we propose a policy-based SpecAugment (Policy-SpecAugment) method to alleviate the above problem. The idea is to use the augmentation-select policy and the augmentation-parameter changing policy to solve the fixed way. These policies are learned based on the loss of validation set, which is applied to the corresponding augmentation policies. It aims to encourage the model to learn more diverse data, which the model relatively requires. In experiments, we evaluate the effectiveness of our approach in low-resource scenarios, i.e., the 100 hours librispeech task. According to the results and analysis, we can see that the above issue can be obviously alleviated using our proposal. In addition, the experimental results show that, compared with the state-of-the-art SpecAugment, the proposed Policy-SpecAugment has a relative WER reduction of more than 10% on the Test/Dev-clean set, more than 5% on the Test/Dev-other set, and an absolute WER reduction of more than 1% on all test sets.
Leveraging Phone Mask Training for Phonetic-Reduction-Robust E2E Uyghur Speech Recognition
Apr 02, 2022
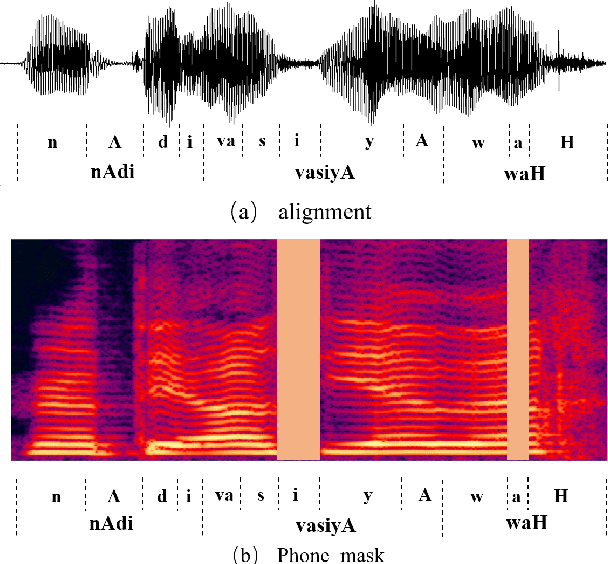

In Uyghur speech, consonant and vowel reduction are often encountered, especially in spontaneous speech with high speech rate, which will cause a degradation of speech recognition performance. To solve this problem, we propose an effective phone mask training method for Conformer-based Uyghur end-to-end (E2E) speech recognition. The idea is to randomly mask off a certain percentage features of phones during model training, which simulates the above verbal phenomena and facilitates E2E model to learn more contextual information. According to experiments, the above issues can be greatly alleviated. In addition, deep investigations are carried out into different units in masking, which shows the effectiveness of our proposed masking unit. We also further study the masking method and optimize filling strategy of phone mask. Finally, compared with Conformer-based E2E baseline without mask training, our model demonstrates about 5.51% relative Word Error Rate (WER) reduction on reading speech and 12.92% on spontaneous speech, respectively. The above approach has also been verified on test-set of open-source data THUYG-20, which shows 20% relative improvements.
* Accepted by INTERSPEECH 2021
PM-MMUT: Boosted Phone-mask Data Augmentation using Multi-modeing Unit Training for Robust Uyghur E2E Speech Recognition
Dec 13, 2021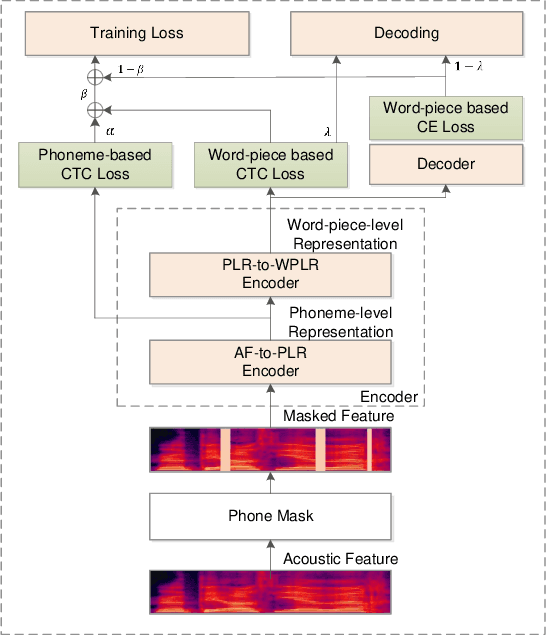
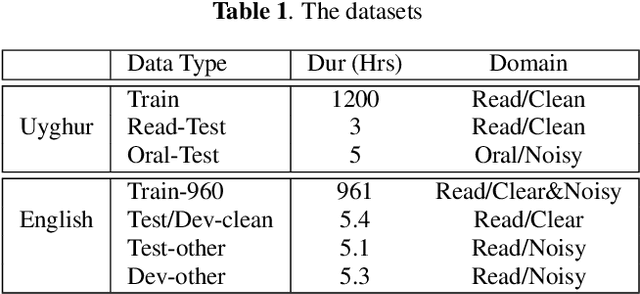
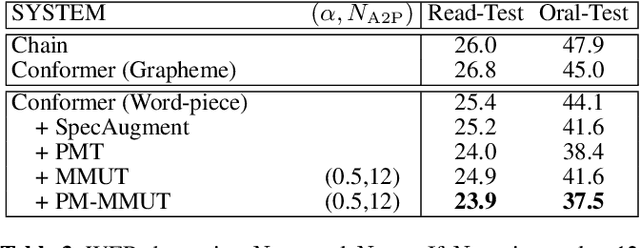
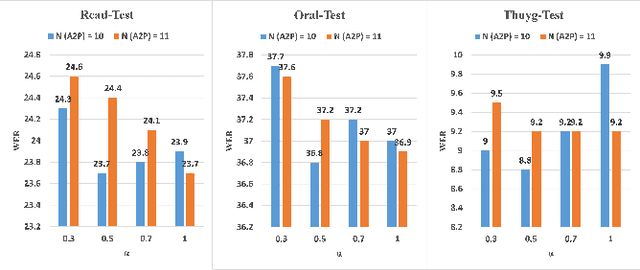
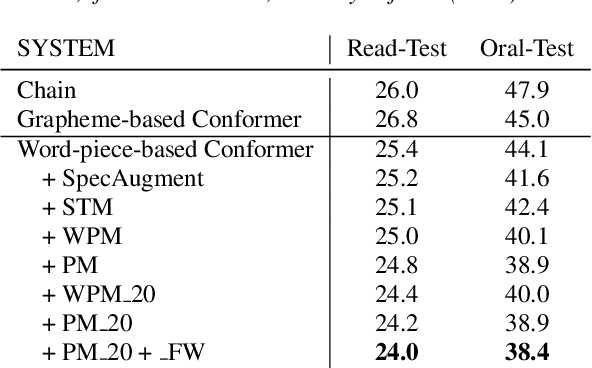
Consonant and vowel reduction are often encountered in Uyghur speech, which might cause performance degradation in Uyghur automatic speech recognition (ASR). Our recently proposed learning strategy based on masking, Phone Masking Training (PMT), alleviates the impact of such phenomenon in Uyghur ASR. Although PMT achieves remarkably improvements, there still exists room for further gains due to the granularity mismatch between masking unit of PMT (phoneme) and modeling unit (word-piece). To boost the performance of PMT, we propose multi-modeling unit training (MMUT) architecture fusion with PMT (PM-MMUT). The idea of MMUT framework is to split the Encoder into two parts including acoustic feature sequences to phoneme-level representation (AF-to-PLR) and phoneme-level representation to word-piece-level representation (PLR-to-WPLR). It allows AF-to-PLR to be optimized by an intermediate phoneme-based CTC loss to learn the rich phoneme-level context information brought by PMT. Experi-mental results on Uyghur ASR show that the proposed approaches improve significantly, outperforming the pure PMT (reduction WER from 24.0 to 23.7 on Read-Test and from 38.4 to 36.8 on Oral-Test respectively). We also conduct experiments on the 960-hour Librispeech benchmark using ESPnet1, which achieves about 10% relative WER reduction on all the test sets without LM fusion comparing with the latest official ESPnet1 pre-trained model.
Machine Learning Promoting Extreme Simplification of Spectroscopy Equipment
Aug 06, 2018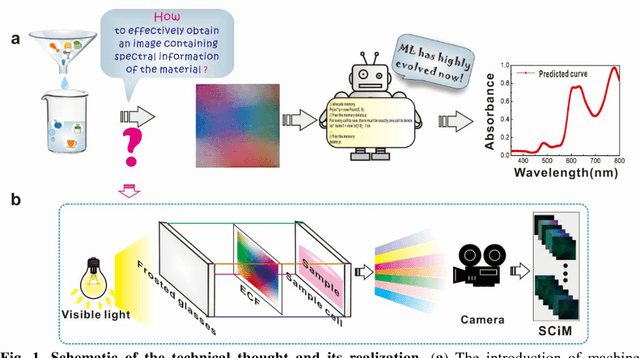
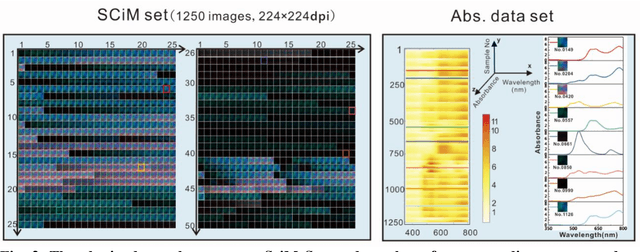
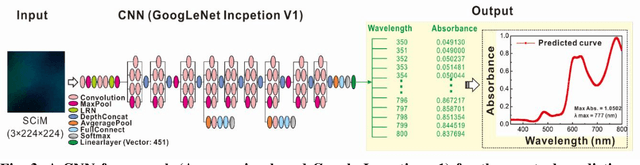
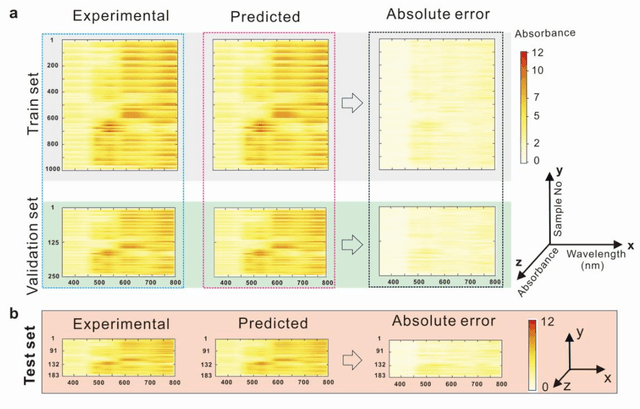
The spectroscopy measurement is one of main pathways for exploring and understanding the nature. Today, it seems that racing artificial intelligence will remould its styles. The algorithms contained in huge neural networks are capable of substituting many of expensive and complex components of spectrum instruments. In this work, we presented a smart machine learning strategy on the measurement of absorbance curves, and also initially verified that an exceedingly-simplified equipment is sufficient to meet the needs for this strategy. Further, with its simplicity, the setup is expected to infiltrate into many scientific areas in versatile forms.