 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-RWKV: Lightweight medical image segmentation with direction-adaptive RWKV
Jul 15, 2025Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at https://github.com/hbyecoding/U-RWKV.
Bioinspired Sensing of Undulatory Flow Fields Generated by Leg Kicks in Swimming
Mar 10, 2025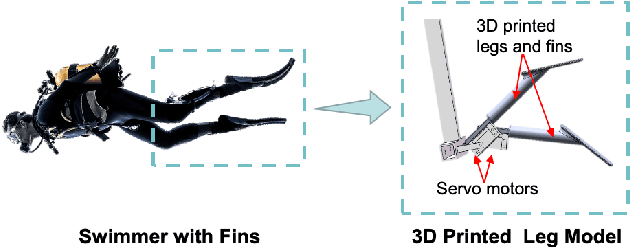
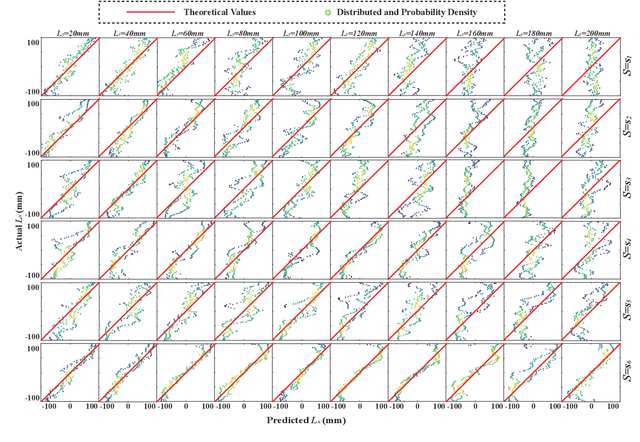
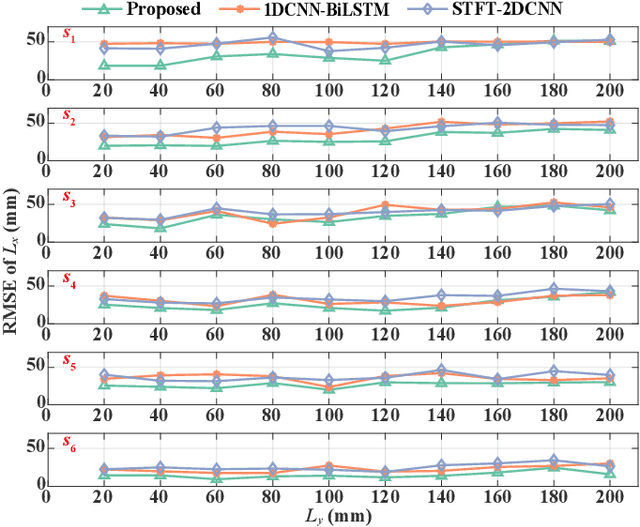
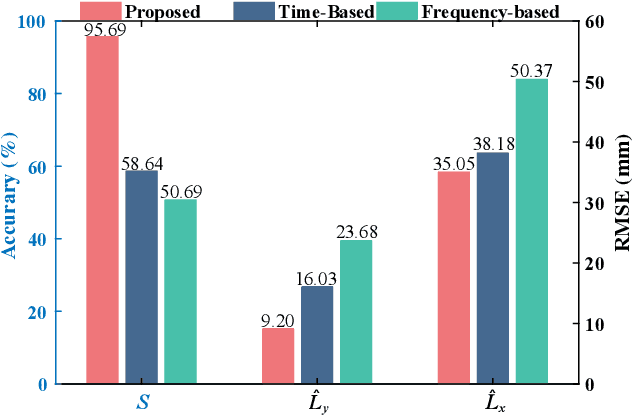
The artificial lateral line (ALL) is a bioinspired flow sensing system for underwater robots, comprising of distributed flow sensors. The ALL has been successfully applied to detect the undulatory flow fields generated by body undulation and tail-flapping of bioinspired robotic fish. However, its feasibility and performance in sensing the undulatory flow fields produced by human leg kicks during swimming has not been systematically tested and studied. This paper presents a novel sensing framework to investigate the undulatory flow field generated by swimmer's leg kicks, leveraging bioinspired ALL sensing. To evaluate the feasibility of using the ALL system for sensing the undulatory flow fields generated by swimmer leg kicks, this paper designs an experimental platform integrating an ALL system and a lab-fabricated human leg model. To enhance the accuracy of flow sensing, this paper proposes a feature extraction method that dynamically fuses time-domain and time-frequency characteristics. Specifically, time-domain features are extracted using one-dimensional convolutional neural networks and bidirectional long short-term memory networks (1DCNN-BiLSTM), while time-frequency features are extracted using short-term Fourier transform and two-dimensional convolutional neural networks (STFT-2DCNN). These features are then dynamically fused based on attention mechanisms to achieve accurate sensing of the undulatory flow field. Furthermore, extensive experiments are conducted to test various scenarios inspired by human swimming, such as leg kick pattern recognition and kicking leg localization, achieving satisfactory results.
Target Defense with Multiple Defenders and an Agile Attacker via Residual Policy Learning
Feb 25, 2025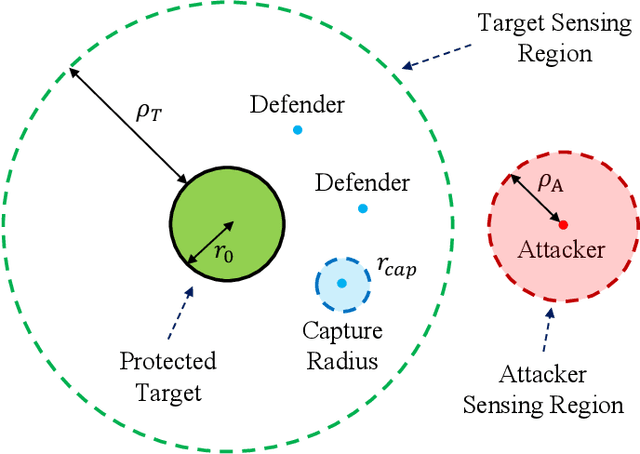
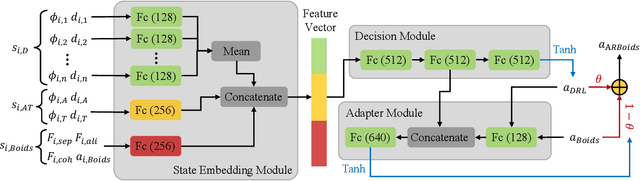
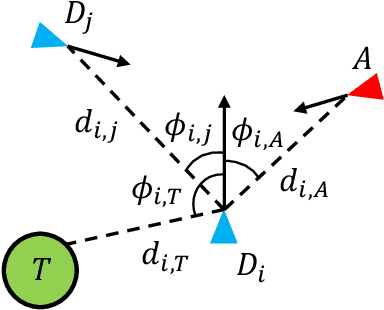
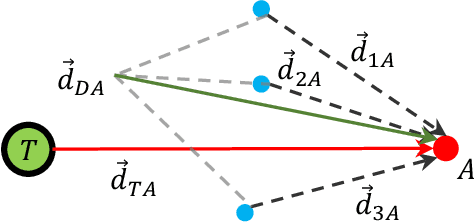
The target defense problem involves intercepting an attacker before it reaches a designated target region using one or more defenders. This letter focuses on a particularly challenging scenario in which the attacker is more agile than the defenders, significantly increasing the difficulty of effective interception. To address this challenge, we propose a novel residual policy framework that integrates deep reinforcement learning (DRL) with the force-based Boids model. In this framework, the Boids model serves as a baseline policy, while DRL learns a residual policy to refine and optimize the defenders' actions. Simulation experiments demonstrate that the proposed method consistently outperforms traditional interception policies, whether learned via vanilla DRL or fine-tuned from force-based methods. Moreover, the learned policy exhibits strong scalability and adaptability, effectively handling scenarios with varying numbers of defenders and attackers with different agility levels.
An Efficient Learning Control Framework With Sim-to-Real for String-Type Artificial Muscle-Driven Robotic Systems
May 17, 2024



Robotic systems driven by artificial muscles present unique challenges due to the nonlinear dynamics of actuators and the complex designs of mechanical structures. Traditional model-based controllers often struggle to achieve desired control performance in such systems. Deep reinforcement learning (DRL), a trending machine learning technique widely adopted in robot control, offers a promising alternative. However, integrating DRL into these robotic systems faces significant challenges, including the requirement for large amounts of training data and the inevitable sim-to-real gap when deployed to real-world robots. This paper proposes an efficient reinforcement learning control framework with sim-to-real transfer to address these challenges. Bootstrap and augmentation enhancements are designed to improve the data efficiency of baseline DRL algorithms, while a sim-to-real transfer technique, namely randomization of muscle dynamics, is adopted to bridge the gap between simulation and real-world deployment. Extensive experiments and ablation studies are conducted utilizing two string-type artificial muscle-driven robotic systems including a two degree-of-freedom robotic eye and a parallel robotic wrist, the results of which demonstrate the effectiveness of the proposed learning control strategy.
Estimating the Lateral Motion States of an Underwater Robot by Propeller Wake Sensing Using an Artificial Lateral Line
Jan 06, 2024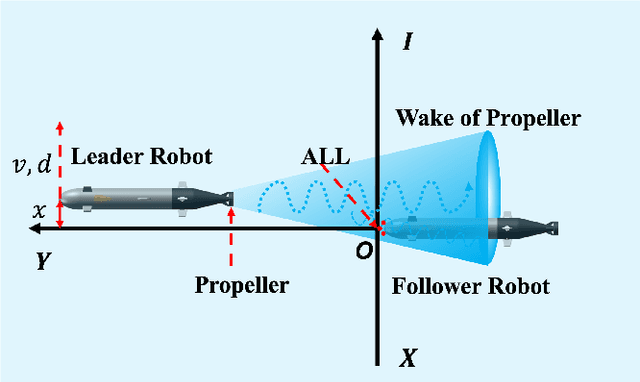
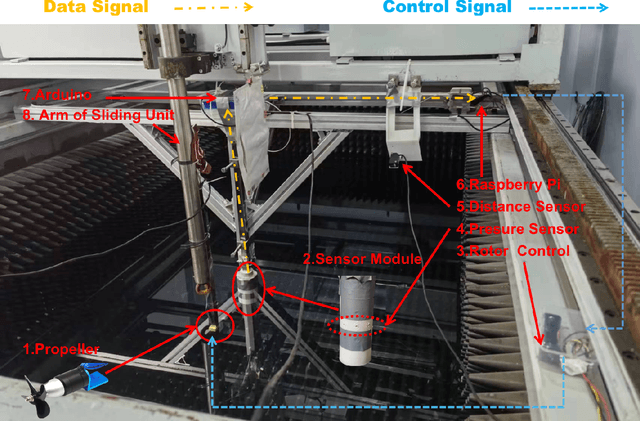
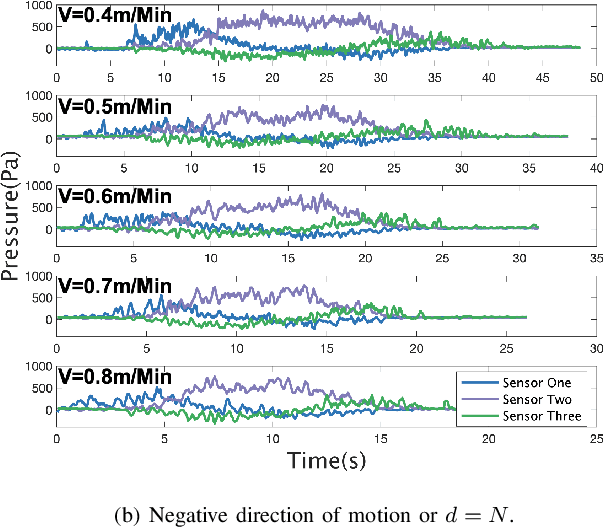
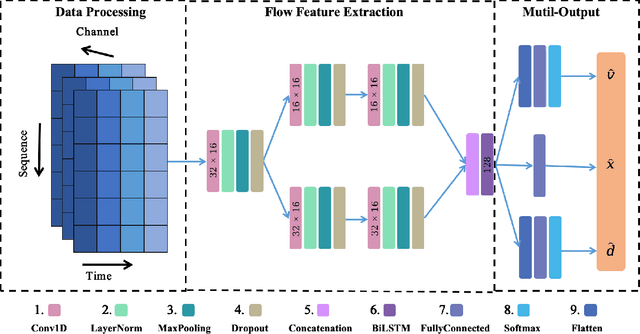
An artificial lateral line (ALL) is a bioinspired flow sensing system of an underwater robot that consists of distributed flow sensors. The ALL has achieved great success in sensing the motion states of bioinspired underwater robots, e.g., robotic fish, that are driven by body undulation and/or tail flapping. However, the ALL has not been systematically tested and studied in the sensing of underwater robots driven by rotating propellers due to the highly dynamic and complex flow field therein. This paper makes a bold hypothesis that the distributed flow measurements sampled from the propeller wake flow, although infeasible to represent the entire flow dynamics, provides sufficient information for estimating the lateral motion states of the leader underwater robot. An experimental testbed is constructed to investigate the feasibility of such a state estimator which comprises a cylindrical ALL sensory system, a rotating leader propeller, and a water tank with a planar sliding guide. Specifically, a hybrid network that consists of a one-dimensional convolution network (1DCNN) and a bidirectional long short-term memory network (BiLSTM) is designed to extract the spatiotemporal features of the time series of distributed pressure measurements. A multi-output deep learning network is adopted to estimate the lateral motion states of the leader propeller. In addition, the state estimator is optimized using the whale optimization algorithm (WOA) considering the comprehensive estimation performance. Extensive experiments are conducted the results of which validate the proposed data-driven algorithm in estimating the motion states of the leader underwater robot by propeller wake sensing.
A Policy-based Approach to the SpecAugment Method for Low Resource E2E ASR
Oct 16, 2022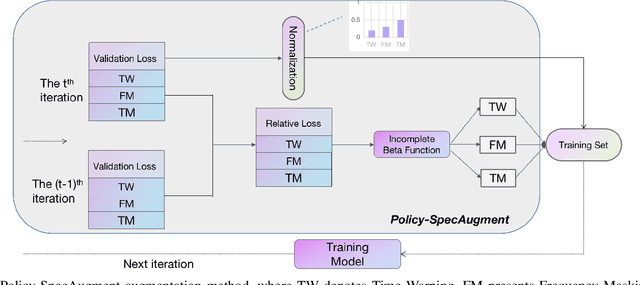
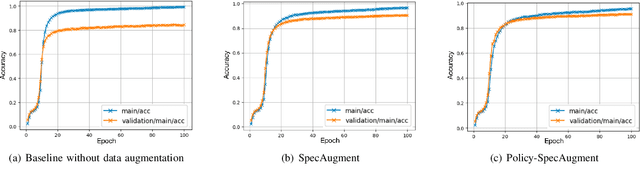
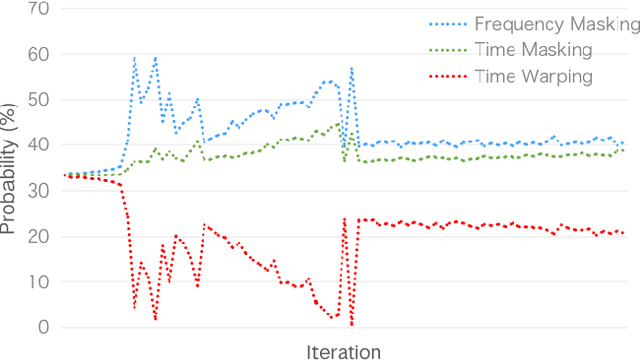
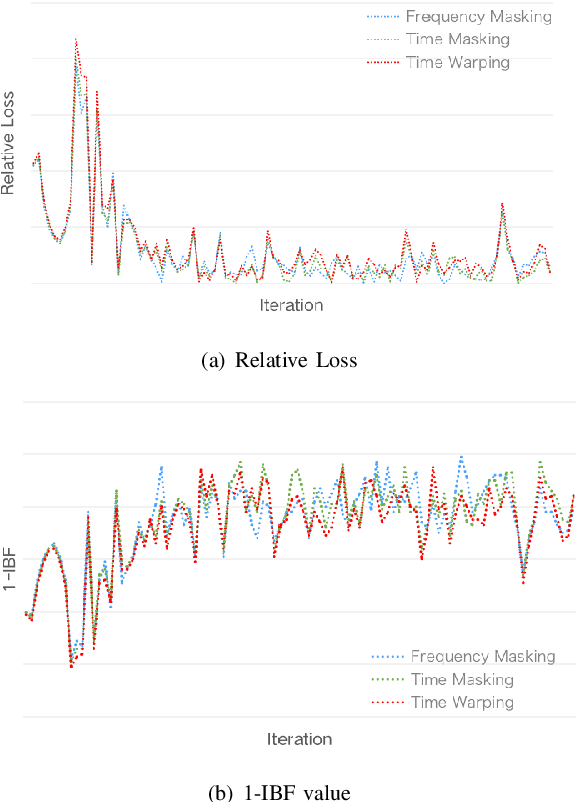
SpecAugment is a very effective data augmentation method for both HMM and E2E-based automatic speech recognition (ASR) systems. Especially, it also works in low-resource scenarios. However, SpecAugment masks the spectrum of time or the frequency domain in a fixed augmentation policy, which may bring relatively less data diversity to the low-resource ASR. In this paper, we propose a policy-based SpecAugment (Policy-SpecAugment) method to alleviate the above problem. The idea is to use the augmentation-select policy and the augmentation-parameter changing policy to solve the fixed way. These policies are learned based on the loss of validation set, which is applied to the corresponding augmentation policies. It aims to encourage the model to learn more diverse data, which the model relatively requires. In experiments, we evaluate the effectiveness of our approach in low-resource scenarios, i.e., the 100 hours librispeech task. According to the results and analysis, we can see that the above issue can be obviously alleviated using our proposal. In addition, the experimental results show that, compared with the state-of-the-art SpecAugment, the proposed Policy-SpecAugment has a relative WER reduction of more than 10% on the Test/Dev-clean set, more than 5% on the Test/Dev-other set, and an absolute WER reduction of more than 1% on all test sets.