 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Defense with Multiple Defenders and an Agile Attacker via Residual Policy Learning
Paper and Code
Feb 25, 2025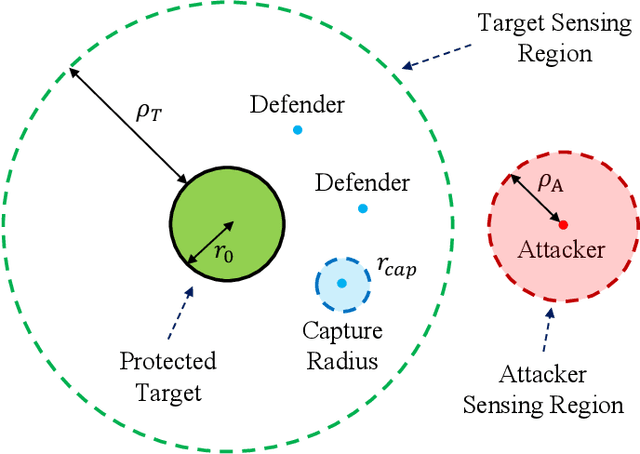
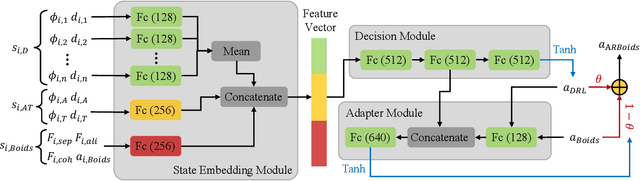
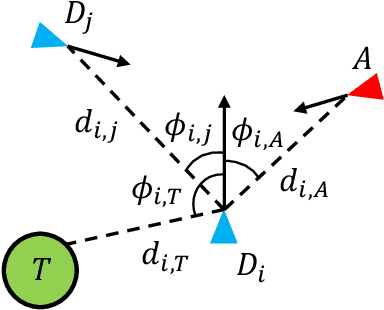
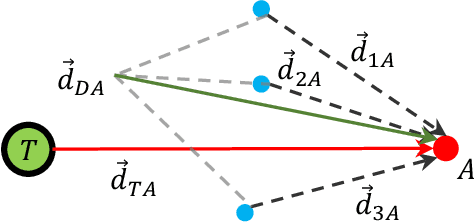
The target defense problem involves intercepting an attacker before it reaches a designated target region using one or more defenders. This letter focuses on a particularly challenging scenario in which the attacker is more agile than the defenders, significantly increasing the difficulty of effective interception. To address this challenge, we propose a novel residual policy framework that integrates deep reinforcement learning (DRL) with the force-based Boids model. In this framework, the Boids model serves as a baseline policy, while DRL learns a residual policy to refine and optimize the defenders' actions. Simulation experiments demonstrate that the proposed method consistently outperforms traditional interception policies, whether learned via vanilla DRL or fine-tuned from force-based methods. Moreover, the learned policy exhibits strong scalability and adaptability, effectively handling scenarios with varying numbers of defenders and attackers with different agility levels.