 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucination in Visual Language Models with Visual Supervision
Nov 27, 2023



Large vision-language models (LVLMs) suffer from hallucination a lot, generating responses that apparently contradict to the image content occasionally. The key problem lies in its weak ability to comprehend detailed content in a multi-modal context, which can be mainly attributed to two factors in training data and loss function. The vision instruction dataset primarily focuses on global description, and the auto-regressive loss function favors text modeling rather than image understanding. In this paper, we bring more detailed vision annotations and more discriminative vision models to facilitate the training of LVLMs, so that they can generate more precise responses without encounter hallucination. On one hand, we generate image-text pairs with detailed relationship annotations in panoptic scene graph dataset (PSG). These conversations pay more attention on detailed facts in the image, encouraging the model to answer questions based on multi-modal contexts. On the other hand, we integrate SAM and mask prediction loss as auxiliary supervision, forcing the LVLMs to have the capacity to identify context-related objects, so that they can generate more accurate responses, mitigating hallucination. Moreover, to provide a deeper evaluation on the hallucination in LVLMs, we propose a new benchmark, RAH-Bench. It divides vision hallucination into three different types that contradicts the image with wrong categories, attributes or relations, and introduces False Positive Rate as detailed sub-metric for each type. In this benchmark, our approach demonstrates an +8.4% enhancement compared to original LLaVA and achieves widespread performance improvements across other models.
FreConv: Frequency Branch-and-Integration Convolutional Networks
Apr 10, 2023
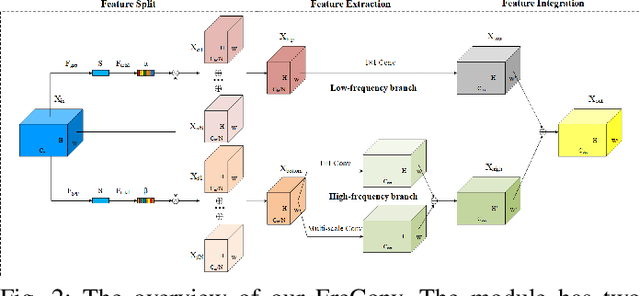

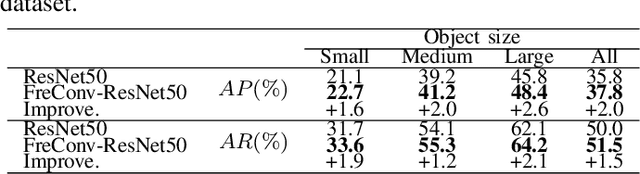
Recent researches indicate that utilizing the frequency information of input data can enhance the performance of networks. However, the existing popular convolutional structure is not designed specifically for utilizing the frequency information contained in datasets. In this paper, we propose a novel and effective module, named FreConv (frequency branch-and-integration convolution), to replace the vanilla convolution. FreConv adopts a dual-branch architecture to extract and integrate high- and low-frequency information. In the high-frequency branch, a derivative-filter-like architecture is designed to extract the high-frequency information while a light extractor is employed in the low-frequency branch because the low-frequency information is usually redundant. FreConv is able to exploit the frequency information of input data in a more reasonable way to enhance feature representation ability and reduce the memory and computational cost significantly. Without any bells and whistles, experimental results on various tasks demonstrate that FreConv-equipped networks consistently outperform state-of-the-art baselines.
Efficient Masked Autoencoders with Self-Consistency
Feb 28, 2023
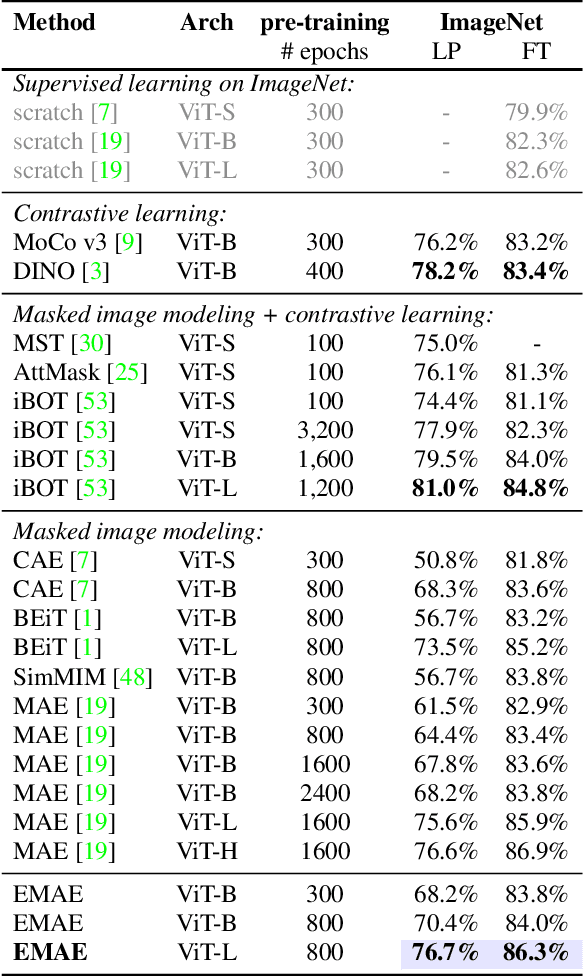
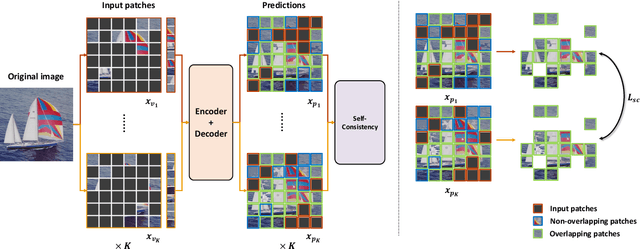
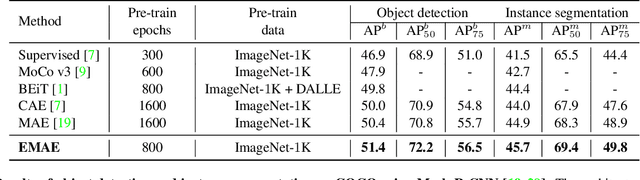
Inspired by masked language modeling (MLM) in natural language processing, masked image modeling (MIM) has been recognized as a strong and popular self-supervised pre-training method in computer vision. However, its high random mask ratio would result in two serious problems: 1) the data are not efficiently exploited, which brings inefficient pre-training (\eg, 1600 epochs for MAE $vs.$ 300 epochs for the supervised), and 2) the high uncertainty and inconsistency of the pre-trained model, \ie, the prediction of the same patch may be inconsistent under different mask rounds. To tackle these problems, we propose efficient masked autoencoders with self-consistency (EMAE), to improve the pre-training efficiency and increase the consistency of MIM. In particular, we progressively divide the image into K non-overlapping parts, each of which is generated by a random mask and has the same mask ratio. Then the MIM task is conducted parallelly on all parts in an iteration and generates predictions. Besides, we design a self-consistency module to further maintain the consistency of predictions of overlapping masked patches among parts. Overall, the proposed method is able to exploit the data more efficiently and obtains reliable representations. Experiments on ImageNet show that EMAE achieves even higher results with only 300 pre-training epochs under ViT-Base than MAE (1600 epochs). EMAE also consistently obtains state-of-the-art transfer performance on various downstream tasks, like object detection, and semantic segmentation.
Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks
Sep 28, 2022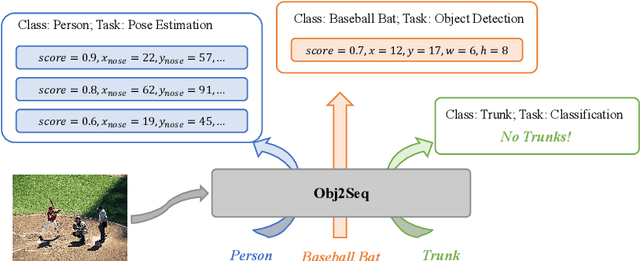
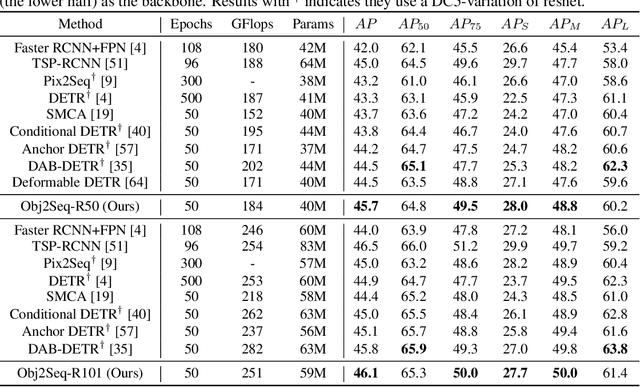
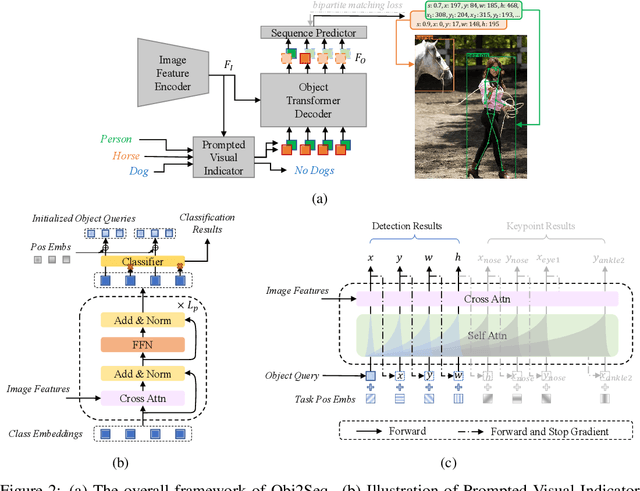
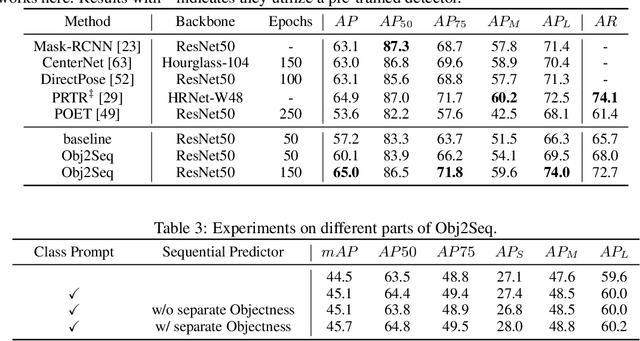
Visual tasks vary a lot in their output formats and concerned contents, therefore it is hard to process them with an identical structure. One main obstacle lies in the high-dimensional outputs in object-level visual tasks. In this paper, we propose an object-centric vision framework, Obj2Seq. Obj2Seq takes objects as basic units, and regards most object-level visual tasks as sequence generation problems of objects. Therefore, these visual tasks can be decoupled into two steps. First recognize objects of given categories, and then generate a sequence for each of these objects. The definition of the output sequences varies for different tasks, and the model is supervised by matching these sequences with ground-truth targets. Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks. When experimenting on MS COCO, Obj2Seq achieves 45.7% AP on object detection, 89.0% AP on multi-label classification and 65.0% AP on human pose estimation. These results demonstrate its potential to be generally applied to different visual tasks. Code has been made available at: https://github.com/CASIA-IVA-Lab/Obj2Seq.
Transfering Low-Frequency Features for Domain Adaptation
Aug 31, 2022

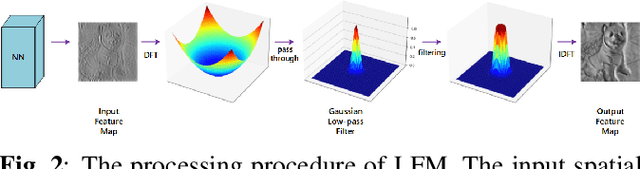

Previous unsupervised domain adaptation methods did not handle the cross-domain problem from the perspective of frequency for computer vision. The images or feature maps of different domains can be decomposed into the low-frequency component and high-frequency component. This paper proposes the assumption that low-frequency information is more domain-invariant while the high-frequency information contains domain-related information. Hence, we introduce an approach, named low-frequency module (LFM), to extract domain-invariant feature representations. The LFM is constructed with the digital Gaussian low-pass filter. Our method is easy to implement and introduces no extra hyperparameter. We design two effective ways to utilize the LFM for domain adaptation, and our method is complementary to other existing methods and formulated as a plug-and-play unit that can be combined with these methods. Experimental results demonstrate that our LFM outperforms state-of-the-art methods for various computer vision tasks, including image classification and object detection.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Mar 14, 2022Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP), a novel self-supervised framework to learn versatile visual representations on either single-centric-object or non-iconic dataset. The framework takes into account the representation learning at three levels: 1) the similarity of scene-scene, 2) the correlation of scene-instance, 3) the discrimination of instance-instance. During the learning, we adopt the optimal transport algorithm to automatically measure the discrimination of instances. Massive experiments show that UniVIP pre-trained on non-iconic COCO achieves state-of-the-art transfer performance on a variety of downstream tasks, such as image classification, semi-supervised learning, object detection and segmentation. Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
MST: Masked Self-Supervised Transformer for Visual Representation
Jun 10, 2021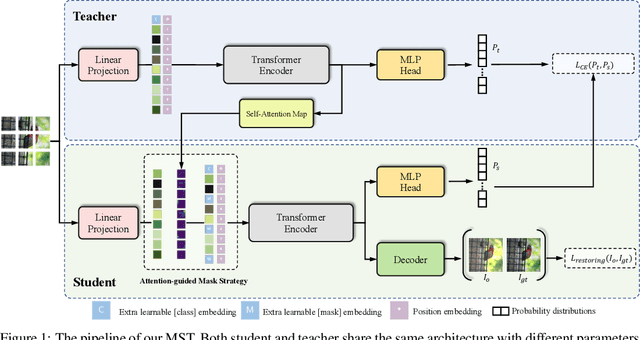
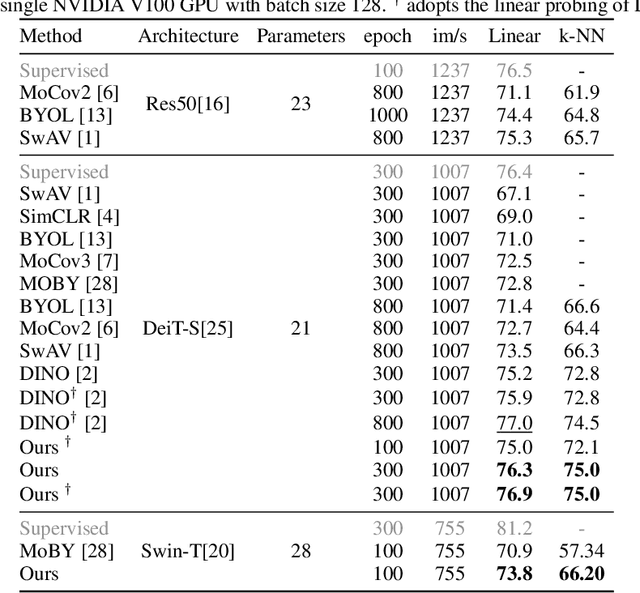

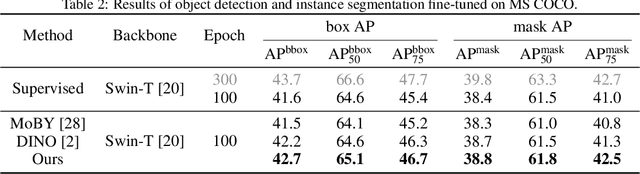
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the high-level feature and learning representation from a global perspective, which may fail to transfer to the downstream dense prediction tasks focusing on local features. In this paper, we present a novel Masked Self-supervised Transformer approach named MST, which can explicitly capture the local context of an image while preserving the global semantic information. Specifically, inspired by the Masked Language Modeling (MLM) in NLP, we propose a masked token strategy based on the multi-head self-attention map, which dynamically masks some tokens of local patches without damaging the crucial structure for self-supervised learning. More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks. The experiments on multiple datasets demonstrate the effectiveness and generality of the proposed method. For instance, MST achieves Top-1 accuracy of 76.9% with DeiT-S only using 300-epoch pre-training by linear evaluation, which outperforms supervised methods with the same epoch by 0.4% and its comparable variant DINO by 1.0\%. For dense prediction tasks, MST also achieves 42.7% mAP on MS COCO object detection and 74.04% mIoU on Cityscapes segmentation only with 100-epoch pre-training.