 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityDrive: Breaking Time Limits in Driving World Models
Dec 02, 2024



Autonomous driving systems struggle with complex scenarios due to limited access to diverse, extensive, and out-of-distribution driving data which are critical for safe navigation. World models offer a promising solution to this challenge; however, current driving world models are constrained by short time windows and limited scenario diversity. To bridge this gap, we introduce InfinityDrive, the first driving world model with exceptional generalization capabilities, delivering state-of-the-art performance in high fidelity, consistency, and diversity with minute-scale video generation. InfinityDrive introduces an efficient spatio-temporal co-modeling module paired with an extended temporal training strategy, enabling high-resolution (576$\times$1024) video generation with consistent spatial and temporal coherence. By incorporating memory injection and retention mechanisms alongside an adaptive memory curve loss to minimize cumulative errors, achieving consistent video generation lasting over 1500 frames (approximately 2 minutes). Comprehensive experiments in multiple datasets validate InfinityDrive's ability to generate complex and varied scenarios, highlighting its potential as a next-generation driving world model built for the evolving demands of autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/InfinityDrive/page.html
AutoSampling: Search for Effective Data Sampling Schedules
May 28, 2021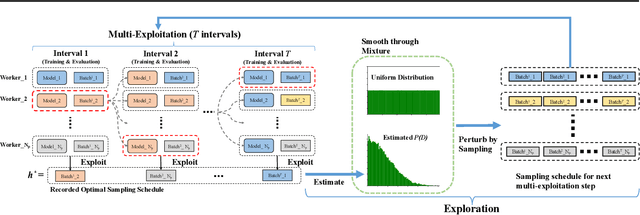
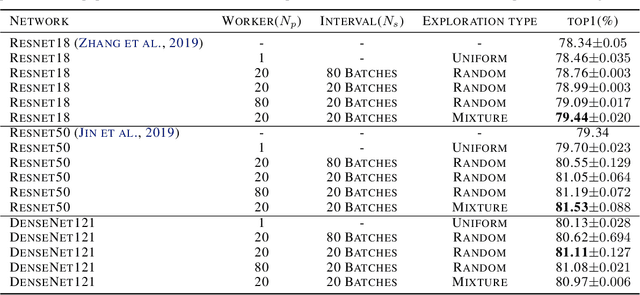

Data sampling acts as a pivotal role in training deep learning models. However, an effective sampling schedule is difficult to learn due to the inherently high dimension of parameters in learning the sampling schedule. In this paper, we propose an AutoSampling method to automatically learn sampling schedules for model training, which consists of the multi-exploitation step aiming for optimal local sampling schedules and the exploration step for the ideal sampling distribution. More specifically, we achieve sampling schedule search with shortened exploitation cycle to provide enough supervision. In addition, we periodically estimate the sampling distribution from the learned sampling schedules and perturb it to search in the distribution space. The combination of two searches allows us to learn a robust sampling schedule. We apply our AutoSampling method to a variety of image classification tasks illustrating the effectiveness of the proposed method.
* Automl for sampling firstly without any assumpation
Efficient Transfer Learning via Joint Adaptation of Network Architecture and Weight
May 19, 2021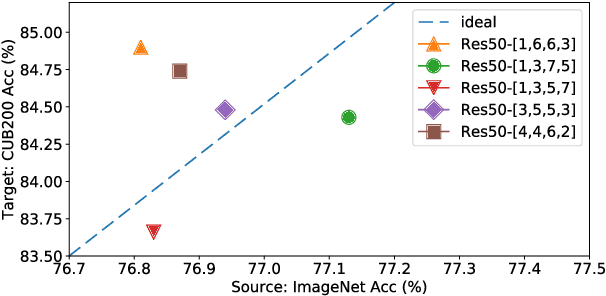
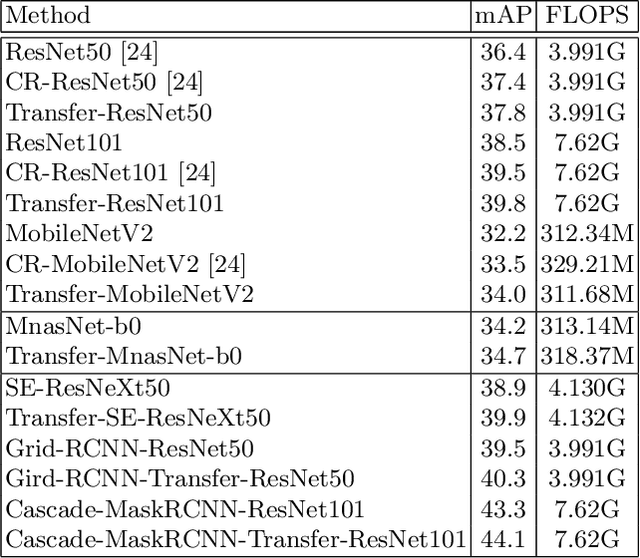
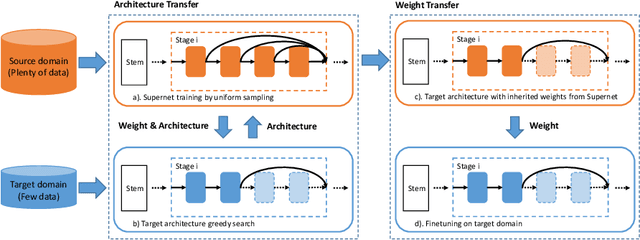
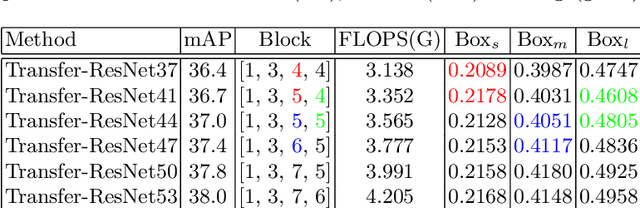
Transfer learning can boost the performance on the targettask by leveraging the knowledge of the source domain. Recent worksin neural architecture search (NAS), especially one-shot NAS, can aidtransfer learning by establishing sufficient network search space. How-ever, existing NAS methods tend to approximate huge search spaces byexplicitly building giant super-networks with multiple sub-paths, anddiscard super-network weights after a child structure is found. Both thecharacteristics of existing approaches causes repetitive network trainingon source tasks in transfer learning. To remedy the above issues, we re-duce the super-network size by randomly dropping connection betweennetwork blocks while embedding a larger search space. Moreover, wereuse super-network weights to avoid redundant training by proposinga novel framework consisting of two modules, the neural architecturesearch module for architecture transfer and the neural weight searchmodule for weight transfer. These two modules conduct search on thetarget task based on a reduced super-networks, so we only need to trainonce on the source task. We experiment our framework on both MS-COCO and CUB-200 for the object detection and fine-grained imageclassification tasks, and show promising improvements with onlyO(CN)super-network complexity.
* NAS is one part of transfer learning