 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transfer Learning via Joint Adaptation of Network Architecture and Weight
Paper and Code
May 19, 2021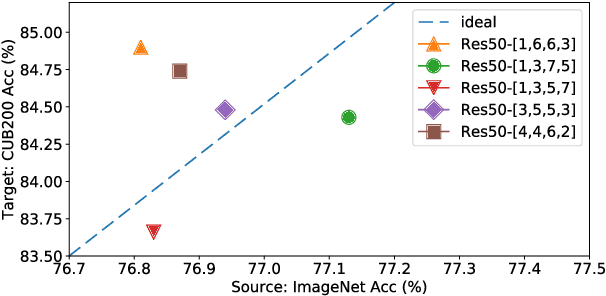
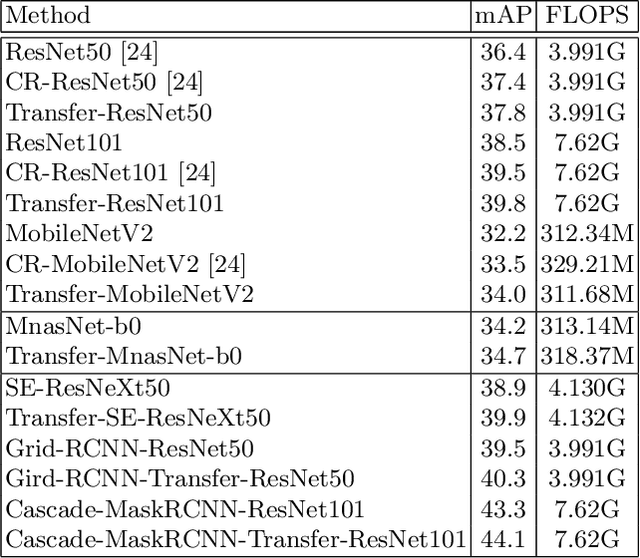
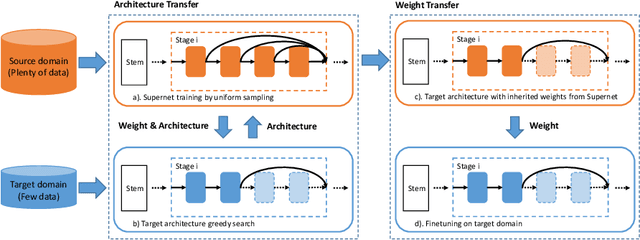
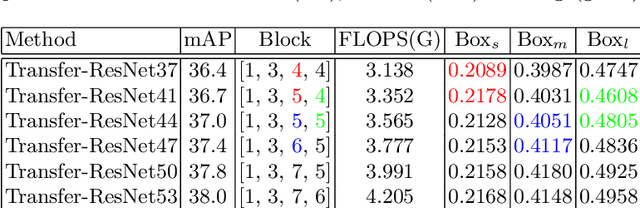
Transfer learning can boost the performance on the targettask by leveraging the knowledge of the source domain. Recent worksin neural architecture search (NAS), especially one-shot NAS, can aidtransfer learning by establishing sufficient network search space. How-ever, existing NAS methods tend to approximate huge search spaces byexplicitly building giant super-networks with multiple sub-paths, anddiscard super-network weights after a child structure is found. Both thecharacteristics of existing approaches causes repetitive network trainingon source tasks in transfer learning. To remedy the above issues, we re-duce the super-network size by randomly dropping connection betweennetwork blocks while embedding a larger search space. Moreover, wereuse super-network weights to avoid redundant training by proposinga novel framework consisting of two modules, the neural architecturesearch module for architecture transfer and the neural weight searchmodule for weight transfer. These two modules conduct search on thetarget task based on a reduced super-networks, so we only need to trainonce on the source task. We experiment our framework on both MS-COCO and CUB-200 for the object detection and fine-grained imageclassification tasks, and show promising improvements with onlyO(CN)super-network complexity.