 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-adaptive Gated Convolution and Bi-directional Progressive Fusion Network for Depth Completion
Paper and Code
Jan 15, 2024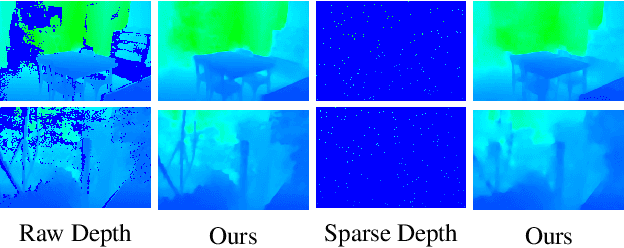



Depth completion is a critical task for handling depth images with missing pixels, which can negatively impact further applications. Recent approaches have utilized Convolutional Neural Networks (CNNs) to reconstruct depth images with the assistance of color images. However, vanilla convolution has non-negligible drawbacks in handling missing pixels. To solve this problem, we propose a new model for depth completion based on an encoder-decoder structure. Our model introduces two key components: the Mask-adaptive Gated Convolution (MagaConv) architecture and the Bi-directional Progressive Fusion (BP-Fusion) module. The MagaConv architecture is designed to acquire precise depth features by modulating convolution operations with iteratively updated masks, while the BP-Fusion module progressively integrates depth and color features, utilizing consecutive bi-directional fusion structures in a global perspective. Extensive experiments on popular benchmarks, including NYU-Depth V2, DIML, and SUN RGB-D, demonstrate the superiority of our model over state-of-the-art methods. We achieved remarkable performance in completing depth maps and outperformed existing approaches in terms of accuracy and reliability.