 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyRN : A Real-Time Closed Loop approach from Monocular Vision
Paper and Code
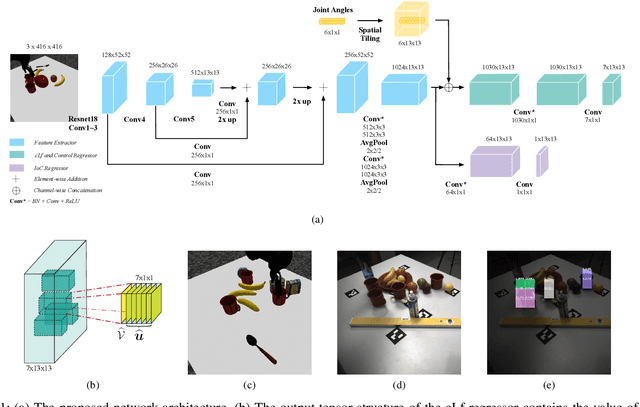
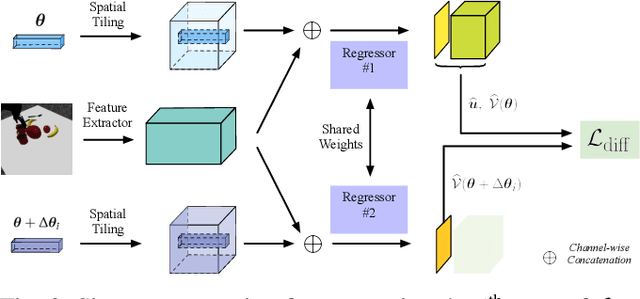
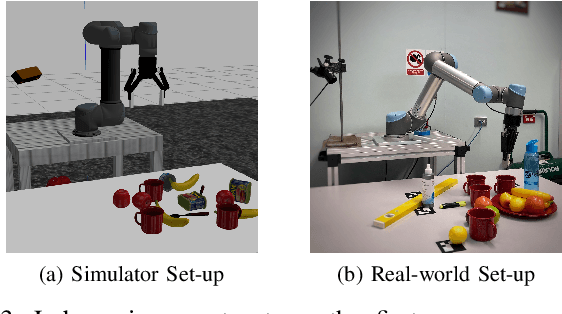
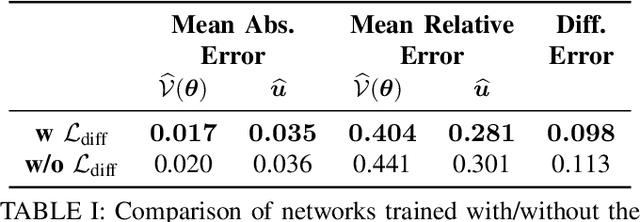
We propose a closed-loop, multi-instance control algorithm for visually guided reaching based on novel learning principles. A control Lyapunov function methodology is used to design a reaching action for a complex multi-instance task in the case where full state information (poses of all potential reaching points) is available. The proposed algorithm uses monocular vision and manipulator joint angles as the input to a deep convolution neural network to predict the value of the control Lyapunov function (cLf) and corresponding velocity control. The resulting network output is used in real-time as visual control for the grasping task with the multi-instance capability emerging naturally from the design of the control Lyapunov function. We demonstrate the proposed algorithm grasping mugs (textureless and symmetric objects) on a table-top from an over-the-shoulder monocular RGB camera. The manipulator dynamically converges to the best-suited target among multiple identical instances from any random initial pose within the workspace. The system trained with only simulated data is able to achieve 90.3% grasp success rate in the real-world experiments with up to 85Hz closed-loop control on one GTX 1080Ti GPU and significantly outperforms a Pose-Based-Visual-Servo (PBVS) grasping system adapted from a state-of-the-art single shot RGB 6D pose estimation algorithm. A key contribution of the paper is the inclusion of a first-order differential constraint associated with the cLf as a regularisation term during learning, and we provide evidence that this leads to more robust and reliable reaching/grasping performance than vanilla regression on general control inputs.