 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Multi-View Stereo with Depth Foundation Model in the Absence of Real-World Labels
Paper and Code
Apr 16, 2025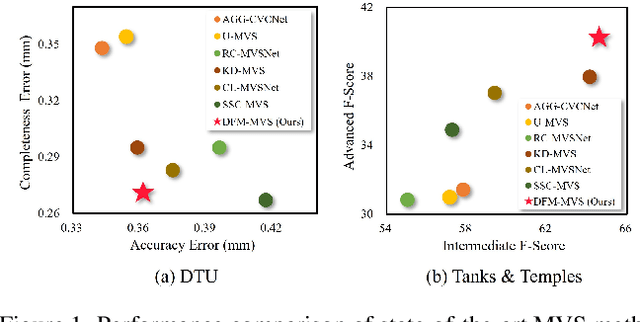



Learning-based Multi-View Stereo (MVS) methods have made remarkable progress in recent years. However, how to effectively train the network without using real-world labels remains a challenging problem. In this paper, driven by the recent advancements of vision foundation models, a novel method termed DFM-MVS, is proposed to leverage the depth foundation model to generate the effective depth prior, so as to boost MVS in the absence of real-world labels. Specifically, a depth prior-based pseudo-supervised training mechanism is developed to simulate realistic stereo correspondences using the generated depth prior, thereby constructing effective supervision for the MVS network. Besides, a depth prior-guided error correction strategy is presented to leverage the depth prior as guidance to mitigate the error propagation problem inherent in the widely-used coarse-to-fine network structure. Experimental results on DTU and Tanks & Temples datasets demonstrate that the proposed DFM-MVS significantly outperforms existing MVS methods without using real-world labels.