 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Koopman Network
Nov 17, 2022Koopman operator theory is receiving increased attention due to its promise to linearize nonlinear dynamics. Neural networks that are developed to represent Koopman operators have shown great success thanks to their ability to approximate arbitrarily complex functions. However, despite their great potential, they typically require large training data-sets either from measurements of a real system or from high-fidelity simulations. In this work, we propose a novel architecture inspired by physics-informed neural networks, which leverage automatic differentiation to impose the underlying physical laws via soft penalty constraints during model training. We demonstrate that it not only reduces the need of large training data-sets, but also maintains high effectiveness in approximating Koopman eigenfunctions.
MEMOIR: Multi-class Extreme Classification with Inexact Margin
Nov 24, 2018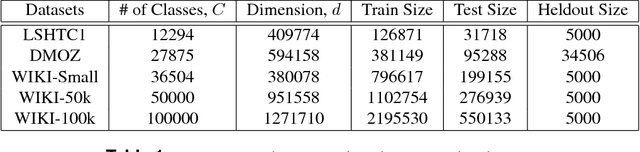
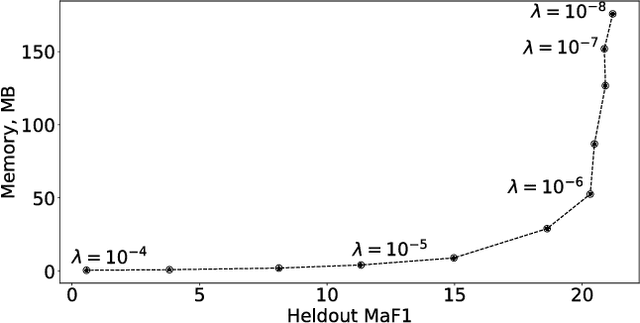

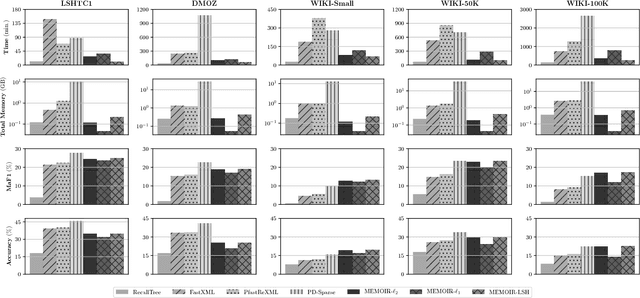
Multi-class classification with a very large number of classes, or extreme classification, is a challenging problem from both statistical and computational perspectives. Most of the classical approaches to multi-class classification, including one-vs-rest or multi-class support vector machines, require the exact estimation of the classifier's margin, at both the training and the prediction steps making them intractable in extreme classification scenarios. In this paper, we study the impact of computing an approximate margin using nearest neighbor (ANN) search structures combined with locality-sensitive hashing (LSH). This approximation allows to dramatically reduce both the training and the prediction time without a significant loss in performance. We theoretically prove that this approximation does not lead to a significant loss of the risk of the model and provide empirical evidence over five publicly available large scale datasets, showing that the proposed approach is highly competitive with respect to state-of-the-art approaches on time, memory and performance measures.
Towards Large-Scale Exploratory Search over Heterogeneous Sources
Nov 20, 2018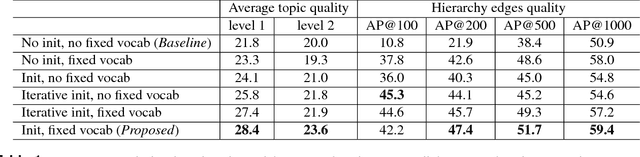
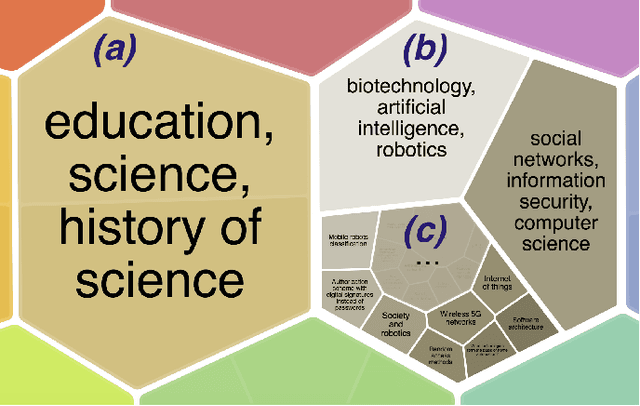

Since time immemorial, people have been looking for ways to organize scientific knowledge into some systems to facilitate search and discovery of new ideas. The problem was partially solved in the pre-Internet era using library classifications, but nowadays it is nearly impossible to classify all scientific and popular scientific knowledge manually. There is a clear gap between the diversity and the amount of data available on the Internet and the algorithms for automatic structuring of such data. In our preliminary study, we approach the problem of knowledge discovery on web-scale data with diverse text sources and propose an algorithm to aggregate multiple collections into a single hierarchical topic model. We implement a web service named Rysearch to demonstrate the concept of topical exploratory search and make it available online.