 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMOS: Grounding Moving Object Segmentation in 3D Space and Time
May 28, 2026Moving Object Segmentation (MOS) aims to discover, segment, and track objects that move independently of the camera. Current MOS methods, however, exhibit two fundamental limitations: they rely on pre-computed 2D auxiliary modalities such as optical flow or point trajectories that lack 3D geometric information, and they treat motion as a sequence-level attribute, overlooking the instantaneous motion state of each object. We address both by grounding MOS in 3D space and time, and propose GMOS, a framework that operates directly on RGB video to produce 3D-aware, temporally fine-grained segmentation of multiple moving objects, alongside a foreground--background variant GMOS-S for faster deployment. To support training and evaluation in this regime, we curate GMOS-2K, a dataset of 2,210 real-world videos with per-object temporal motion annotations drawn from five established Video Object Segmentation (VOS) benchmarks, and formalise MOS-I ("I" for instantaneous), a temporally fine-grained evaluation protocol with three complementary metrics. GMOS achieves state-of-the-art results across MOS, MOS-I, and Unsupervised VOS benchmarks, while running significantly faster than prior multi-object MOS methods and supporting online inference for streaming deployment.
Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025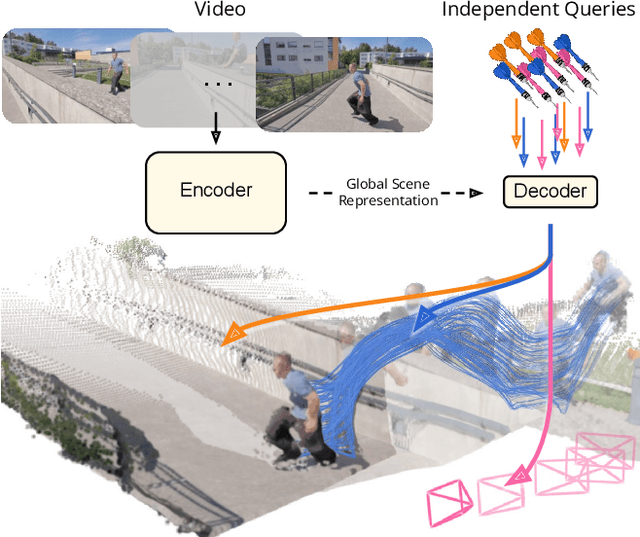

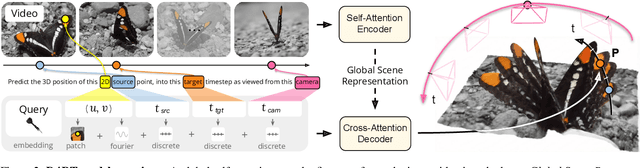
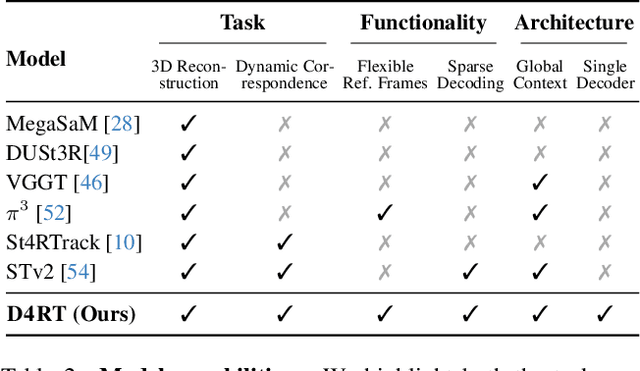
Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Shot-by-Shot: Film-Grammar-Aware Training-Free Audio Description Generation
Apr 01, 2025Our objective is the automatic generation of Audio Descriptions (ADs) for edited video material, such as movies and TV series. To achieve this, we propose a two-stage framework that leverages "shots" as the fundamental units of video understanding. This includes extending temporal context to neighbouring shots and incorporating film grammar devices, such as shot scales and thread structures, to guide AD generation. Our method is compatible with both open-source and proprietary Visual-Language Models (VLMs), integrating expert knowledge from add-on modules without requiring additional training of the VLMs. We achieve state-of-the-art performance among all prior training-free approaches and even surpass fine-tuned methods on several benchmarks. To evaluate the quality of predicted ADs, we introduce a new evaluation measure -- an action score -- specifically targeted to assessing this important aspect of AD. Additionally, we propose a novel evaluation protocol that treats automatic frameworks as AD generation assistants and asks them to generate multiple candidate ADs for selection.
FacaDiffy: Inpainting Unseen Facade Parts Using Diffusion Models
Feb 20, 2025



High-detail semantic 3D building models are frequently utilized in robotics, geoinformatics, and computer vision. One key aspect of creating such models is employing 2D conflict maps that detect openings' locations in building facades. Yet, in reality, these maps are often incomplete due to obstacles encountered during laser scanning. To address this challenge, we introduce FacaDiffy, a novel method for inpainting unseen facade parts by completing conflict maps with a personalized Stable Diffusion model. Specifically, we first propose a deterministic ray analysis approach to derive 2D conflict maps from existing 3D building models and corresponding laser scanning point clouds. Furthermore, we facilitate the inpainting of unseen facade objects into these 2D conflict maps by leveraging the potential of personalizing a Stable Diffusion model. To complement the scarcity of real-world training data, we also develop a scalable pipeline to produce synthetic conflict maps using random city model generators and annotated facade images. Extensive experiments demonstrate that FacaDiffy achieves state-of-the-art performance in conflict map completion compared to various inpainting baselines and increases the detection rate by $22\%$ when applying the completed conflict maps for high-definition 3D semantic building reconstruction. The code is be publicly available in the corresponding GitHub repository: https://github.com/ThomasFroech/InpaintingofUnseenFacadeObjects
AutoAD-Zero: A Training-Free Framework for Zero-Shot Audio Description
Jul 22, 2024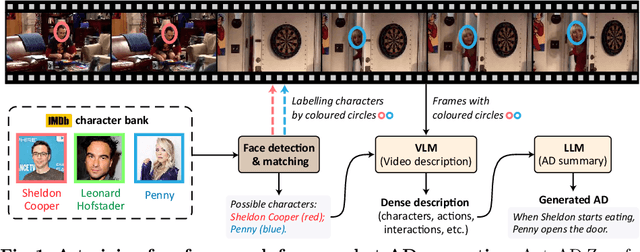

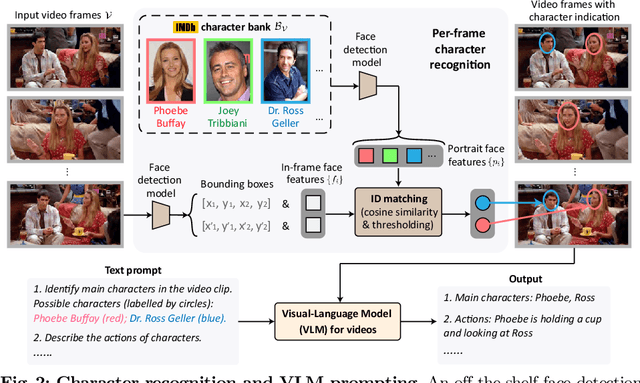

Our objective is to generate Audio Descriptions (ADs) for both movies and TV series in a training-free manner. We use the power of off-the-shelf Visual-Language Models (VLMs) and Large Language Models (LLMs), and develop visual and text prompting strategies for this task. Our contributions are three-fold: (i) We demonstrate that a VLM can successfully name and refer to characters if directly prompted with character information through visual indications without requiring any fine-tuning; (ii) A two-stage process is developed to generate ADs, with the first stage asking the VLM to comprehensively describe the video, followed by a second stage utilising a LLM to summarise dense textual information into one succinct AD sentence; (iii) A new dataset for TV audio description is formulated. Our approach, named AutoAD-Zero, demonstrates outstanding performance (even competitive with some models fine-tuned on ground truth ADs) in AD generation for both movies and TV series, achieving state-of-the-art CRITIC scores.
Moving Object Segmentation: All You Need Is SAM
Apr 18, 2024


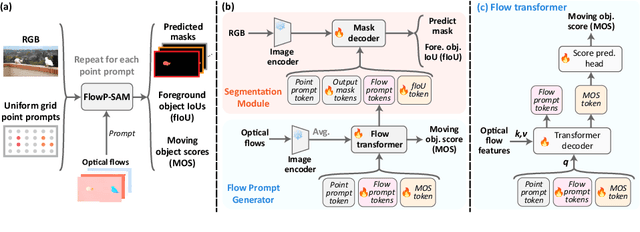
The objective of this paper is motion segmentation -- discovering and segmenting the moving objects in a video. This is a much studied area with numerous careful,and sometimes complex, approaches and training schemes including: self-supervised learning, learning from synthetic datasets, object-centric representations, amodal representations, and many more. Our interest in this paper is to determine if the Segment Anything model (SAM) can contribute to this task. We investigate two models for combining SAM with optical flow that harness the segmentation power of SAM with the ability of flow to discover and group moving objects. In the first model, we adapt SAM to take optical flow, rather than RGB, as an input. In the second, SAM takes RGB as an input, and flow is used as a segmentation prompt. These surprisingly simple methods, without any further modifications, outperform all previous approaches by a considerable margin in both single and multi-object benchmarks. We also extend these frame-level segmentations to sequence-level segmentations that maintain object identity. Again, this simple model outperforms previous methods on multiple video object segmentation benchmarks.
Appearance-based Refinement for Object-Centric Motion Segmentation
Dec 18, 2023



The goal of this paper is to discover, segment, and track independently moving objects in complex visual scenes. Previous approaches have explored the use of optical flow for motion segmentation, leading to imperfect predictions due to partial motion, background distraction, and object articulations and interactions. To address this issue, we introduce an appearance-based refinement method that leverages temporal consistency in video streams to correct inaccurate flow-based proposals. Our approach involves a simple selection mechanism that identifies accurate flow-predicted masks as exemplars, and an object-centric architecture that refines problematic masks based on exemplar information. The model is pre-trained on synthetic data and then adapted to real-world videos in a self-supervised manner, eliminating the need for human annotations. Its performance is evaluated on multiple video segmentation benchmarks, including DAVIS, YouTubeVOS, SegTrackv2, and FBMS-59. We achieve competitive performance on single-object segmentation, while significantly outperforming existing models on the more challenging problem of multi-object segmentation. Finally, we investigate the benefits of using our model as a prompt for a per-frame Segment Anything Model.
SHAP-EDITOR: Instruction-guided Latent 3D Editing in Seconds
Dec 14, 2023



We propose a novel feed-forward 3D editing framework called Shap-Editor. Prior research on editing 3D objects primarily concentrated on editing individual objects by leveraging off-the-shelf 2D image editing networks. This is achieved via a process called distillation, which transfers knowledge from the 2D network to 3D assets. Distillation necessitates at least tens of minutes per asset to attain satisfactory editing results, and is thus not very practical. In contrast, we ask whether 3D editing can be carried out directly by a feed-forward network, eschewing test-time optimisation. In particular, we hypothesise that editing can be greatly simplified by first encoding 3D objects in a suitable latent space. We validate this hypothesis by building upon the latent space of Shap-E. We demonstrate that direct 3D editing in this space is possible and efficient by building a feed-forward editor network that only requires approximately one second per edit. Our experiments show that Shap-Editor generalises well to both in-distribution and out-of-distribution 3D assets with different prompts, exhibiting comparable performance with methods that carry out test-time optimisation for each edited instance.
Segmenting Moving Objects via an Object-Centric Layered Representation
Jul 05, 2022


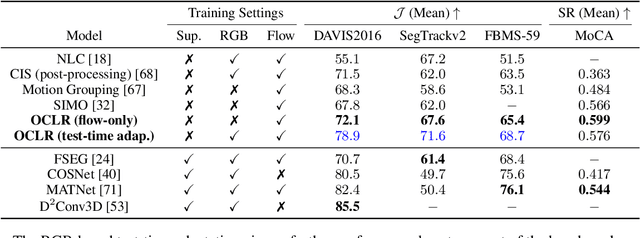
The objective of this paper is a model that is able to discover, track and segment multiple moving objects in a video. We make four contributions: First, we introduce an object-centric segmentation model with a depth-ordered layer representation. This is implemented using a variant of the transformer architecture that ingests optical flow, where each query vector specifies an object and its layer for the entire video. The model can effectively discover multiple moving objects and handle mutual occlusions; Second, we introduce a scalable pipeline for generating synthetic training data with multiple objects, significantly reducing the requirements for labour-intensive annotations, and supporting Sim2Real generalisation; Third, we show that the model is able to learn object permanence and temporal shape consistency, and is able to predict amodal segmentation masks; Fourth, we evaluate the model on standard video segmentation benchmarks, DAVIS, MoCA, SegTrack, FBMS-59, and achieve state-of-the-art unsupervised segmentation performance, even outperforming several supervised approaches. With test-time adaptation, we observe further performance boosts.