 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAN We Flow? Advancing Robotic Manipulation with 3D Flow Matching via KAN & RWKV
Feb 01, 2026Diffusion-based visuomotor policies excel at modeling action distributions but are inference-inefficient, since recursively denoising from noise to policy requires many steps and heavy UNet backbones, which hinders deployment on resource-constrained robots. Flow matching alleviates the sampling burden by learning a one-step vector field, yet prior implementations still inherit large UNet-style architectures. In this work, we present KAN-We-Flow, a flow-matching policy that draws on recent advances in Receptance Weighted Key Value (RWKV) and Kolmogorov-Arnold Networks (KAN) from vision to build a lightweight and highly expressive backbone for 3D manipulation. Concretely, we introduce an RWKV-KAN block: an RWKV first performs efficient time/channel mixing to propagate task context, and a subsequent GroupKAN layer applies learnable spline-based, groupwise functional mappings to perform feature-wise nonlinear calibration of the action mapping on RWKV outputs. Moreover, we introduce an Action Consistency Regularization (ACR), a lightweight auxiliary loss that enforces alignment between predicted action trajectories and expert demonstrations via Euler extrapolation, providing additional supervision to stabilize training and improve policy precision. Without resorting to large UNets, our design reduces parameters by 86.8\%, maintains fast runtime, and achieves state-of-the-art success rates on Adroit, Meta-World, and DexArt benchmarks. Our project page can be viewed in \href{https://zhihaochen-2003.github.io/KAN-We-Flow.github.io/}{\textcolor{red}{link}}
Spectral Enhancement and Pseudo-Anchor Guidance for Infrared-Visible Person Re-Identification
Dec 26, 2024



The development of deep learning has facilitated the application of person re-identification (ReID) technology in intelligent security. Visible-infrared person re-identification (VI-ReID) aims to match pedestrians across infrared and visible modality images enabling 24-hour surveillance. Current studies relying on unsupervised modality transformations as well as inefficient embedding constraints to bridge the spectral differences between infrared and visible images, however, limit their potential performance. To tackle the limitations of the above approaches, this paper introduces a simple yet effective Spectral Enhancement and Pseudo-anchor Guidance Network, named SEPG-Net. Specifically, we propose a more homogeneous spectral enhancement scheme based on frequency domain information and greyscale space, which avoids the information loss typically caused by inefficient modality transformations. Further, a Pseudo Anchor-guided Bidirectional Aggregation (PABA) loss is introduced to bridge local modality discrepancies while better preserving discriminative identity embeddings. Experimental results on two public benchmark datasets demonstrate the superior performance of SEPG-Net against other state-of-the-art methods. The code is available at https://github.com/1024AILab/ReID-SEPG.
DAPONet: A Dual Attention and Partially Overparameterized Network for Real-Time Road Damage Detection
Sep 03, 2024Current road damage detection methods, relying on manual inspections or sensor-mounted vehicles, are inefficient, limited in coverage, and often inaccurate, especially for minor damages, leading to delays and safety hazards. To address these issues and enhance real-time road damage detection using street view image data (SVRDD), we propose DAPONet, a model incorporating three key modules: a dual attention mechanism combining global and local attention, a multi-scale partial over-parameterization module, and an efficient downsampling module. DAPONet achieves a mAP50 of 70.1% on the SVRDD dataset, outperforming YOLOv10n by 10.4%, while reducing parameters to 1.6M and FLOPs to 1.7G, representing reductions of 41% and 80%, respectively. On the MS COCO2017 val dataset, DAPONet achieves an mAP50-95 of 33.4%, 0.8% higher than EfficientDet-D1, with a 74% reduction in both parameters and FLOPs.
Features Reconstruction Disentanglement Cloth-Changing Person Re-Identification
Jul 15, 2024


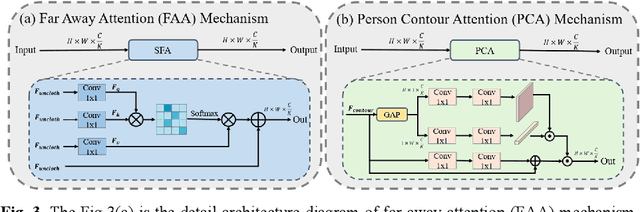
Cloth-changing person re-identification (CC-ReID) aims to retrieve specific pedestrians in a cloth-changing scenario. Its main challenge is to disentangle the clothing-related and clothing-unrelated features. Most existing approaches force the model to learn clothing-unrelated features by changing the color of the clothes. However, due to the lack of ground truth, these methods inevitably introduce noise, which destroys the discriminative features and leads to an uncontrollable disentanglement process. In this paper, we propose a new person re-identification network called features reconstruction disentanglement ReID (FRD-ReID), which can controllably decouple the clothing-unrelated and clothing-related features. Specifically, we first introduce the human parsing mask as the ground truth of the reconstruction process. At the same time, we propose the far away attention (FAA) mechanism and the person contour attention (PCA) mechanism for clothing-unrelated features and pedestrian contour features to improve the feature reconstruction efficiency. In the testing phase, we directly discard the clothing-related features for inference,which leads to a controllable disentanglement process. We conducted extensive experiments on the PRCC, LTCC, and Vc-Clothes datasets and demonstrated that our method outperforms existing state-of-the-art methods.
MambaUIE&SR: Unraveling the Ocean's Secrets with Only 2.8 FLOPs
Apr 22, 2024


Underwater Image Enhancement (UIE) techniques aim to address the problem of underwater image degradation due to light absorption and scattering. In recent years, both Convolution Neural Network (CNN)-based and Transformer-based methods have been widely explored. In addition, combining CNN and Transformer can effectively combine global and local information for enhancement. However, this approach is still affected by the secondary complexity of the Transformer and cannot maximize the performance. Recently, the state-space model (SSM) based architecture Mamba has been proposed, which excels in modeling long distances while maintaining linear complexity. This paper explores the potential of this SSM-based model for UIE from both efficiency and effectiveness perspectives. However, the performance of directly applying Mamba is poor because local fine-grained features, which are crucial for image enhancement, cannot be fully utilized. Specifically, we customize the MambaUIE architecture for efficient UIE. Specifically, we introduce visual state space (VSS) blocks to capture global contextual information at the macro level while mining local information at the micro level. Also, for these two kinds of information, we propose a Dynamic Interaction Block (DIB) and Spatial feed-forward Network (SGFN) for intra-block feature aggregation. MambaUIE is able to efficiently synthesize global and local information and maintains a very small number of parameters with high accuracy. Experiments on UIEB datasets show that our method reduces GFLOPs by 67.4% (2.715G) relative to the SOTA method. To the best of our knowledge, this is the first UIE model constructed based on SSM that breaks the limitation of FLOPs on accuracy in UIE. The official repository of MambaUIE at https://github.com/1024AILab/MambaUIE.
Part-Attention Based Model Make Occluded Person Re-Identification Stronger
Apr 13, 2024The goal of occluded person re-identification (ReID) is to retrieve specific pedestrians in occluded situations. However, occluded person ReID still suffers from background clutter and low-quality local feature representations, which limits model performance. In our research, we introduce a new framework called PAB-ReID, which is a novel ReID model incorporating part-attention mechanisms to tackle the aforementioned issues effectively. Firstly, we introduce the human parsing label to guide the generation of more accurate human part attention maps. In addition, we propose a fine-grained feature focuser for generating fine-grained human local feature representations while suppressing background interference. Moreover, We also design a part triplet loss to supervise the learning of human local features, which optimizes intra/inter-class distance. We conducted extensive experiments on specialized occlusion and regular ReID datasets, showcasing that our approach outperforms the existing state-of-the-art methods.
Occluded Cloth-Changing Person Re-Identification
Mar 15, 2024



Cloth-changing person re-identification aims to retrieve and identify spe-cific pedestrians by using cloth-unrelated features in person cloth-changing scenarios. However, pedestrian images captured by surveillance probes usually contain occlusions in real-world scenarios. The perfor-mance of existing cloth-changing person re-identification methods is sig-nificantly degraded due to the reduction of discriminative cloth-unrelated features caused by occlusion. We define cloth-changing person re-identification in occlusion scenarios as occluded cloth-changing person re-identification (Occ-CC-ReID), and to the best of our knowledge, we are the first to propose occluded cloth-changing person re-identification as a new task. We constructed two occluded cloth-changing person re-identification datasets: Occluded-PRCC and Occluded-LTCC. The da-tasets can be obtained from the following link: https://github.com/1024AILab/Occluded-Cloth-Changing-Person-Re-Identification.