 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes color modalities affect handwriting recognition? An empirical study on Persian handwritings using convolutional neural networks
Jul 22, 2023Most of the methods on handwritten recognition in the literature are focused and evaluated on Black and White (BW) image databases. In this paper we try to answer a fundamental question in document recognition. Using Convolutional Neural Networks (CNNs), as eye simulator, we investigate to see whether color modalities of handwritten digits and words affect their recognition accuracy or speed? To the best of our knowledge, so far this question has not been answered due to the lack of handwritten databases that have all three color modalities of handwritings. To answer this question, we selected 13,330 isolated digits and 62,500 words from a novel Persian handwritten database, which have three different color modalities and are unique in term of size and variety. Our selected datasets are divided into training, validation, and testing sets. Afterwards, similar conventional CNN models are trained with the training samples. While the experimental results on the testing set show that CNN on the BW digit and word images has a higher performance compared to the other two color modalities, in general there are no significant differences for network accuracy in different color modalities. Also, comparisons of training times in three color modalities show that recognition of handwritten digits and words in BW images using CNN is much more efficient.
Towards Robust Pattern Recognition: A Review
Jun 12, 2020

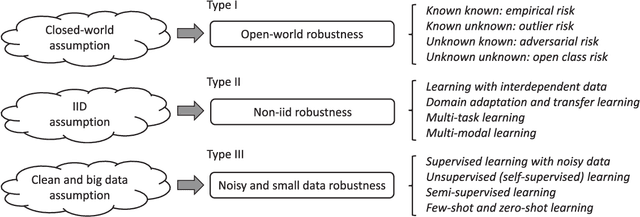
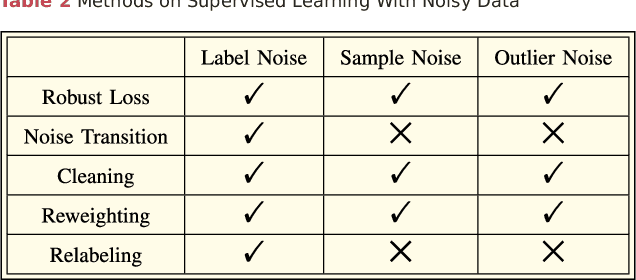
The accuracies for many pattern recognition tasks have increased rapidly year by year, achieving or even outperforming human performance. From the perspective of accuracy, pattern recognition seems to be a nearly-solved problem. However, once launched in real applications, the high-accuracy pattern recognition systems may become unstable and unreliable, due to the lack of robustness in open and changing environments. In this paper, we present a comprehensive review of research towards robust pattern recognition from the perspective of breaking three basic and implicit assumptions: closed-world assumption, independent and identically distributed assumption, and clean and big data assumption, which form the foundation of most pattern recognition models. Actually, our brain is robust at learning concepts continually and incrementally, in complex, open and changing environments, with different contexts, modalities and tasks, by showing only a few examples, under weak or noisy supervision. These are the major differences between human intelligence and machine intelligence, which are closely related to the above three assumptions. After witnessing the significant progress in accuracy improvement nowadays, this review paper will enable us to analyze the shortcomings and limitations of current methods and identify future research directions for robust pattern recognition.
Offline handwritten mathematical symbol recognition utilising deep learning
Oct 16, 2019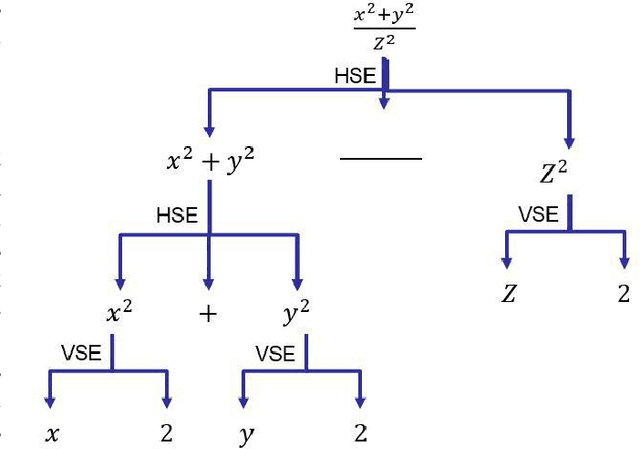
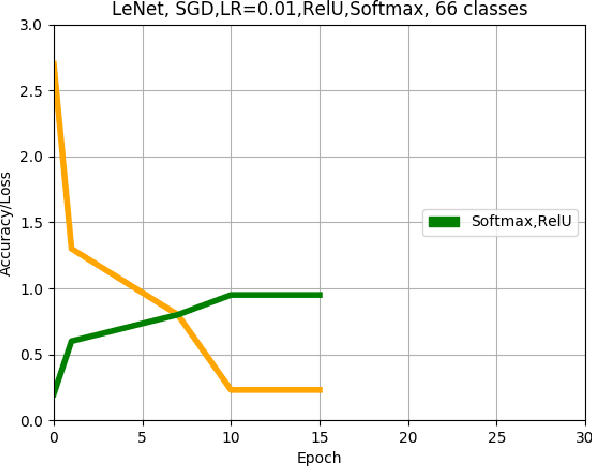
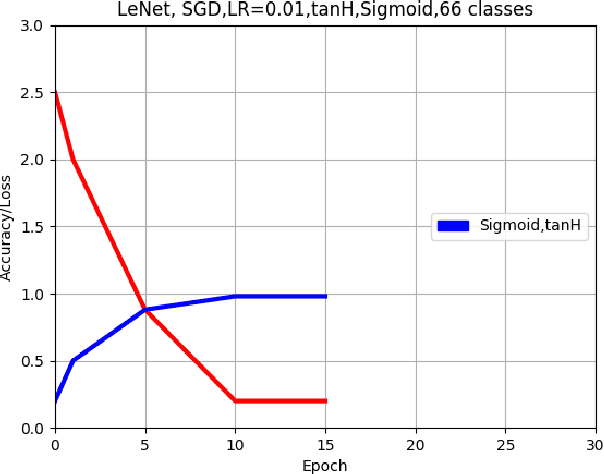
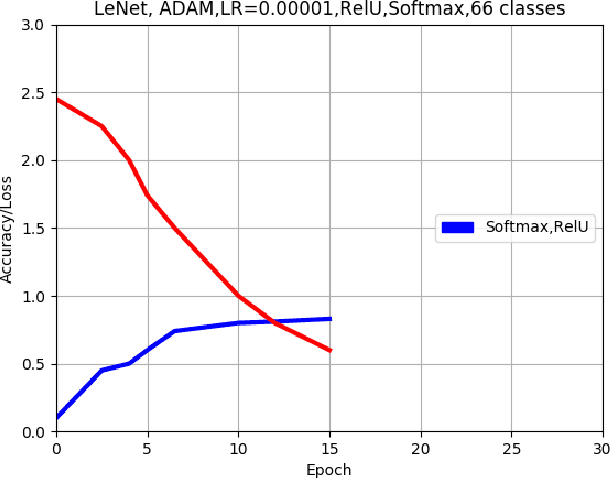
This paper describes an approach for offline recognition of handwritten mathematical symbols. The process of symbol recognition in this paper includes symbol segmentation and accurate classification for over 300 classes. Many multidimensional mathematical symbols need both horizontal and vertical projection to be segmented. However, some symbols do not permit to be projected and stop segmentation, such as the root symbol. Besides, many mathematical symbols are structurally similar, specifically in handwritten such as 0 and null. There are more than 300 Mathematical symbols. Therefore, designing an accurate classifier for more than 300 classes is required. This paper initially addresses the issue regarding segmentation using Simple Linear Iterative Clustering (SLIC). Experimental results indicate that the accuracy of the designed kNN classifier is 84% for salient, 57% Histogram of Oriented Gradient (HOG), 53% for Linear Binary Pattern (LBP) and finally 43% for pixel intensity of raw image for 66 classes. 87 classes using modified LeNet represents 90% accuracy. Finally, for 101 classes, SqueezeNet ac
Writer Identification Using Inexpensive Signal Processing Techniques
Dec 30, 2009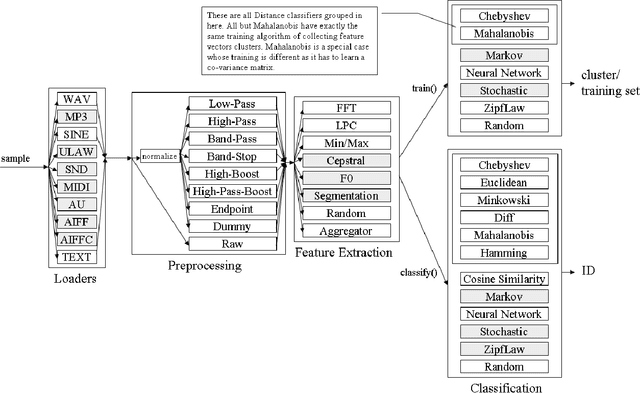
We propose to use novel and classical audio and text signal-processing and otherwise techniques for "inexpensive" fast writer identification tasks of scanned hand-written documents "visually". The "inexpensive" refers to the efficiency of the identification process in terms of CPU cycles while preserving decent accuracy for preliminary identification. This is a comparative study of multiple algorithm combinations in a pattern recognition pipeline implemented in Java around an open-source Modular Audio Recognition Framework (MARF) that can do a lot more beyond audio. We present our preliminary experimental findings in such an identification task. We simulate "visual" identification by "looking" at the hand-written document as a whole rather than trying to extract fine-grained features out of it prior classification.