 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic search for 100M+ galaxy images using AI-generated captions
Dec 12, 2025Finding scientifically interesting phenomena through slow, manual labeling campaigns severely limits our ability to explore the billions of galaxy images produced by telescopes. In this work, we develop a pipeline to create a semantic search engine from completely unlabeled image data. Our method leverages Vision-Language Models (VLMs) to generate descriptions for galaxy images, then contrastively aligns a pre-trained multimodal astronomy foundation model with these embedded descriptions to produce searchable embeddings at scale. We find that current VLMs provide descriptions that are sufficiently informative to train a semantic search model that outperforms direct image similarity search. Our model, AION-Search, achieves state-of-the-art zero-shot performance on finding rare phenomena despite training on randomly selected images with no deliberate curation for rare cases. Furthermore, we introduce a VLM-based re-ranking method that nearly doubles the recall for our most challenging targets in the top-100 results. For the first time, AION-Search enables flexible semantic search scalable to 140 million galaxy images, enabling discovery from previously infeasible searches. More broadly, our work provides an approach for making large, unlabeled scientific image archives semantically searchable, expanding data exploration capabilities in fields from Earth observation to microscopy. The code, data, and app are publicly available at https://github.com/NolanKoblischke/AION-Search
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025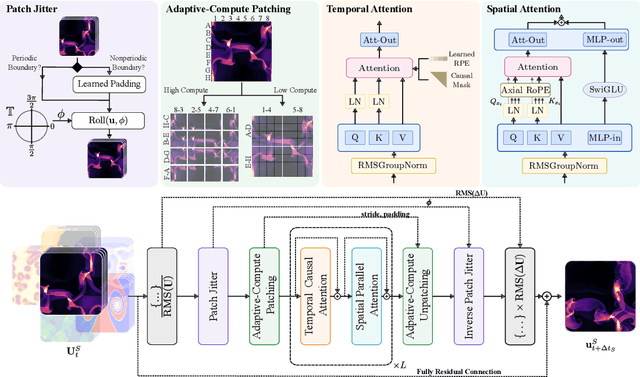


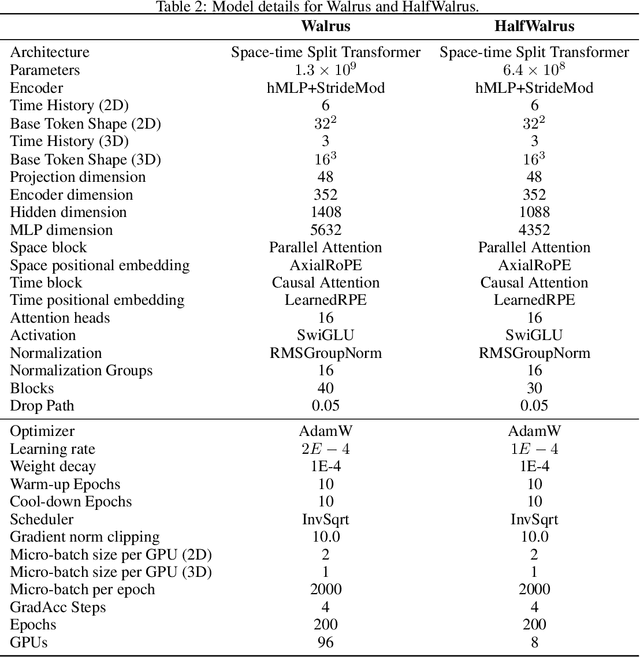
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
Initial Conditions from Galaxies: Machine-Learning Subgrid Correction to Standard Reconstruction
Apr 01, 2025We present a hybrid method for reconstructing the primordial density from late-time halos and galaxies. Our approach involves two steps: (1) apply standard Baryon Acoustic Oscillation (BAO) reconstruction to recover the large-scale features in the primordial density field and (2) train a deep learning model to learn small-scale corrections on partitioned subgrids of the full volume. At inference, this correction is then convolved across the full survey volume, enabling scaling to large survey volumes. We train our method on both mock halo catalogs and mock galaxy catalogs in both configuration and redshift space from the Quijote $1(h^{-1}\,\mathrm{Gpc})^3$ simulation suite. When evaluated on held-out simulations, our combined approach significantly improves the reconstruction cross-correlation coefficient with the true initial density field and remains robust to moderate model misspecification. Additionally, we show that models trained on $1(h^{-1}\,\mathrm{Gpc})^3$ can be applied to larger boxes--e.g., $(3h^{-1}\,\mathrm{Gpc})^3$--without retraining. Finally, we perform a Fisher analysis on our method's recovery of the BAO peak, and find that it significantly improves the error on the acoustic scale relative to standard BAO reconstruction. Ultimately, this method robustly captures nonlinearities and bias without sacrificing large-scale accuracy, and its flexibility to handle arbitrarily large volumes without escalating computational requirements makes it especially promising for large-volume surveys like DESI.
SimBIG: Field-level Simulation-Based Inference of Galaxy Clustering
Oct 23, 2023We present the first simulation-based inference (SBI) of cosmological parameters from field-level analysis of galaxy clustering. Standard galaxy clustering analyses rely on analyzing summary statistics, such as the power spectrum, $P_\ell$, with analytic models based on perturbation theory. Consequently, they do not fully exploit the non-linear and non-Gaussian features of the galaxy distribution. To address these limitations, we use the {\sc SimBIG} forward modelling framework to perform SBI using normalizing flows. We apply SimBIG to a subset of the BOSS CMASS galaxy sample using a convolutional neural network with stochastic weight averaging to perform massive data compression of the galaxy field. We infer constraints on $\Omega_m = 0.267^{+0.033}_{-0.029}$ and $\sigma_8=0.762^{+0.036}_{-0.035}$. While our constraints on $\Omega_m$ are in-line with standard $P_\ell$ analyses, those on $\sigma_8$ are $2.65\times$ tighter. Our analysis also provides constraints on the Hubble constant $H_0=64.5 \pm 3.8 \ {\rm km / s / Mpc}$ from galaxy clustering alone. This higher constraining power comes from additional non-Gaussian cosmological information, inaccessible with $P_\ell$. We demonstrate the robustness of our analysis by showcasing our ability to infer unbiased cosmological constraints from a series of test simulations that are constructed using different forward models than the one used in our training dataset. This work not only presents competitive cosmological constraints but also introduces novel methods for leveraging additional cosmological information in upcoming galaxy surveys like DESI, PFS, and Euclid.
xVal: A Continuous Number Encoding for Large Language Models
Oct 04, 2023Large Language Models have not yet been broadly adapted for the analysis of scientific datasets due in part to the unique difficulties of tokenizing numbers. We propose xVal, a numerical encoding scheme that represents any real number using just a single token. xVal represents a given real number by scaling a dedicated embedding vector by the number value. Combined with a modified number-inference approach, this strategy renders the model end-to-end continuous when considered as a map from the numbers of the input string to those of the output string. This leads to an inductive bias that is generally more suitable for applications in scientific domains. We empirically evaluate our proposal on a number of synthetic and real-world datasets. Compared with existing number encoding schemes, we find that xVal is more token-efficient and demonstrates improved generalization.
AstroCLIP: Cross-Modal Pre-Training for Astronomical Foundation Models
Oct 04, 2023We present AstroCLIP, a strategy to facilitate the construction of astronomical foundation models that bridge the gap between diverse observational modalities. We demonstrate that a cross-modal contrastive learning approach between images and optical spectra of galaxies yields highly informative embeddings of both modalities. In particular, we apply our method on multi-band images and optical spectra from the Dark Energy Spectroscopic Instrument (DESI), and show that: (1) these embeddings are well-aligned between modalities and can be used for accurate cross-modal searches, and (2) these embeddings encode valuable physical information about the galaxies -- in particular redshift and stellar mass -- that can be used to achieve competitive zero- and few- shot predictions without further finetuning. Additionally, in the process of developing our approach, we also construct a novel, transformer-based model and pretraining approach for processing galaxy spectra.
Neural Collapse in the Intermediate Hidden Layers of Classification Neural Networks
Aug 05, 2023
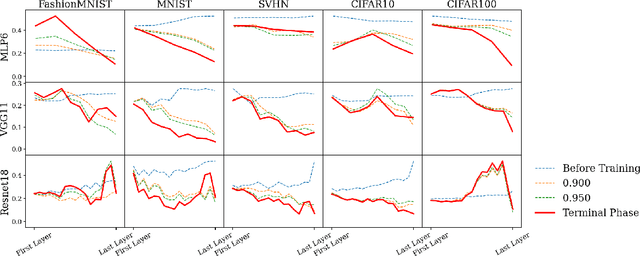

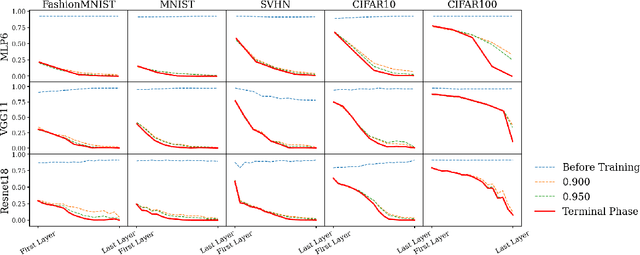
Neural Collapse (NC) gives a precise description of the representations of classes in the final hidden layer of classification neural networks. This description provides insights into how these networks learn features and generalize well when trained past zero training error. However, to date, (NC) has only been studied in the final layer of these networks. In the present paper, we provide the first comprehensive empirical analysis of the emergence of (NC) in the intermediate hidden layers of these classifiers. We examine a variety of network architectures, activations, and datasets, and demonstrate that some degree of (NC) emerges in most of the intermediate hidden layers of the network, where the degree of collapse in any given layer is typically positively correlated with the depth of that layer in the neural network. Moreover, we remark that: (1) almost all of the reduction in intra-class variance in the samples occurs in the shallower layers of the networks, (2) the angular separation between class means increases consistently with hidden layer depth, and (3) simple datasets require only the shallower layers of the networks to fully learn them, whereas more difficult ones require the entire network. Ultimately, these results provide granular insights into the structural propagation of features through classification neural networks.