 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation of Large Language Models
May 06, 2024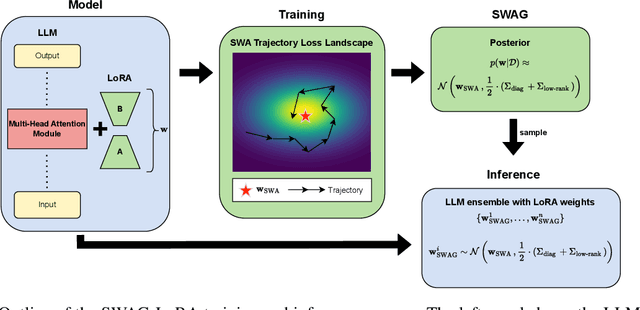
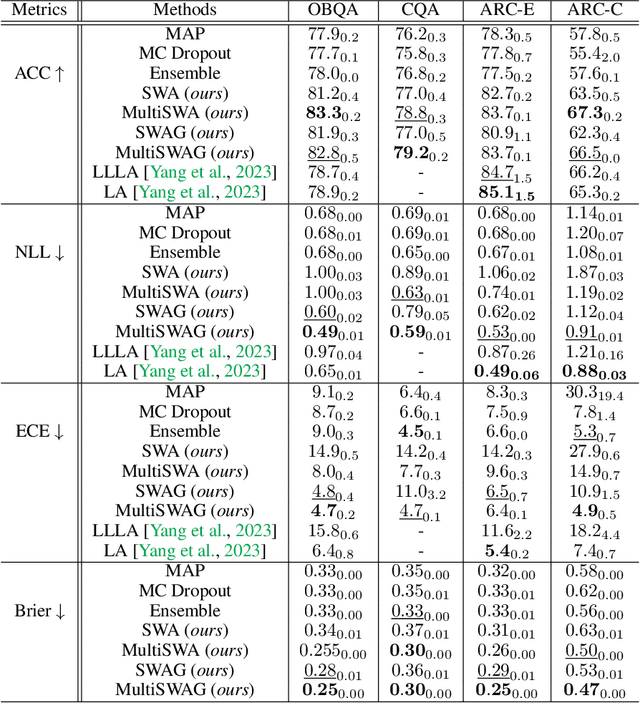
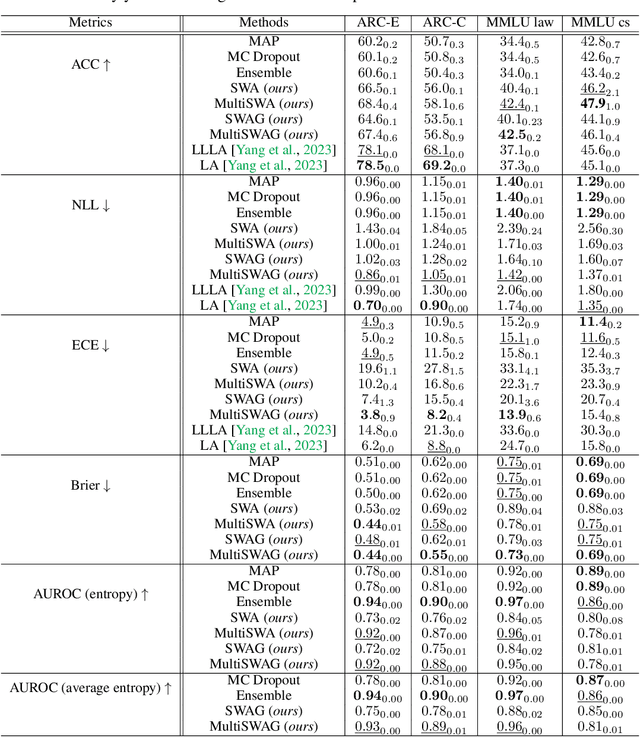
Fine-tuned Large Language Models (LLMs) often suffer from overconfidence and poor calibration, particularly when fine-tuned on small datasets. To address these challenges, we propose a simple combination of Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG), facilitating approximate Bayesian inference in LLMs. Through extensive testing across several Natural Language Processing (NLP) benchmarks, we demonstrate that our straightforward and computationally efficient approach improves model generalization and calibration. We further show that our method exhibits greater robustness against distribution shift, as reflected in its performance on out-of-distribution tasks.
Neural Collapse in the Intermediate Hidden Layers of Classification Neural Networks
Aug 05, 2023
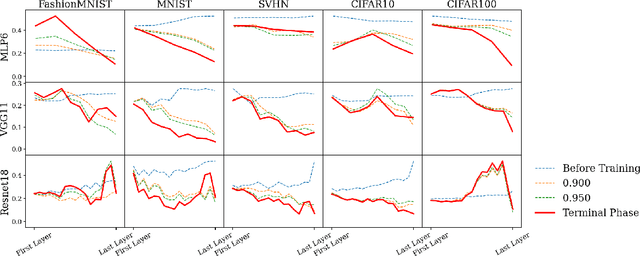

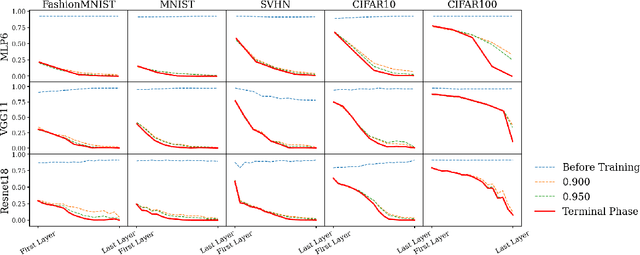
Neural Collapse (NC) gives a precise description of the representations of classes in the final hidden layer of classification neural networks. This description provides insights into how these networks learn features and generalize well when trained past zero training error. However, to date, (NC) has only been studied in the final layer of these networks. In the present paper, we provide the first comprehensive empirical analysis of the emergence of (NC) in the intermediate hidden layers of these classifiers. We examine a variety of network architectures, activations, and datasets, and demonstrate that some degree of (NC) emerges in most of the intermediate hidden layers of the network, where the degree of collapse in any given layer is typically positively correlated with the depth of that layer in the neural network. Moreover, we remark that: (1) almost all of the reduction in intra-class variance in the samples occurs in the shallower layers of the networks, (2) the angular separation between class means increases consistently with hidden layer depth, and (3) simple datasets require only the shallower layers of the networks to fully learn them, whereas more difficult ones require the entire network. Ultimately, these results provide granular insights into the structural propagation of features through classification neural networks.