 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025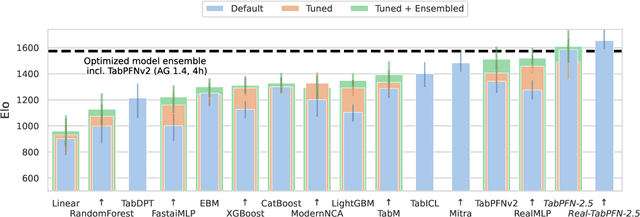
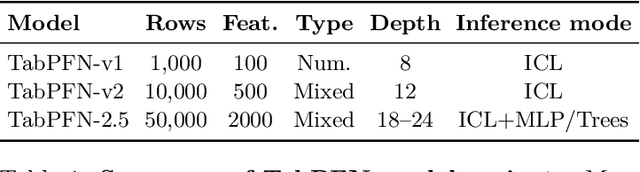
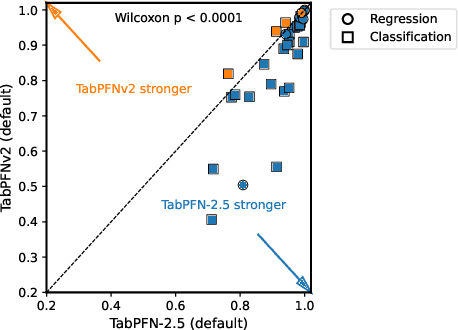
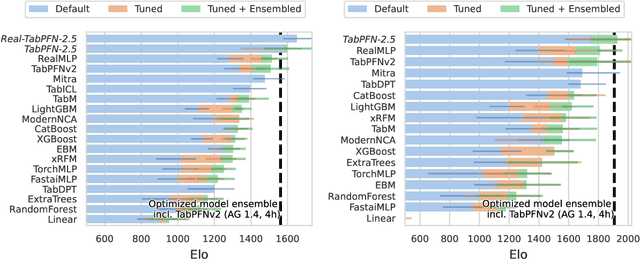
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
OneProt: Towards Multi-Modal Protein Foundation Models
Nov 07, 2024



Recent AI advances have enabled multi-modal systems to model and translate diverse information spaces. Extending beyond text and vision, we introduce OneProt, a multi-modal AI for proteins that integrates structural, sequence, alignment, and binding site data. Using the ImageBind framework, OneProt aligns the latent spaces of modality encoders along protein sequences. It demonstrates strong performance in retrieval tasks and surpasses state-of-the-art methods in various downstream tasks, including metal ion binding classification, gene-ontology annotation, and enzyme function prediction. This work expands multi-modal capabilities in protein models, paving the way for applications in drug discovery, biocatalytic reaction planning, and protein engineering.
Stein Variational Newton Neural Network Ensembles
Nov 04, 2024



Deep neural network ensembles are powerful tools for uncertainty quantification, which have recently been re-interpreted from a Bayesian perspective. However, current methods inadequately leverage second-order information of the loss landscape, despite the recent availability of efficient Hessian approximations. We propose a novel approximate Bayesian inference method that modifies deep ensembles to incorporate Stein Variational Newton updates. Our approach uniquely integrates scalable modern Hessian approximations, achieving faster convergence and more accurate posterior distribution approximations. We validate the effectiveness of our method on diverse regression and classification tasks, demonstrating superior performance with a significantly reduced number of training epochs compared to existing ensemble-based methods, while enhancing uncertainty quantification and robustness against overfitting.
Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Adaptation of Large Language Models
May 06, 2024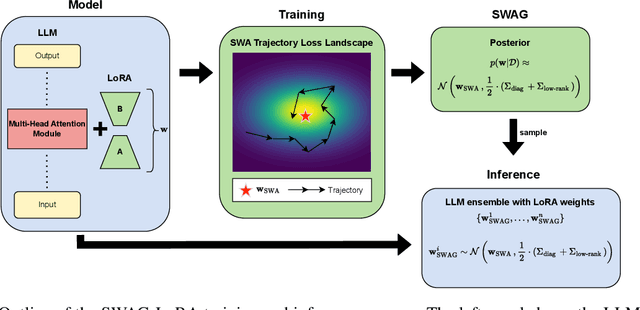
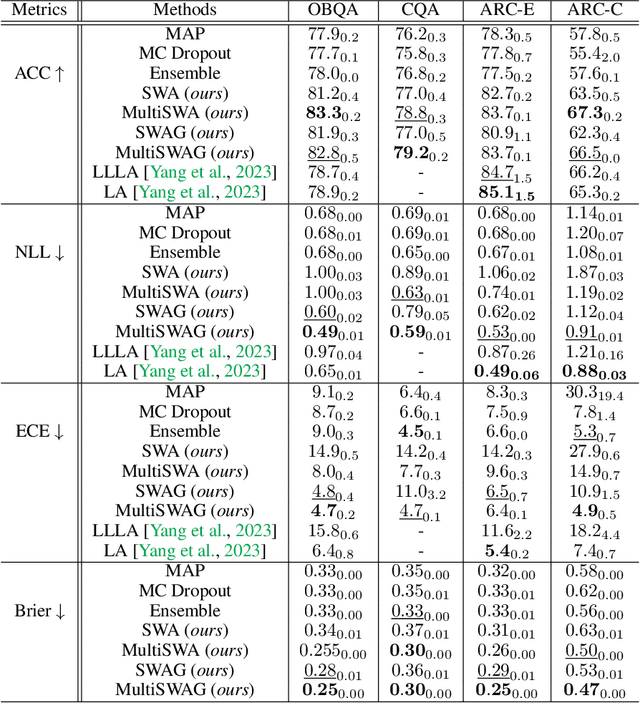
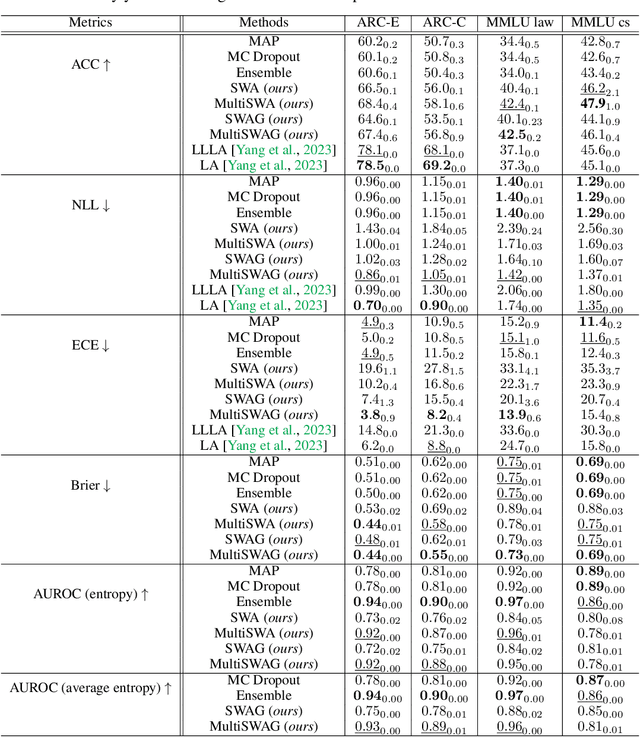
Fine-tuned Large Language Models (LLMs) often suffer from overconfidence and poor calibration, particularly when fine-tuned on small datasets. To address these challenges, we propose a simple combination of Low-Rank Adaptation (LoRA) with Gaussian Stochastic Weight Averaging (SWAG), facilitating approximate Bayesian inference in LLMs. Through extensive testing across several Natural Language Processing (NLP) benchmarks, we demonstrate that our straightforward and computationally efficient approach improves model generalization and calibration. We further show that our method exhibits greater robustness against distribution shift, as reflected in its performance on out-of-distribution tasks.