 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Transfer of a Physics Foundation Model from Simulation to Laboratory Turbulence
May 31, 2026Whether physics foundation models can be usefully deployed on laboratory experiments remains an open question for scientific machine learning (ML). We test this question on the Rayleigh-Taylor instability (RTI), a ubiquitous and demanding fluid instability seen from tabletop flows to supernova explosions, in which small perturbations at a density interface grow into chaotic, multiscale mixing as a lighter fluid accelerates into a heavier one. Standard ML models struggle with RTI, and despite over a century of theoretical, numerical, and experimental work, it carries an unresolved discrepancy between simulation and experiment: the late-time mixing growth rate, $α$, measured in most laboratory experiments ($\sim$ 0.06-0.07), is roughly three times the value from idealized direct numerical simulations (DNS, $\sim$ 0.02). The gap's origin remains debated. These properties make RTI a stringent test for a question that matters well beyond RTI: can foundation models trained only on simulations generalise to sparse, messy, and noisy laboratory settings? We finetune Walrus, a foundation model for continuum dynamics, on three or fewer DNS realizations and recover key RTI physics over long rollouts. Applied zero-shot to sliding-barrier laboratory data, the finetuned model leaves the DNS-like regime and enters the observed growth band, having never seen a single experimental sample. These results provide independent, data-driven evidence that initial conditions play a crucial role in the longstanding sim-experiment gap in $α$. The model also generalises zero-shot to stable stratification, a buoyancy regime absent from training, correctly slowing mixing-layer growth. Together, our results show that foundation models can generalise well beyond their training data, predicting laboratory behavior and unseen physical regimes, opening new ways to probe longstanding simulation-experiment gaps.
MIMIC: A Generative Multimodal Foundation Model for Biomolecules
Apr 27, 2026Biological function emerges from coupled constraints across sequence, structure, regulation, evolution, and cellular context, yet most foundation models in biology are trained within one modality or for a fixed forward task. We present MIMIC, a generative multimodal foundation model trained on our newly curated and aligned dataset, LORE, linking nucleic acid, protein, evolutionary, structural, regulatory, and semantic/contextual modalities within partially observed biomolecular states. MIMIC uses a split-track encoder-decoder architecture to condition on arbitrary subsets of observed modalities and reconstruct or generate missing components of molecular state across the genome, transcriptome, and proteome. Multimodal conditioning consistently improves MIMIC's sequence reconstruction relative to sequence-only inputs, while its learned representations enable state-of-the-art performance on RNA and protein downstream tasks. MIMIC achieves state-of-the-art splicing prediction, and its joint generative formulation enables isoform-aware inference that further improves performance. Beyond prediction, the same generative framework supports constrained design. For RNA, MIMIC identifies corrective edits in a clinically relevant HBB splice-disrupting mutation without reverting it by using evolutionary and structural signals. For proteins, jointly conditioning on shape and surface chemistry of PD-L1 and hACE2 binding sites produces diverse, high-confidence sequences with strong in silico support for target binding. Finally, MIMIC uses experimental context as semantic conditioning to model assay-dependent RNA chemical probing, rather than treating context as a fixed output. Together, these results position MIMIC's aligned multimodal generative modeling as a strong foundation for unifying representation learning, conditional prediction, and constrained biomolecular design within a single model.
Semantic search for 100M+ galaxy images using AI-generated captions
Dec 12, 2025Finding scientifically interesting phenomena through slow, manual labeling campaigns severely limits our ability to explore the billions of galaxy images produced by telescopes. In this work, we develop a pipeline to create a semantic search engine from completely unlabeled image data. Our method leverages Vision-Language Models (VLMs) to generate descriptions for galaxy images, then contrastively aligns a pre-trained multimodal astronomy foundation model with these embedded descriptions to produce searchable embeddings at scale. We find that current VLMs provide descriptions that are sufficiently informative to train a semantic search model that outperforms direct image similarity search. Our model, AION-Search, achieves state-of-the-art zero-shot performance on finding rare phenomena despite training on randomly selected images with no deliberate curation for rare cases. Furthermore, we introduce a VLM-based re-ranking method that nearly doubles the recall for our most challenging targets in the top-100 results. For the first time, AION-Search enables flexible semantic search scalable to 140 million galaxy images, enabling discovery from previously infeasible searches. More broadly, our work provides an approach for making large, unlabeled scientific image archives semantically searchable, expanding data exploration capabilities in fields from Earth observation to microscopy. The code, data, and app are publicly available at https://github.com/NolanKoblischke/AION-Search
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025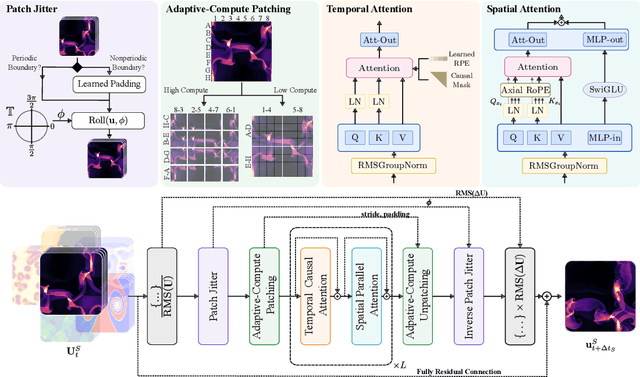


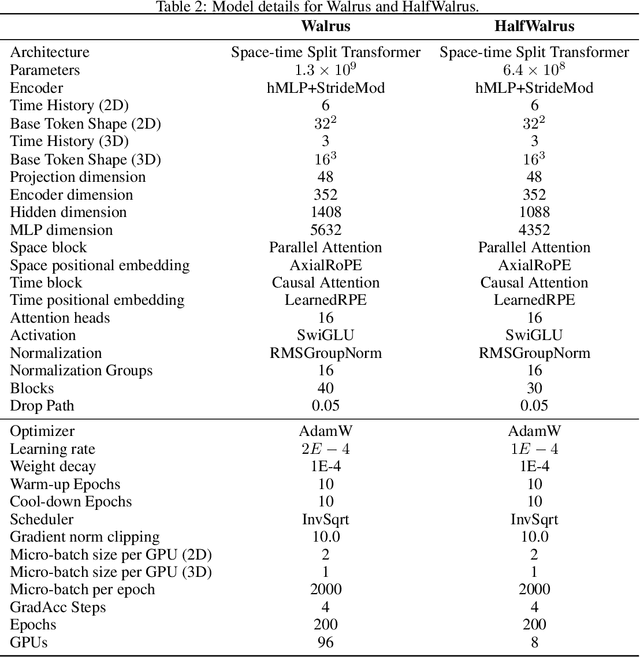
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
Geometric deep learning for galaxy-halo connection: a case study for galaxy intrinsic alignments
Sep 27, 2024Forthcoming cosmological imaging surveys, such as the Rubin Observatory LSST, require large-scale simulations encompassing realistic galaxy populations for a variety of scientific applications. Of particular concern is the phenomenon of intrinsic alignments (IA), whereby galaxies orient themselves towards overdensities, potentially introducing significant systematic biases in weak gravitational lensing analyses if they are not properly modeled. Due to computational constraints, simulating the intricate details of galaxy formation and evolution relevant to IA across vast volumes is impractical. As an alternative, we propose a Deep Generative Model trained on the IllustrisTNG-100 simulation to sample 3D galaxy shapes and orientations to accurately reproduce intrinsic alignments along with correlated scalar features. We model the cosmic web as a set of graphs, each graph representing a halo with nodes representing the subhalos/galaxies. The architecture consists of a SO(3) $\times$ $\mathbb{R}^n$ diffusion generative model, for galaxy orientations and $n$ scalars, implemented with E(3) equivariant Graph Neural Networks that explicitly respect the Euclidean symmetries of our Universe. The model is able to learn and predict features such as galaxy orientations that are statistically consistent with the reference simulation. Notably, our model demonstrates the ability to jointly model Euclidean-valued scalars (galaxy sizes, shapes, and colors) along with non-Euclidean valued SO(3) quantities (galaxy orientations) that are governed by highly complex galactic physics at non-linear scales.
Unified framework for diffusion generative models in SO(3): applications in computer vision and astrophysics
Dec 18, 2023Diffusion-based generative models represent the current state-of-the-art for image generation. However, standard diffusion models are based on Euclidean geometry and do not translate directly to manifold-valued data. In this work, we develop extensions of both score-based generative models (SGMs) and Denoising Diffusion Probabilistic Models (DDPMs) to the Lie group of 3D rotations, SO(3). SO(3) is of particular interest in many disciplines such as robotics, biochemistry and astronomy/cosmology science. Contrary to more general Riemannian manifolds, SO(3) admits a tractable solution to heat diffusion, and allows us to implement efficient training of diffusion models. We apply both SO(3) DDPMs and SGMs to synthetic densities on SO(3) and demonstrate state-of-the-art results. Additionally, we demonstrate the practicality of our model on pose estimation tasks and in predicting correlated galaxy orientations for astrophysics/cosmology.
Multiple Physics Pretraining for Physical Surrogate Models
Oct 04, 2023


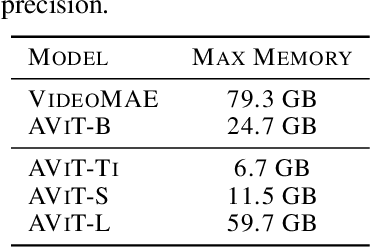
We introduce multiple physics pretraining (MPP), an autoregressive task-agnostic pretraining approach for physical surrogate modeling. MPP involves training large surrogate models to predict the dynamics of multiple heterogeneous physical systems simultaneously by learning features that are broadly useful across diverse physical tasks. In order to learn effectively in this setting, we introduce a shared embedding and normalization strategy that projects the fields of multiple systems into a single shared embedding space. We validate the efficacy of our approach on both pretraining and downstream tasks over a broad fluid mechanics-oriented benchmark. We show that a single MPP-pretrained transformer is able to match or outperform task-specific baselines on all pretraining sub-tasks without the need for finetuning. For downstream tasks, we demonstrate that finetuning MPP-trained models results in more accurate predictions across multiple time-steps on new physics compared to training from scratch or finetuning pretrained video foundation models. We open-source our code and model weights trained at multiple scales for reproducibility and community experimentation.
AstroCLIP: Cross-Modal Pre-Training for Astronomical Foundation Models
Oct 04, 2023We present AstroCLIP, a strategy to facilitate the construction of astronomical foundation models that bridge the gap between diverse observational modalities. We demonstrate that a cross-modal contrastive learning approach between images and optical spectra of galaxies yields highly informative embeddings of both modalities. In particular, we apply our method on multi-band images and optical spectra from the Dark Energy Spectroscopic Instrument (DESI), and show that: (1) these embeddings are well-aligned between modalities and can be used for accurate cross-modal searches, and (2) these embeddings encode valuable physical information about the galaxies -- in particular redshift and stellar mass -- that can be used to achieve competitive zero- and few- shot predictions without further finetuning. Additionally, in the process of developing our approach, we also construct a novel, transformer-based model and pretraining approach for processing galaxy spectra.
xVal: A Continuous Number Encoding for Large Language Models
Oct 04, 2023Large Language Models have not yet been broadly adapted for the analysis of scientific datasets due in part to the unique difficulties of tokenizing numbers. We propose xVal, a numerical encoding scheme that represents any real number using just a single token. xVal represents a given real number by scaling a dedicated embedding vector by the number value. Combined with a modified number-inference approach, this strategy renders the model end-to-end continuous when considered as a map from the numbers of the input string to those of the output string. This leads to an inductive bias that is generally more suitable for applications in scientific domains. We empirically evaluate our proposal on a number of synthetic and real-world datasets. Compared with existing number encoding schemes, we find that xVal is more token-efficient and demonstrates improved generalization.
Towards solving model bias in cosmic shear forward modeling
Oct 28, 2022As the volume and quality of modern galaxy surveys increase, so does the difficulty of measuring the cosmological signal imprinted in galaxy shapes. Weak gravitational lensing sourced by the most massive structures in the Universe generates a slight shearing of galaxy morphologies called cosmic shear, key probe for cosmological models. Modern techniques of shear estimation based on statistics of ellipticity measurements suffer from the fact that the ellipticity is not a well-defined quantity for arbitrary galaxy light profiles, biasing the shear estimation. We show that a hybrid physical and deep learning Hierarchical Bayesian Model, where a generative model captures the galaxy morphology, enables us to recover an unbiased estimate of the shear on realistic galaxies, thus solving the model bias.