 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Test like you Train in Implicit Deep Learning
May 24, 2023



Implicit deep learning has recently gained popularity with applications ranging from meta-learning to Deep Equilibrium Networks (DEQs). In its general formulation, it relies on expressing some components of deep learning pipelines implicitly, typically via a root equation called the inner problem. In practice, the solution of the inner problem is approximated during training with an iterative procedure, usually with a fixed number of inner iterations. During inference, the inner problem needs to be solved with new data. A popular belief is that increasing the number of inner iterations compared to the one used during training yields better performance. In this paper, we question such an assumption and provide a detailed theoretical analysis in a simple setting. We demonstrate that overparametrization plays a key role: increasing the number of iterations at test time cannot improve performance for overparametrized networks. We validate our theory on an array of implicit deep-learning problems. DEQs, which are typically overparametrized, do not benefit from increasing the number of iterations at inference while meta-learning, which is typically not overparametrized, benefits from it.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022
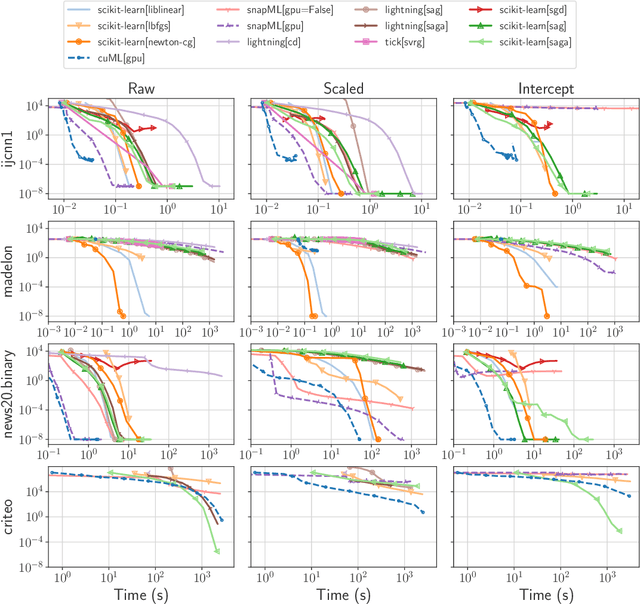
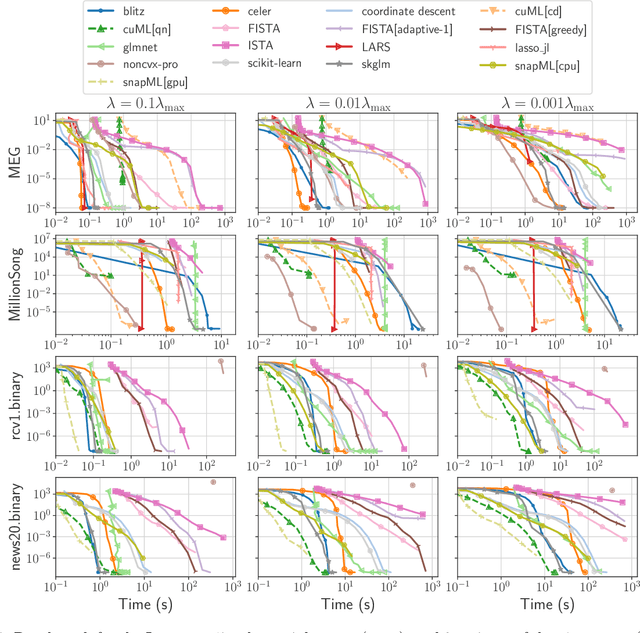
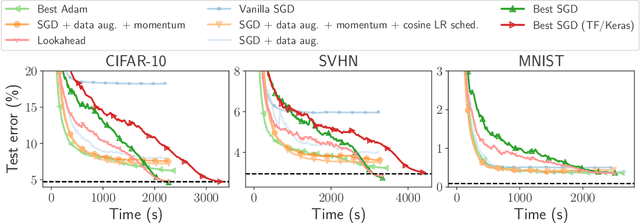
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
Hybrid learning of Non-Cartesian k-space trajectory and MR image reconstruction networks
Oct 25, 2021

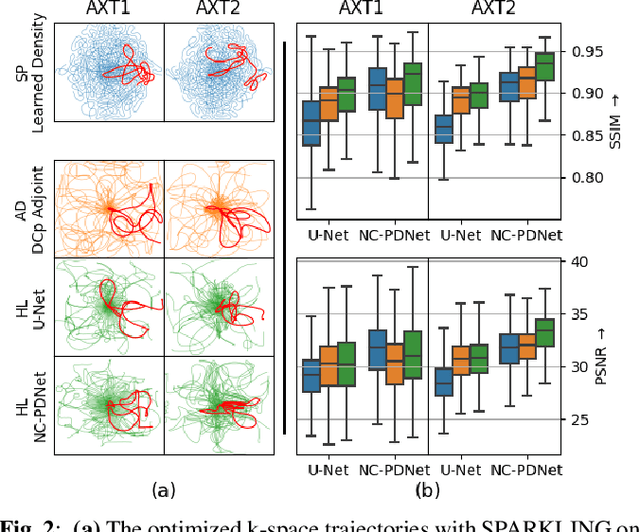
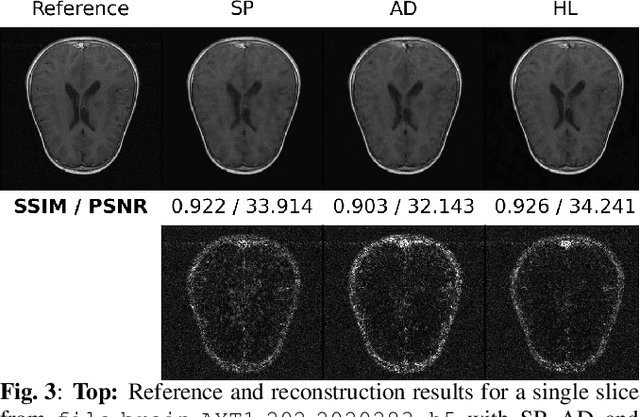
Compressed sensing (CS) in Magnetic resonance Imaging (MRI) essentially involves the optimization of 1) the sampling pattern in k-space under MR hardware constraints and 2) image reconstruction from the undersampled k-space data. Recently, deep learning methods have allowed the community to address both problems simultaneously, especially in the non-Cartesian acquisition setting. This paper aims to contribute to this field by tackling some major concerns in existing approaches.Regarding the learning of the sampling pattern, we perform ablation studies using parameter-free reconstructions like the density compensated (DCp) adjoint operator of the nonuniform fast Fourier transform (NUFFT) to ensure that the learned k-space trajectories actually sample the center of k-space densely. Additionally we optimize these trajectories by embedding a projected gradient descent algorithm over the hardware MR constraints. Later, we introduce a novel hybrid learning approach that operates across multiple resolutions to jointly optimize the reconstruction network and the k-space trajectory and present improved image reconstruction quality at 20-fold acceleration factor on T1 and T2-weighted images on the fastMRI dataset with SSIM scores of nearly 0.92-0.95 in our retrospective studies.
SHINE: SHaring the INverse Estimate from the forward pass for bi-level optimization and implicit models
Jun 24, 2021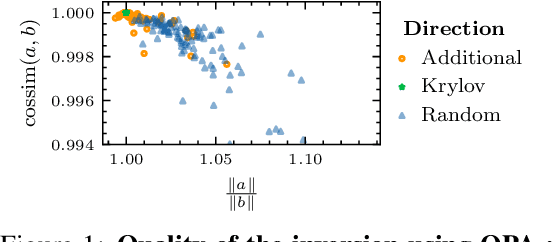
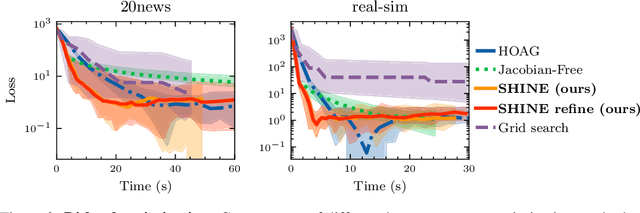
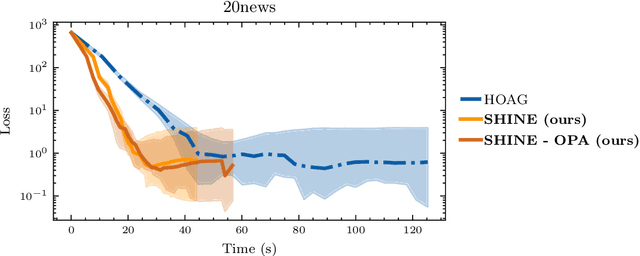
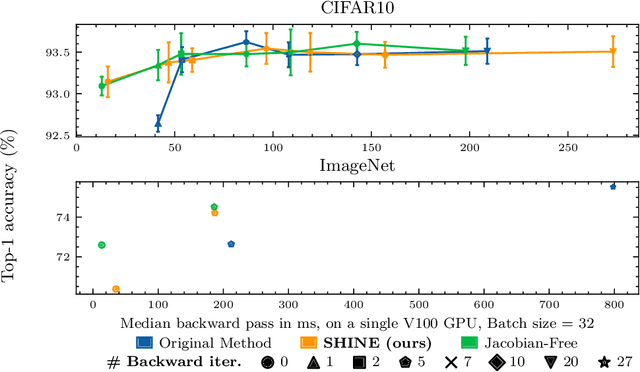
In recent years, implicit deep learning has emerged as a method to increase the depth of deep neural networks. While their training is memory-efficient, they are still significantly slower to train than their explicit counterparts. In Deep Equilibrium Models (DEQs), the training is performed as a bi-level problem, and its computational complexity is partially driven by the iterative inversion of a huge Jacobian matrix. In this paper, we propose a novel strategy to tackle this computational bottleneck from which many bi-level problems suffer. The main idea is to use the quasi-Newton matrices from the forward pass to efficiently approximate the inverse Jacobian matrix in the direction needed for the gradient computation. We provide a theorem that motivates using our method with the original forward algorithms. In addition, by modifying these forward algorithms, we further provide theoretical guarantees that our method asymptotically estimates the true implicit gradient. We empirically study this approach in many settings, ranging from hyperparameter optimization to large Multiscale DEQs applied to CIFAR and ImageNet. We show that it reduces the computational cost of the backward pass by up to two orders of magnitude. All this is achieved while retaining the excellent performance of the original models in hyperparameter optimization and on CIFAR, and giving encouraging and competitive results on ImageNet.
Is good old GRAPPA dead?
Jun 01, 2021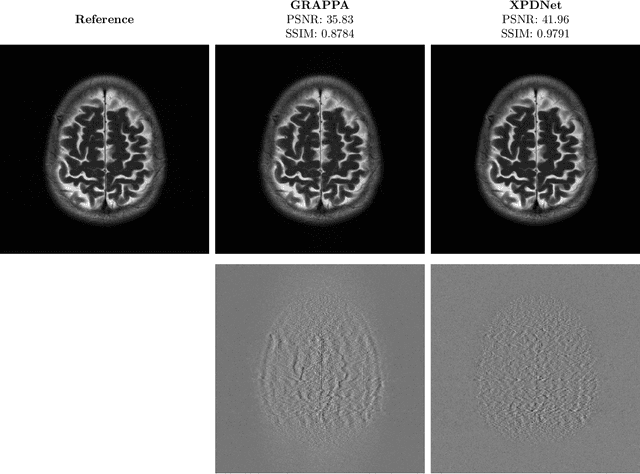
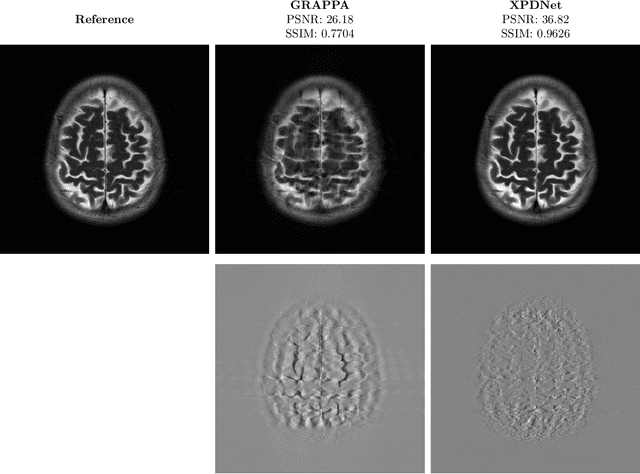
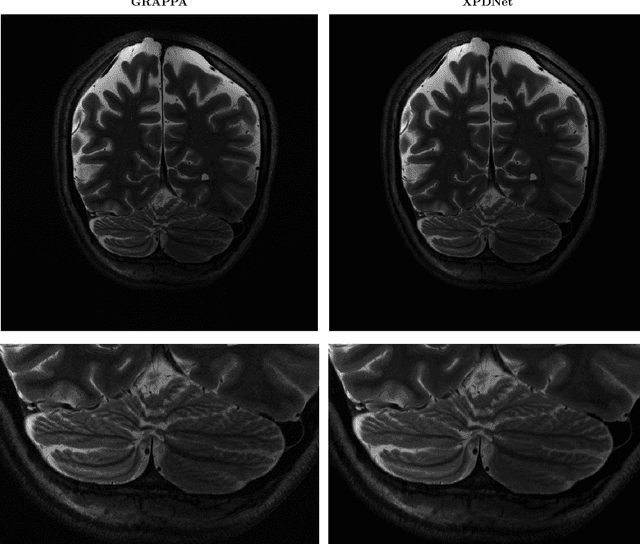

We perform a qualitative analysis of performance of XPDNet, a state-of-the-art deep learning approach for MRI reconstruction, compared to GRAPPA, a classical approach. We do this in multiple settings, in particular testing the robustness of the XPDNet to unseen settings, and show that the XPDNet can to some degree generalize well.
Learning the sampling density in 2D SPARKLING MRI acquisition for optimized image reconstruction
Mar 05, 2021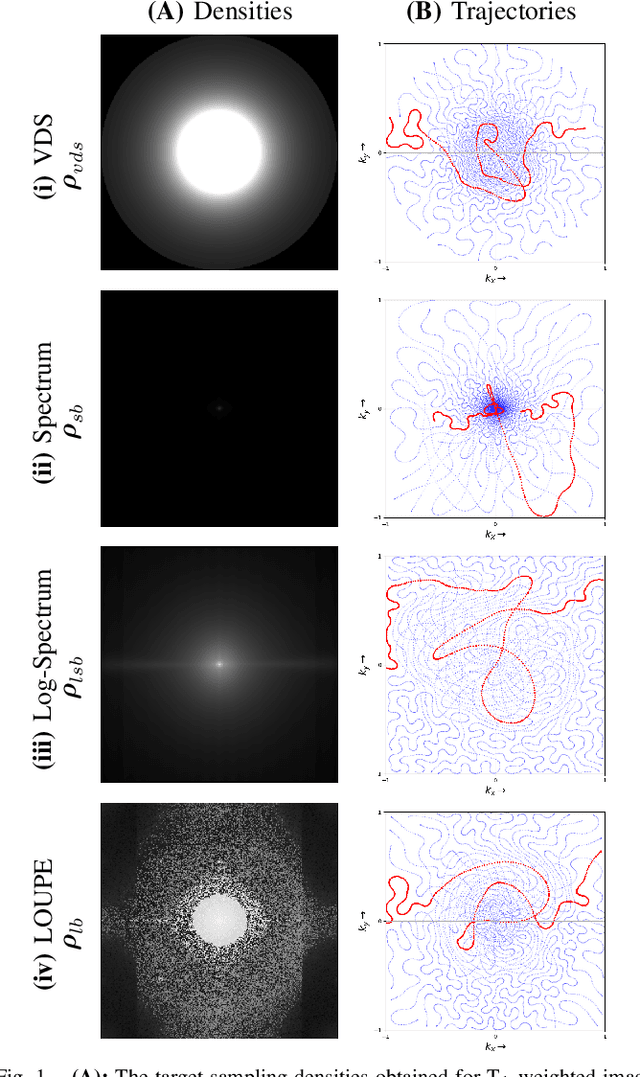
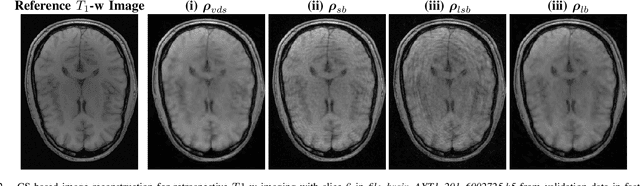
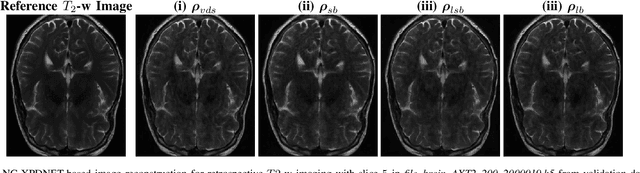
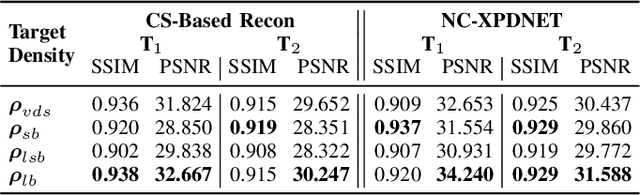
The SPARKLING algorithm was originally developed for accelerated 2D magnetic resonance imaging (MRI) in the compressed sensing (CS) context. It yields non-Cartesian sampling trajectories that jointly fulfill a target sampling density while each individual trajectory complies with MR hardware constraints. However, the two main limitations of SPARKLING are first that the optimal target sampling density is unknown and thus a user-defined parameter and second that this sampling pattern generation remains disconnected from MR image reconstruction thus from the optimization of image quality. Recently, datadriven learning schemes such as LOUPE have been proposed to learn a discrete sampling pattern, by jointly optimizing the whole pipeline from data acquisition to image reconstruction. In this work, we merge these methods with a state-of-the-art deep neural network for image reconstruction, called XPDNET, to learn the optimal target sampling density. Next, this density is used as input parameter to SPARKLING to obtain 20x accelerated non-Cartesian trajectories. These trajectories are tested on retrospective compressed sensing (CS) studies and show superior performance in terms of image quality with both deep learning (DL) and conventional CS reconstruction schemes.
Density Compensated Unrolled Networks for Non-Cartesian MRI Reconstruction
Feb 08, 2021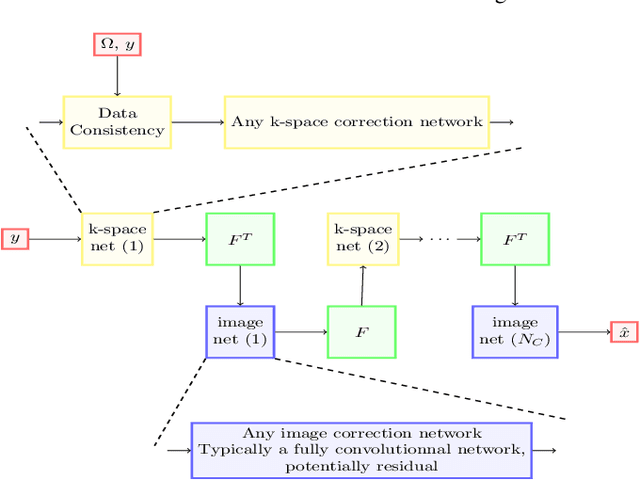
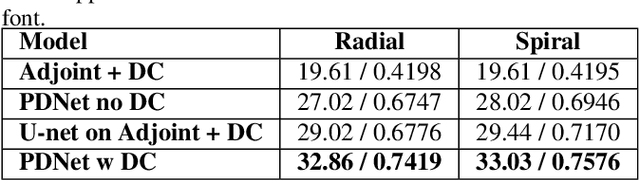

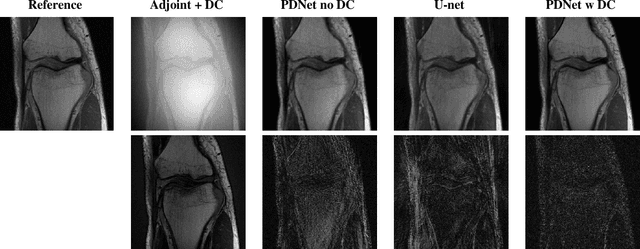
Deep neural networks have recently been thoroughly investigated as a powerful tool for MRI reconstruction. There is a lack of research, however, regarding their use for a specific setting of MRI, namely non-Cartesian acquisitions. In this work, we introduce a novel kind of deep neural networks to tackle this problem, namely density compensated unrolled neural networks, which rely on Density Compensation to correct the uneven weighting of the k-space. We assess their efficiency on the publicly available fastMRI dataset, and perform a small ablation study. Our results show that the density-compensated unrolled neural networks outperform the different baselines, and that all parts of the design are needed. We also open source our code, in particular a Non-Uniform Fast Fourier transform for TensorFlow.