 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs for Knowledge Component-level Correctness Labeling in Open-ended Coding Problems
Feb 19, 2026Fine-grained skill representations, commonly referred to as knowledge components (KCs), are fundamental to many approaches in student modeling and learning analytics. However, KC-level correctness labels are rarely available in real-world datasets, especially for open-ended programming tasks where solutions typically involve multiple KCs simultaneously. Simply propagating problem-level correctness to all associated KCs obscures partial mastery and often leads to poorly fitted learning curves. To address this challenge, we propose an automated framework that leverages large language models (LLMs) to label KC-level correctness directly from student-written code. Our method assesses whether each KC is correctly applied and further introduces a temporal context-aware Code-KC mapping mechanism to better align KCs with individual student code. We evaluate the resulting KC-level correctness labels in terms of learning curve fit and predictive performance using the power law of practice and the Additive Factors Model. Experimental results show that our framework leads to learning curves that are more consistent with cognitive theory and improves predictive performance, compared to baselines. Human evaluation further demonstrates substantial agreement between LLM and expert annotations.
KASER: Knowledge-Aligned Student Error Simulator for Open-Ended Coding Tasks
Jan 10, 2026Open-ended tasks, such as coding problems that are common in computer science education, provide detailed insights into student knowledge. However, training large language models (LLMs) to simulate and predict possible student errors in their responses to these problems can be challenging: they often suffer from mode collapse and fail to fully capture the diversity in syntax, style, and solution approach in student responses. In this work, we present KASER (Knowledge-Aligned Student Error Simulator), a novel approach that aligns errors with student knowledge. We propose a training method based on reinforcement learning using a hybrid reward that reflects three aspects of student code prediction: i) code similarity to the ground-truth, ii) error matching, and iii) code prediction diversity. On two real-world datasets, we perform two levels of evaluation and show that: At the per-student-problem pair level, our method outperforms baselines on code and error prediction; at the per-problem level, our method outperforms baselines on error coverage and simulated code diversity.
Multilingualism, Transnationality, and K-pop in the Online #StopAsianHate Movement
Mar 04, 2025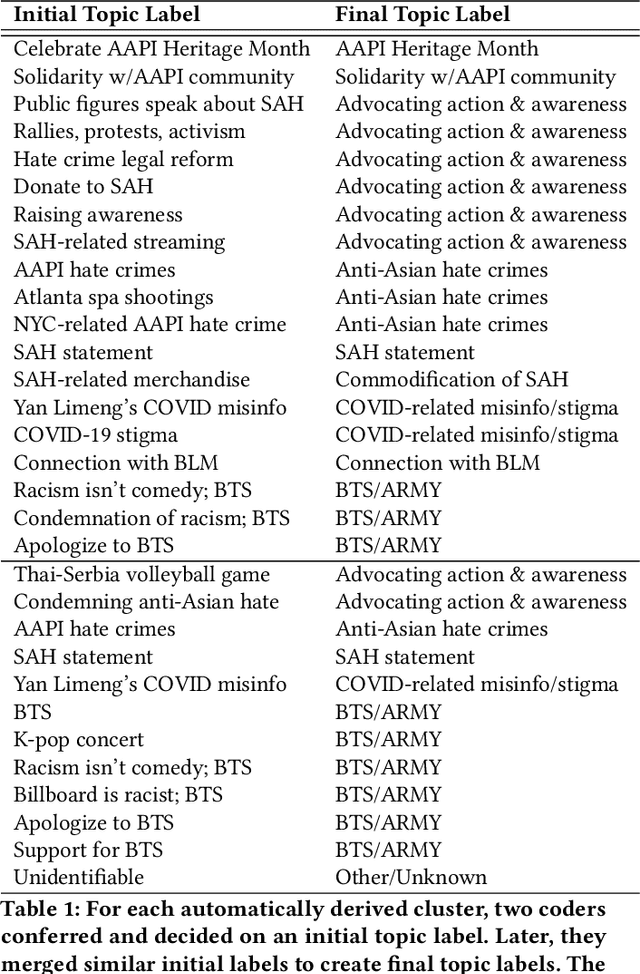
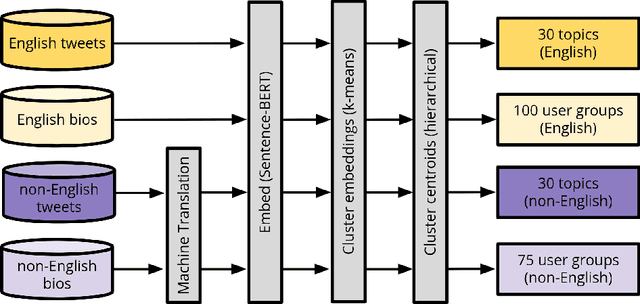

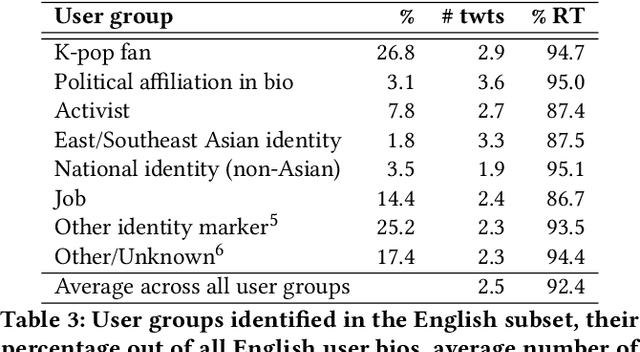
The #StopAsianHate (SAH) movement is a broad social movement against violence targeting Asians and Asian Americans, beginning in 2021 in response to racial discrimination related to COVID-19 and sparking worldwide conversation about anti-Asian hate. However, research on the online SAH movement has focused on English-speaking participants so the spread of the movement outside of the United States is largely unknown. In addition, there have been no long-term studies of SAH so the extent to which it has been successfully sustained over time is not well understood. We present an analysis of 6.5 million "#StopAsianHate" tweets from 2.2 million users all over the globe and spanning 60 different languages, constituting the first study of the non-English and transnational component of the online SAH movement. Using a combination of topic modeling, user modeling, and hand annotation, we identify and characterize the dominant discussions and users participating in the movement and draw comparisons of English versus non-English topics and users. We discover clear differences in events driving topics, where spikes in English tweets are driven by violent crimes in the US but spikes in non-English tweets are driven by transnational incidents of anti-Asian sentiment towards symbolic representatives of Asian nations. We also find that global K-pop fans were quick to adopt the SAH movement and, in fact, sustained it for longer than any other user group. Our work contributes to understanding the transnationality and evolution of the SAH movement, and more generally to exploring upward scale shift and public attention in large-scale multilingual online activism.
Automated Knowledge Component Generation and Knowledge Tracing for Coding Problems
Feb 25, 2025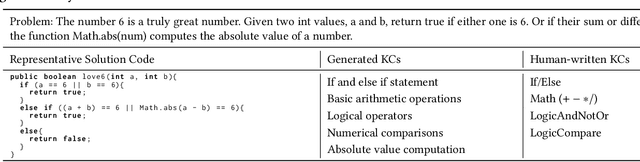
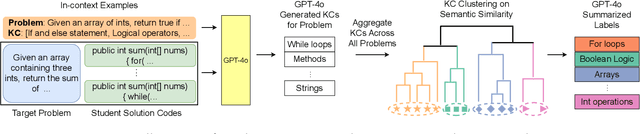
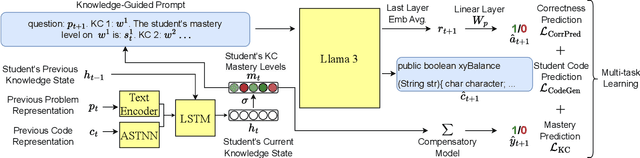
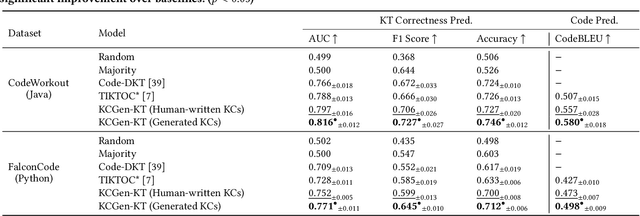
Knowledge components (KCs) mapped to problems help model student learning, tracking their mastery levels on fine-grained skills thereby facilitating personalized learning and feedback in online learning platforms. However, crafting and tagging KCs to problems, traditionally performed by human domain experts, is highly labor-intensive. We present a fully automated, LLM-based pipeline for KC generation and tagging for open-ended programming problems. We also develop an LLM-based knowledge tracing (KT) framework to leverage these LLM-generated KCs, which we refer to as KCGen-KT. We conduct extensive quantitative and qualitative evaluations validating the effectiveness of KCGen-KT. On a real-world dataset of student code submissions to open-ended programming problems, KCGen-KT outperforms existing KT methods. We investigate the learning curves of generated KCs and show that LLM-generated KCs have a comparable level-of-fit to human-written KCs under the performance factor analysis (PFA) model. We also conduct a human evaluation to show that the KC tagging accuracy of our pipeline is reasonably accurate when compared to that by human domain experts.
README: Bridging Medical Jargon and Lay Understanding for Patient Education through Data-Centric NLP
Dec 24, 2023



The advancement in healthcare has shifted focus toward patient-centric approaches, particularly in self-care and patient education, facilitated by access to Electronic Health Records (EHR). However, medical jargon in EHRs poses significant challenges in patient comprehension. To address this, we introduce a new task of automatically generating lay definitions, aiming to simplify complex medical terms into patient-friendly lay language. We first created the README dataset, an extensive collection of over 20,000 unique medical terms and 300,000 mentions, each offering context-aware lay definitions manually annotated by domain experts. We have also engineered a data-centric Human-AI pipeline that synergizes data filtering, augmentation, and selection to improve data quality. We then used README as the training data for models and leveraged a Retrieval-Augmented Generation (RAG) method to reduce hallucinations and improve the quality of model outputs. Our extensive automatic and human evaluations demonstrate that open-source mobile-friendly models, when fine-tuned with high-quality data, are capable of matching or even surpassing the performance of state-of-the-art closed-source large language models like ChatGPT. This research represents a significant stride in closing the knowledge gap in patient education and advancing patient-centric healthcare solutions
Agent Performing Autonomous Stock Trading under Good and Bad Situations
Jun 06, 2023



Stock trading is one of the popular ways for financial management. However, the market and the environment of economy is unstable and usually not predictable. Furthermore, engaging in stock trading requires time and effort to analyze, create strategies, and make decisions. It would be convenient and effective if an agent could assist or even do the task of analyzing and modeling the past data and then generate a strategy for autonomous trading. Recently, reinforcement learning has been shown to be robust in various tasks that involve achieving a goal with a decision making strategy based on time-series data. In this project, we have developed a pipeline that simulates the stock trading environment and have trained an agent to automate the stock trading process with deep reinforcement learning methods, including deep Q-learning, deep SARSA, and the policy gradient method. We evaluate our platform during relatively good (before 2021) and bad (2021 - 2022) situations. The stocks we've evaluated on including Google, Apple, Tesla, Meta, Microsoft, and IBM. These stocks are among the popular ones, and the changes in trends are representative in terms of having good and bad situations. We showed that before 2021, the three reinforcement methods we have tried always provide promising profit returns with total annual rates around $70\%$ to $90\%$, while maintain a positive profit return after 2021 with total annual rates around 2% to 7%.