 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingualism, Transnationality, and K-pop in the Online #StopAsianHate Movement
Mar 04, 2025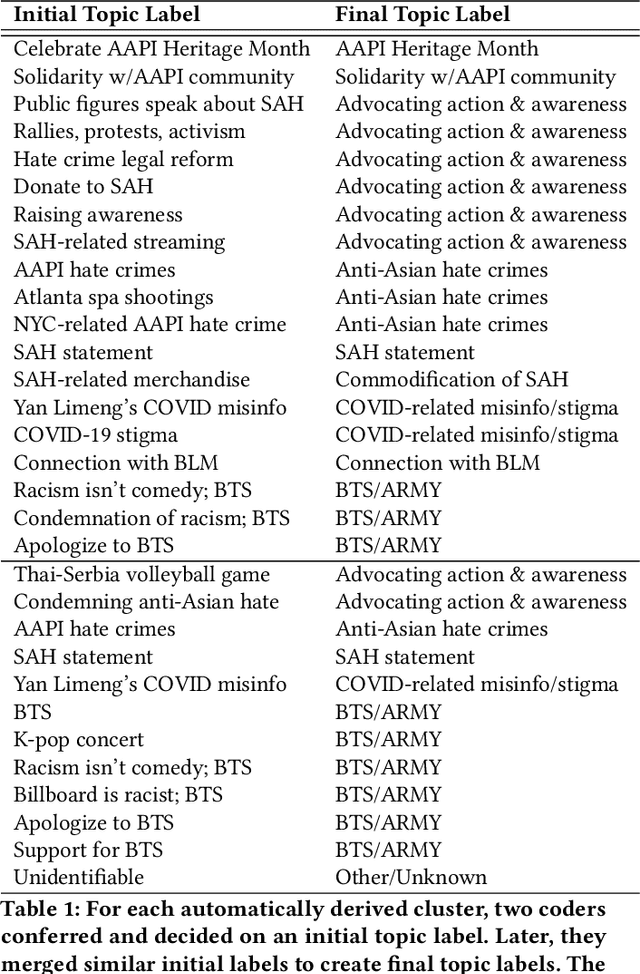
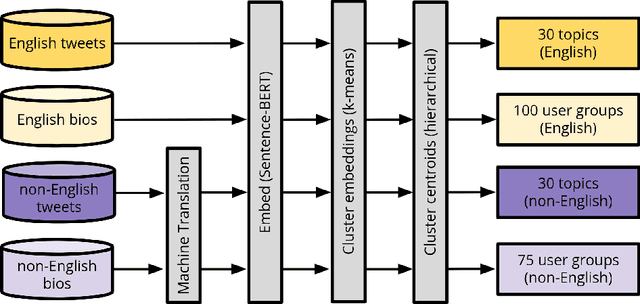

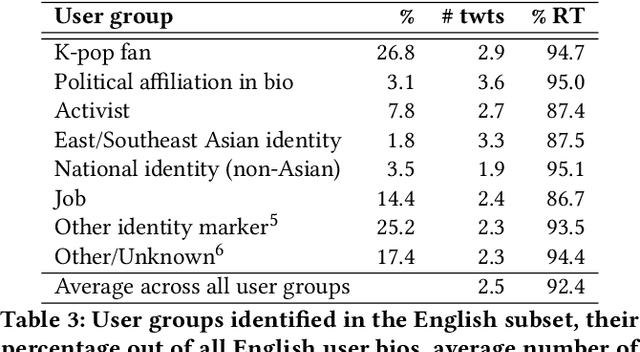
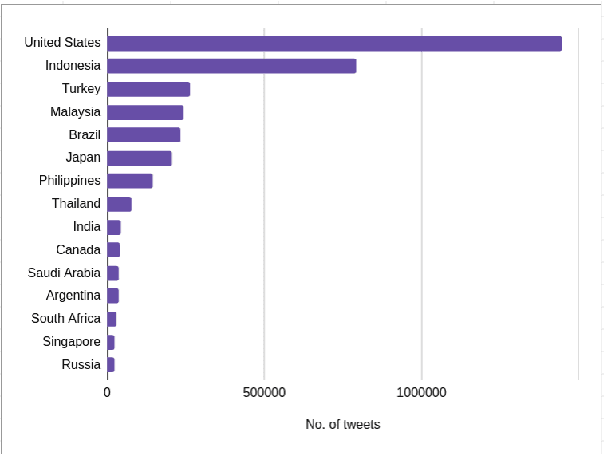
The #StopAsianHate (SAH) movement is a broad social movement against violence targeting Asians and Asian Americans, beginning in 2021 in response to racial discrimination related to COVID-19 and sparking worldwide conversation about anti-Asian hate. However, research on the online SAH movement has focused on English-speaking participants so the spread of the movement outside of the United States is largely unknown. In addition, there have been no long-term studies of SAH so the extent to which it has been successfully sustained over time is not well understood. We present an analysis of 6.5 million "#StopAsianHate" tweets from 2.2 million users all over the globe and spanning 60 different languages, constituting the first study of the non-English and transnational component of the online SAH movement. Using a combination of topic modeling, user modeling, and hand annotation, we identify and characterize the dominant discussions and users participating in the movement and draw comparisons of English versus non-English topics and users. We discover clear differences in events driving topics, where spikes in English tweets are driven by violent crimes in the US but spikes in non-English tweets are driven by transnational incidents of anti-Asian sentiment towards symbolic representatives of Asian nations. We also find that global K-pop fans were quick to adopt the SAH movement and, in fact, sustained it for longer than any other user group. Our work contributes to understanding the transnationality and evolution of the SAH movement, and more generally to exploring upward scale shift and public attention in large-scale multilingual online activism.
Where on Earth Do Users Say They Are?: Geo-Entity Linking for Noisy Multilingual User Input
Apr 29, 2024

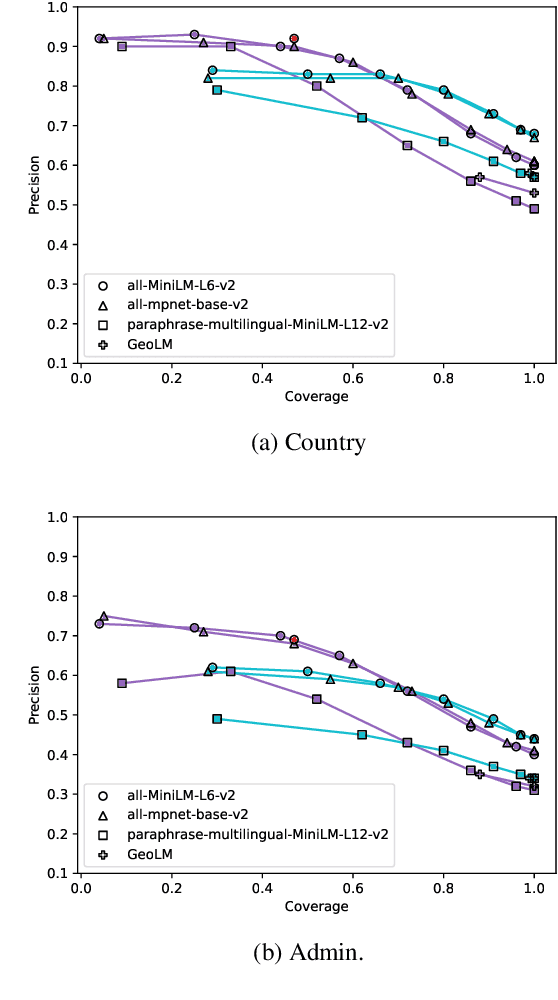
Geo-entity linking is the task of linking a location mention to the real-world geographic location. In this paper we explore the challenging task of geo-entity linking for noisy, multilingual social media data. There are few open-source multilingual geo-entity linking tools available and existing ones are often rule-based, which break easily in social media settings, or LLM-based, which are too expensive for large-scale datasets. We present a method which represents real-world locations as averaged embeddings from labeled user-input location names and allows for selective prediction via an interpretable confidence score. We show that our approach improves geo-entity linking on a global and multilingual social media dataset, and discuss progress and problems with evaluating at different geographic granularities.
Corpus-Guided Contrast Sets for Morphosyntactic Feature Detection in Low-Resource English Varieties
Sep 15, 2022
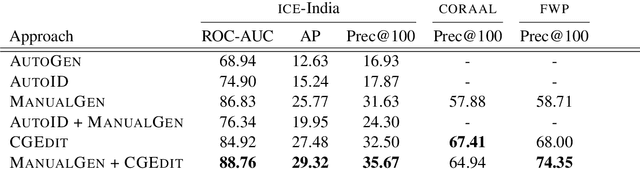


The study of language variation examines how language varies between and within different groups of speakers, shedding light on how we use language to construct identities and how social contexts affect language use. A common method is to identify instances of a certain linguistic feature - say, the zero copula construction - in a corpus, and analyze the feature's distribution across speakers, topics, and other variables, to either gain a qualitative understanding of the feature's function or systematically measure variation. In this paper, we explore the challenging task of automatic morphosyntactic feature detection in low-resource English varieties. We present a human-in-the-loop approach to generate and filter effective contrast sets via corpus-guided edits. We show that our approach improves feature detection for both Indian English and African American English, demonstrate how it can assist linguistic research, and release our fine-tuned models for use by other researchers.